

近一个多世纪以来气候变暖,冰冻圈萎缩引起的冰川消融、冻土退化等问题日趋严峻,极端冰雪灾害呈显著增加趋势及其关联的水灾害频发[1],给社会经济发展及人民生活带来了巨大影响。高寒山区水资源变化直接影响到河川径流乃至全球尺度水循环、水资源及水平衡[2-3]。中国高寒山区主要分布在青藏高原,作为全球气候变化的驱动器和放大器[4],同时孕育着亚洲几大主要河流[5]。金沙江上游位于青藏高原和横断山脉区域,流域面积大,水文、气候、下垫面复杂。历史数据短缺和站点分布稀疏导致基于物理过程的水文模型难以准确模拟流量过程。2018—2019年,金沙江上游春冬季积雪异常偏多,春季径流出现异常,给库群调度、水资源管理带来了影响,现有在大区域的高寒山区径流模拟研究不充分[6-7],无法给相关部门提供科学的决策,在大区域高寒山区开发出精准径流模拟模型有着迫切的需要。
准确可靠的径流模拟对洪水预警以及水资源有效管理有着重要的意义[8-9]。近10年来,关于径流模拟的研究层出不穷[10-11],主要分为基于物理的水文模型和数据驱动模型[12-13]。水文模型可以有效捕捉水文物理过程,但通常需要大量的数据,计算费用昂贵且耗时长,具有一定的局限性[14⇓-16]。水文数据驱动模型不需要了解流域特殊的水文机理,从数据层面能够直接挖掘输入因子与径流之间的非线性关系[17]。机器学习模型是数据驱动模型的一种,在研究区资料稀缺情况下模拟能力更强,在径流模拟研究中得到了广泛的应用[18]。对于中长期径流模拟而言,传统的水文模型需要获取未来较长时间可靠的关键气象要素数据,在实际应用中获取可靠准确的未来数据面临着很大挑战,导致水文模型对未来径流形势模拟效果欠佳。机器学习模型因其无严苛的数据要求及灵活的数据驱动方式,能够有效避免水文物理模型未来模拟面临的窘境[19]。
机器学习进行水文模拟是研究热点,属于前沿交叉学科研究[20]。近年来机器学习水文模拟主要基于人工神经网络(ANN)[21⇓⇓-24]、支持向量机(SVM)[25⇓-27]等构建模型。ANN、SVM模型具备非线性拟合优势,能够有效捕捉水文气象数据之间的非线性关系[28-29],相较于线性回归模型(LRM)在水文模拟方面有着巨大的优势。随着人工智能(AI)的发展以及海量数据的积累,深度学习在交叉领域研究发展迅猛。循环神经网络(RNN)属于深度学习范畴,在时间序列数据模拟上有着优秀的表现,但其也有着局限性,往往在反向传播过程中出现梯度消失。长短期记忆循环神经网络(LSTM)作为RNN的变种,可以有效解决梯度消失问题[30]。相较于商业运用,LSTM在学术领域尤其是水文领域运用较少[31],近几年才有着增长趋势。Hunt等[32]首次将LSTM模型用于混合系统的中期预报且效果优于基于物理的模型。Feng等[33]将基于数据融合的LSTM模型应用在大尺度径流模拟中,发现该模型大大降低了美国以地下水为主的西部流域基流偏差并提高了以动态地表水为主的流域径流峰值模拟。Ma等[34]针对水文气象站点稀少、分布不均、无法获取大量数据的研究现状,利用迁移模型有效提升了缺失资料条件下的径流预测。此外,诸多研究采用最新发布的格点数据驱动模型,发现这些格点数据驱动模型在不同时间分辨率的径流模拟中均有很好的表现[35]。
尽管LSTM神经网络模型在水文模拟上已有成功的应用,但之前研究大多局限于中小流域,没有考虑海拔差异带来影响[36-37],在流域面积大、海拔差异明显的高寒山区研究不足。因该研究区海拔差异显著,考虑气象要素随海拔变化带来的信息增益有利于进一步构建精准的模型。本文以LSTM深度神经网络作为建模基础,由于研究区常年受积雪的影响,引入积雪面积作为主要输入驱动因子,构建考虑海拔差异的高程信息模型(高程分带数据驱动);依据研究区高差及海拔分布,以划分8个高程带提取的数据作为驱动进行高程信息模型构建,同时构建集合模型(流域数据驱动)作为对照模型;通过模型对比发掘最佳预见期模型,并探究其在春汛、夏汛以及极端洪水事件的模拟能力,挖掘高程信息模型潜在的应用。
本文将回答以下问题:① 合理设置参数、结构的LSTM模型不同时间尺度的模拟表现;② 以高程分带数据为驱动的高程信息模型相较于集合模型的优势期及其在径流过程模拟中优势的体现;③ 最佳预见期模型相较于集合模型在汛期和极端洪水事件具体表现;④ 高程信息模型潜在的应用。
1 研究区域概况
1.1 地理位置及特征
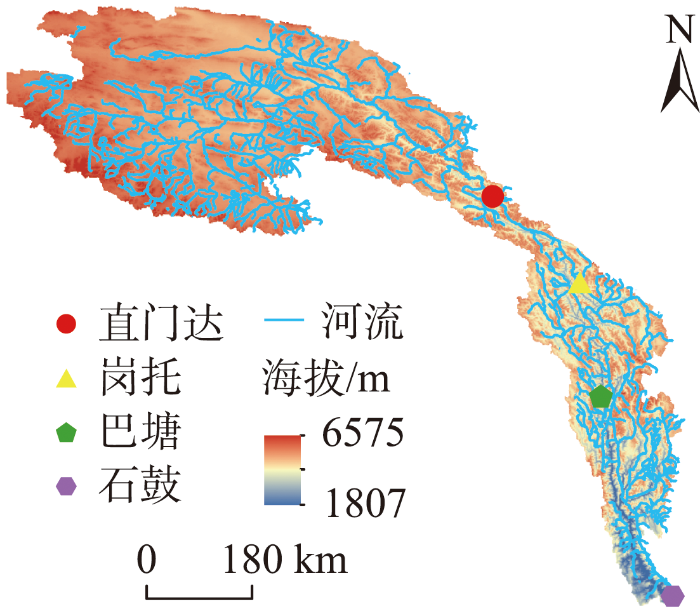
金沙江流域位于中国青藏高原、云贵高原和四川盆地的西部边缘,是长江的上游河段。金沙江全长3486 km,约占长江全程的55%;流域面积 473240 km2,约占长江流域面积的26%。石鼓以上为金沙江上段,石鼓至攀枝花为金沙江中段,攀枝花至宜宾为金沙江下段。作为中国重要的水电开发河段,其已建和在建水电站共20座。
金沙江上游流域概况如图1所示。直门达以上河流由西向东流,山顶终年积雪,多雪山冰川。直门达至石鼓,金沙江进入横断山褶皱带,流域呈狭长的南北带状,河流穿行于高山狭谷之中,水流湍急,流速大。研究区地处青藏高原东南及横断山脉北部,地理坐标介于27°N~36°N、90°E~100°E,流域地势表现为北高南低,总面积为214184 km2,最高海拔6575 m(位于直门达以上),最低海拔为1807 m(位于石鼓、岗托之间)。
图1
1.2 气候水文特征
金沙江上游流域地处青藏高原,受高原季风气候和副热带季风气候影响显著,海拔差异大具有垂直气候特征。因其地势高,一定程度阻挡了水汽进入,导致该流域降水稀少。通过流域近20年气温、降水数据统计,流域多年平均降水量约350~555 mm,降水呈西北向东南递增趋势,流域多年平均气温为-7.8~3.5 ℃。对流域气温和降水进行MK(Mann-Kendall)和SS(Sen's slope)检验发现,近年来春夏季气温呈缓慢上升趋势,冬季有降低趋势,流域四季降水均呈增加趋势。冬季气温降低及降水增加使得冬季产生了更多的积雪,来年春季温度升高促进积雪融化,同期春季降水微量增加,使得春季径流较往常有增多趋势。
流域主河道共4个全年观测水文站,如图1所示,自上游至下游分别为直门达、岗托、巴塘和石鼓,各水文站控制流域面积分别占总流域面积的64.4%、5.3%、14.7%、15.6%。直门达、岗托、巴塘和石鼓夏秋季流量占比分别为85%、82%、81%、78%。大径流量主要集中在6—10月,分别占全年的81%、77%、76%、72%,占比从上游非丰沛区至下游丰沛区逐渐减少。流域日径流量有着明显的年际周期规律及年内四季变化,夏季流量和秋季流量明显高于春季和冬季流量,洪水期主要发生在夏季和秋季初,洪水极值出现在夏季,春冬季径流量小且平稳,夏秋季径流量大且变化大。直门达以上是流域冰冻圈主要分布区,直门达以下河段河谷窄—宽—窄交替出现,多年平均积雪覆盖占整个流域的74%,决定着流域的积雪覆盖情况。
2 数据和方法
2.1 研究数据与预处理
计算机处理技术与遥感卫星的发展和再分析数据的广泛应用,使得在缺乏实测数据的高寒山区有了另一种选择,弥补了高寒山区观测数据的缺陷。本文采用数据包括:90 m分辨率的SRTM DEM数据(NASA CGIAR
以上原始数据需要经过初步加工处理,以满足高程信息模型与集合模型的输入输出数据要求。通过SRTM数字高程模型提取以石鼓为断点的流域边界。流域海拔落差约4700 m,气象积雪等因素具有明显海拔差异,为减少海拔差异带来的模型误差,结合所提取的流域边界与DEM数字高程模型,依据500 m一个高程分布带,提取相应高程带,最终划分为8个高程带。对中国MODIS逐日无云500 m积雪面积数据进行坐标、格式转换。将逐小时的ERA5Land气温数据以及0.5 h GPM降水数据进行时区和单位转换处理为逐日数据。高程信息模型输入数据按照相应8个高程带求和提取相应积雪面积数据,求均得气温、降水数据。集合模型积雪面积依据整个流域求和取得,气温、降水根据区域平均求得。径流数据为石鼓水文站逐小时观测流量,对径流量进行逐日求均,并将少量缺失的观测数据进行插值处理。
对处理得到的逐日气温、降水和积雪面积数据进行标准化以消除数据量纲差异并提高模型精度。公式如下:
式中:
经过上述数据初步处理,高程信息模型与集合模型的气温、降水、积雪面积输入与输出因子如表1所示。
表1 模型输入输出因子
Tab.1
| 数据 模型 | 气温/℃ | 降水/mm | 积雪面积/km2 | 流量/(m3/s) |
|---|---|---|---|---|
| (ERA5Land) | (GPM) | (MODIS) | (石鼓站) | |
| 高程 信息 模型 | 气温2500 m以下 | 降水2500 m以下 | 积雪2500 m以下 | 观测流量 |
| 气温2500~3000 m | 降水2500~3000 m | 积雪2500~3000 m | ||
| 气温3001~3500 m | 降水3001~3500 m | 积雪3001~3500 m | ||
| 气温3501~4000 m | 降水3501~4000 m | 积雪3501~4000 m | ||
| 气温4001~4500 m | 降水4001~4500 m | 积雪4001~4500 m | ||
| 气温4501~5000 m | 降水4501~5000 m | 积雪4501~5000 m | ||
| 气温5001~5500 m | 降水5001~5500 m | 积雪5001~5000 m | ||
| 气温5500 m以上 | 降水5500 m以上 | 积雪5500 m以上 | ||
| 集合模型 | 流域气温 | 流域降水 | 流域积雪 |
2.2 模型原理与参数设置
2.2.1 LSTM循环神经网络
图2
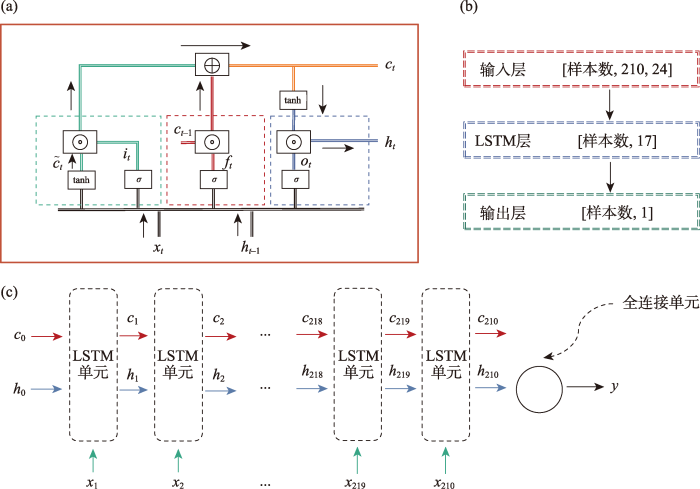
图2
(a) LSTM内部结构、(b) 模型中数据结构和 (c) 本文搭建的模型结构
Fig.2
The internal structure of the long short-term memory (LSTM) model (a), the structure of the data in the model (b), and the structure of the model built in this study (c)
其中,除去记忆单元
式中:
遗忘单元得到的
2.2.2 模型参数设置
经过多次模型调参实验,将Batchsize设置为1000,学习率初始值设置为0.01,迭代次数设置为200,使用L2正则化避免模型过拟合并设置模型收敛时提前结束训练。采用广泛用于机器学习模型优化的MSE(均方误差)[43]作为损失函数。
式中:
为研究模型在未来短中长期模拟效果以及海拔差异的影响,分别设计模拟未来1、3、5、7、9、11、13、15、25和30 d径流量的实验。模型的输入输出结构如图3所示。
图3

图3
不同预见期模型输入输出示意图
Fig.3
Schematic diagram of model input and output for different lead times
2.3 模型精度评价
(1) 相关系数R
(2) 纳什效率系数NSE
(3) 均方根误差RMSE
式中:
3 结果分析
3.1 集合模型不同未来预见期表现
图4
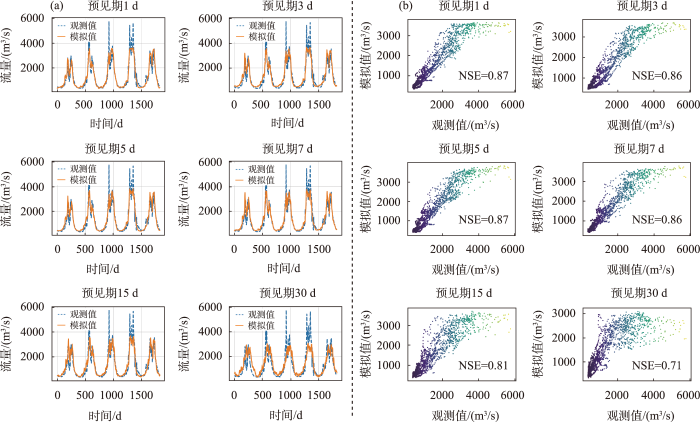
图4
集合模型在验证期2015—2019年模拟情况
Fig.4
Runoff simulation of the ensemble model in the validation period 2015-2019
由图4b散点图可得,随着预见期增加,离散程度逐渐增加。结合图5进一步准确评估模型精度随预见期的变化。整体上,集合模型随着预见期的增加,模型NSE和R值降低,RMSE增加,以上综合表明了模型精度随预见期增加,模型模拟精度降低。集合模型在预见期1~7 d时NSE均不低于0.86,1和5 d预见期模型精度一致,在预见期为3和7 d时精度略低。预见期9~15 d时,模型NSE均高于0.8,且该模型在预见期30 d时模拟NSE仍达到0.7以上。模型在9~30 d预见期时,随着预见期增加,NSE减少速率较1~7 d略快。模型的训练NSE与验证NSE相差0.04以内,表明模型没有产生过拟合,且模型训练NSE均高于验证NSE,表明了模型构建过程中参数调整的合理性(高程信息模型一样)。
图5
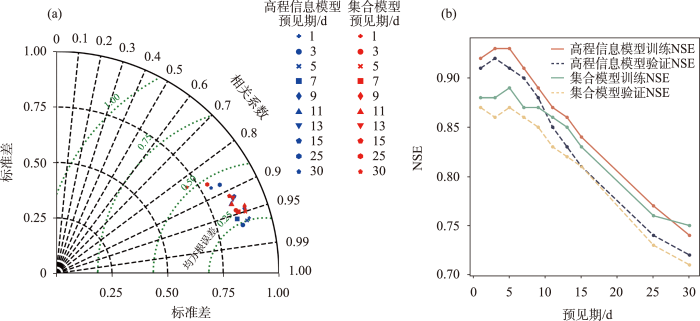
图5
高程信息模型与集合模型径流模拟(a)泰勒图和(b)NSE结果
Fig.5
Taylor chart (a) and Nash-Sutcliffe efficiency (NSE) and (b) of the runoff simulation results of the vertical zonation data-driven and ensemble models
综上所述,集合模型在短中期模拟中有着优秀的表现(NSE>0.85),甚至在15 d内的较长期模拟中也有着较好的表现(NSE>0.80),在30 d长期模拟过程中,集合模型表现良好(NSE>0.70)。
3.2 高程信息模型不同未来预见期表现
本文同时构建高程信息模型,同样以预见期1、3、5、7、15和30 d考虑海拔差异的高程信息模型,模拟效果如图6所示。该模型在30 d预见期内均能较好地捕捉年内及年际径流特征。高程信息模型在枯水期相比于集合模型拟合效果较好,在模拟夏季洪水上,相比于集合模型模拟效果有着较大的提升。整体上,模拟与观测径流散点图随预见期增加离散程度增加(预见期3 d除外)。
图6
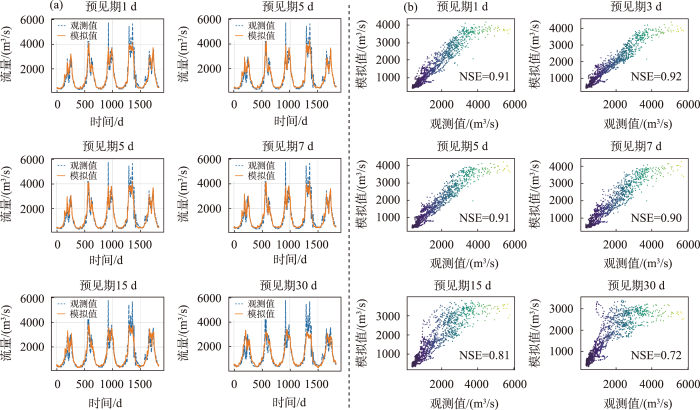
图6
高程信息模型在验证期2015—2019年模拟情况
Fig.6
Runoff simulation of the vertical zonation data-driven model in the validation period 2015-2019
由图5可知,整体上模型NSE和R值随着预见期的增加呈下降趋势,RMSE呈增加趋势,以上表明,模型精度随着预见期的增加而降低。高程信息模型在预见期1~7 d,模型NSE均能达到0.90以上,在预见期3 d时NSE最高,预见期1 d和5 d的模型效果相当(保留3位小数情况下,5 d预见期略优)。预见期9~15 d,模型NSE均高于0.80,模型精度变化速率较1~7 d相对增大。预见期25 d和30 d时的模型NSE均达到0.70以上,NSE分别为0.74和0.72。
在该高寒山区流域,高程信息模型短期模拟中NSE达到了0.90以上,模拟效果优秀;在中期模拟中NSE仍高于0.88,也有着优秀的表现;在30 d长期模拟中NSE达0.7以上,有着良好的表现。
3.3 高程信息模型与集合模型比较
整体上,2种模型精度均随着预见期的增加而降低。由图5a可知,在1~7 d预见期,高程信息模型相较于集合模型有着明显的边界,后随着预见期增加,2种模型重合明显,高程信息模型在1~7 d预见期优势更为明显。随着预见期进一步增加,高程信息模型相较于集合模型提升不明显,在11~30 d预见期模型精度基本一致。由图5b可知,两模型NSE在1~9 d预见期模型精度差距最大,平均提升4%,在预见期3 d时提升6%,两模型此时差距最大。在11~13 d预见期高程信息模型略优,15 d预见期后两模型模拟效果相当。综合考虑泰勒图与NSE结果图可以得出,模型在1~13 d未来径流模拟中,高程信息模型相较于集合模型有着更高的精度,1~5 d时高程信息模型优势最为突出。
进一步比较分析高程信息模型与集合模型在不同预见期模拟效果差异,选取连续300 d的验证期数据进行对比分析,如图7所示。观测流量在不同的时间差异较大,这一客观情况增加了模型拟合难度。2种模型在枯水期模拟效果均较好,在丰水期高程信息模型优于集合模型。在1~5 d预见期,高程信息模型在枯水期略优于集合模型,在丰水期,高程信息模型相较于集合模型模拟效果提升明显。在7~13 d预见期,高程信息模型在枯水期与集合模型模拟效果相当,在丰水期模拟效果略优,两模型差距随着预见期增加逐渐缩小。预见期为13 d时,两模型已无明显的差距。15~30 d预见期两模型在枯水与丰水期模拟效果相当。
图7
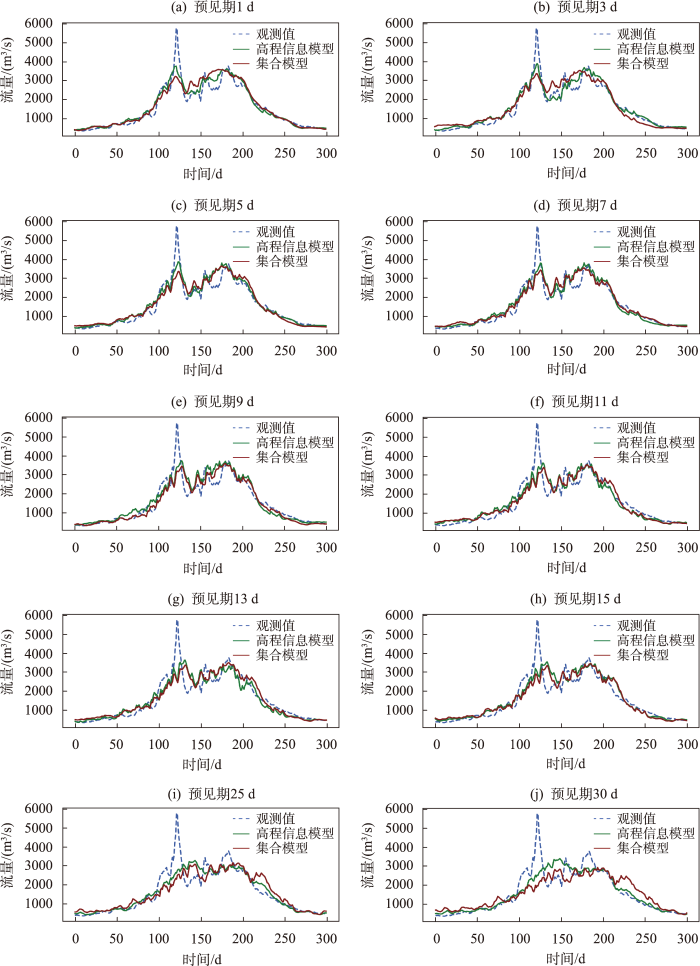
图7
高程信息模型与集合模型在300 d内模拟效果比较
Fig.7
Comparison of the runoff simulation results of the vertical zonation data-driven and ensemble models in 300 days
综上所述,高程信息模型在1~13 d预见期相较于集合模型有着提升,在1~5 d预见期提升效果明显,15~30 d预见期相较于集合模型已无提升。以上结果表明,高程信息模型在一定时间内有提升,超过时间阈值已无优势。通过对比高程信息模型与集合模型在不同预见期R、RMSE、NSE和径流过程表现情况综合得出,预见期3 d的高程信息模型在各项指标的评估中均达到最优。
4 讨论
4.1 模型模拟特殊表现情况分析
集合模型在1~7 d预见期模型精度相差不大,推测在该时段内,输入与输出之间相关性差异不大,流域面积大、输入因子求均模糊了短期内数据之间的差异,以及气温、降水、积雪面积变量在短期内时间相关性高且变化较少综合所致。随着预见期增加,输入与输出数据相关性降低,且差异较1~7 d预见期增大,流域求均已无法缩小不同预见期的差异,从而导致模型精度随预见期增加而下降。
研究区上游区域的融雪融冰影响着全年的径流变化。该流域面积大,高海拔上游区域影响石鼓径流有着明显的时滞性,且不同高程带分布在不同的区域,有着不同时滞期。直门达水文站洪水发生时间较石鼓早3 d,推断直门达以上区域至石鼓时滞期在3 d以上。高程信息模型在预见期3 d内,低海拔下游区有着更快的响应速度,在预见期3~5 d,高海拔区域影响更为明显,5 d后,高海拔降水以及融雪融冰影响逐渐减弱,输入与输出相关性逐渐降低,模型精度随之下降。高程信息模型在未来1和5 d径流模拟能力相当,且出现预见期为3 d模拟效果最优这一特殊情况,因流域空间的复杂性及关联的时间变化,目前模型仍难以解释,随着进一步挖掘时滞期所对应的高程区,构建考虑更加深入的时滞期影响的高程区进行建模,有望解释这一问题。
高程信息模型在短中期内提升效果明显,因在短中期内数据本就有着较高的相关性,高程信息模型在此基础上能挖掘出更有效的信息,从而提升明显。随着预见期增加,输入数据本就对模型训练难以提供足够有效信息,对数据进一步挖掘也无法提供信息增益。
4.2 最佳模型汛期及极端事件的模拟能力
预见期3 d的高程信息模型与集合模型在2015—2019年模拟效果如图8所示。2015年春汛3月高程信息模型优于集合模型,4—5月集合模型优于高程信息模型。2015年夏汛高程信息模型拟合程度更贴近观测径流,在夏汛模拟表现更优。2016年整个春汛时期,高程信息模型均优于集合模型。高程信息模型2016年夏汛时可以更好地拟合洪水的峰值以及洪水的变化,明显优于集合模型,且夏汛模拟提升效果优于春汛模拟。如同2016年,2017、2018年高程信息模型在春汛和夏汛时均优于集合模型且夏汛提升效果更为明显。2019年4—5月发生了春季极端洪水,两模型春季极端洪水表现均不佳,其余春汛时期高程信息模型优于集合模型;夏汛时,高程信息模型除6月的洪水极值,其余时期均优于集合模型。
图8
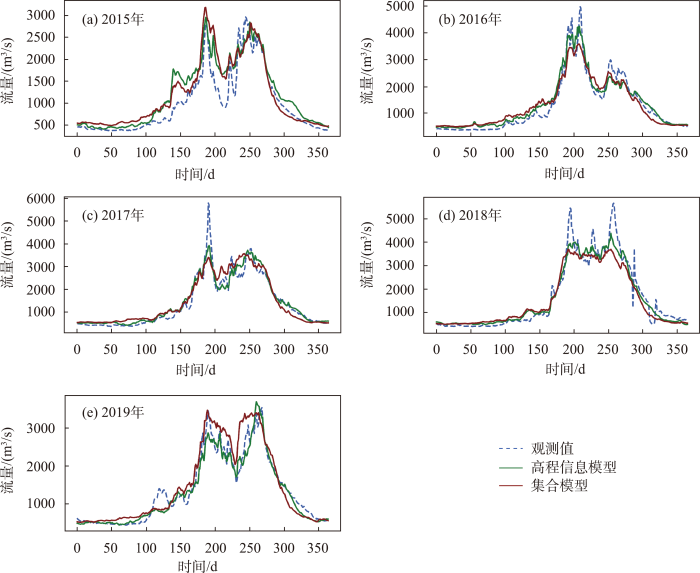
图8
最佳3 d预见期两模型在验证期2015—2019年模拟情况
Fig.8
Runoff simulation results of the vertical zonation data-driven and ensemble models for the optimal 3 days lead-time in the validation period 2015-2019
整体上,预见期为3 d的高程信息模型在春汛及夏汛表现均优于集合模型,而且在夏季洪水期能够更好地模拟极端洪水与径流变化情况,优势更为明显。
2015年春季4—5月和2019年6月洪水极值处集合模型模拟表现优于高程信息模型特殊情况,可解释为模型参数训练过程中自身存在不确定性,训练数据是多年全年数据,模型更多地关注整体情况而忽略局部细节,导致高程信息模型在局部时期表现不如集合模型,这是正常的。2019年4—5月发生春季极端洪水时期,两模型表现欠佳,可解释为春季极端洪水发生本就罕见,缺少足够的极端洪水样本数据提供模型科学训练,且模型输入数据是多年逐日数据,春季极端洪水在整个训练样本中所占比例较少,而模型参数调整是基于所有样本进行,从而导致模型对春季极端洪水模拟欠佳。为了更准确地模拟春季极端洪水,可取训练样本仅为春汛期,且要具备足够多的极端洪水事件样本供模型学习,但该模型就无法重现全年的径流过程。
4.3 高程信息模型的潜在应用
高寒山区是水资源的发源地[47],位于河流的上游地区。能否对高寒山区水资源进行有效的管理,影响着中下游的民生与经济。未来径流的准确模拟可为相关部门进行科学合理的决策提供依据。高寒山区因其复杂的地理气候条件,对该流域准确的径流模拟提出了挑战。基于物理过程的水文模型,因其使用数据及模型结构的局限性,难以满足高精度的未来径流模拟的要求,基于数据驱动的LSTM模型可以较好地解决此类问题。LSTM高程信息模型考虑高寒山区的海拔差异,相较于集合模型进一步挖掘了有效的数据信息,在长、中、短期(30 d内)都有着良好的表现。高程信息模型在短期模拟中,NSE达到了0.90以上,在中期模拟中NSE高于0.88,在30 d长期模拟中NSE达0.70以上。集合模型洪水模拟效果不佳,高程信息模型在预见期1~5 d,洪水模拟能力显著优于集合模型,预见期7~13 d模拟能力也要优于集合模型,表明了高程信息模型更适合短中期洪水模拟应用。
5 结论
本文构建了基于气候要素分带的高程信息模型和无考虑分带的集合模型,共构建20个模型并分析其在未来短、中、长期的模拟果,主要结论如下:
(1) 两模型均能很好地模拟年内年际径流变化规律,集合模型在预见期1~15 d时模型NSE均高于0.80,且该模型在预见期30 d时NSE仍达到0.70以上。高程信息模型在预见期1~7 d时NSE均能达到0.90以上,预见期延长至15 d,模型NSE高于0.80,预见期为25和30 d时,NSE仍能达到0.70。在短期模拟中,集合模型NSE>0.86;高程信息模型模拟效果优秀,NSE>0.90。中期模拟中,两模型模拟精度NSE>0.85。30 d长期模拟NSE均高于0.70。两模型结构及参数设置在短、中、长期(30 d内)模拟中均有着良好的效果。
(2) 整体上,随着预见期的增加,两模型精度逐渐降低,在预见期9~15 d时下降速度最快。高程信息模型在1~13 d时相较于集合模型有着更高的模型精度,在预见期1~5 d时有着明显的优势,13 d后高程信息模型已不具备优势。两模型在枯水期模拟效果较好,在丰水期高程信息模型优于集合模型。预见期1~5 d,高程信息模型枯水期模拟表现优于集合模型,丰水期表现相较于集合模型提升明显。在7~13 d预见期,高程信息模型与集合模型枯水期表现相当,高程信息模型丰水期模拟效果略优。此外,高程信息模型在洪水模拟中有着更优异的表现。
(3) 预见期为3 d的高程信息模型表现最优,整体上无论在春汛以及夏汛模拟过程中相较于集合模型更加优秀,且在夏汛模拟过程中优势更为明显。但对于发生频率极低的极端春季洪水事件,两模型均不能有效地重建洪峰过程,极端洪水模拟仍有进一步改进空间。
参考文献
高寒区典型下垫面水文功能小流域观测试验研究
[J].
Field experimental research on hydrological function over several typical underlying surfaces in the cold regions of Western China
DOI:10.11867/j.issn.1001-8166.2014.04.0507
[本文引用: 1]

In the cold regions of western China, underlying surfaces are mainly (87.7%) composed of grassland, meadow and desert. However, the hydrological functions of these landtypes are unclear and lacking in adequate measured data. Based on the 4-year (2009-2012) observation work at point scale, small watershed scale and simulation results from Soil-Vegetation-Atmosphere Transfer (SVAT) system, it concludes that the alpine desert should be the primary runoff production area, which takes part 12% of high-cold region. While the alpine grassland and meadow (taking about 64%) contribute to the watershed runoff a little, its ecological function is more evident than its hydrological function. Combined with other research results in the literature, runoff coefficient for different landsacpes can be sorted as: glacier>cold desert>swamp meadow>hill slope shrub>meadow>alpine grassland>forest. If the vegetation belt moves upward under the global warming, the runoff coefficient will decrease in the alpine watershed of China.
Review of climate and cryospheric change in the Tibetan Plateau
[J].
“亚洲水塔”变化对下游水资源的连锁效应
[J].
Cascading impacts of Asian water tower change on downstream water systems
青藏高原: 全球气候变化的驱动机与放大器(Ⅲ): 青藏高原隆起对气候变化的影响
[J].
Qinghai-Tibetan Plateau: A driver and amplifier of the global climatic change Ⅲ: The effects of the uplift of Qinghai-Tibetan Plateau on climatic changes
Climate change will affect the Asian water towers
[J].
DOI:10.1126/science.1183188
PMID:20538947
[本文引用: 1]
More than 1.4 billion people depend on water from the Indus, Ganges, Brahmaputra, Yangtze, and Yellow rivers. Upstream snow and ice reserves of these basins, important in sustaining seasonal water availability, are likely to be affected substantially by climate change, but to what extent is yet unclear. Here, we show that meltwater is extremely important in the Indus basin and important for the Brahmaputra basin, but plays only a modest role for the Ganges, Yangtze, and Yellow rivers. A huge difference also exists between basins in the extent to which climate change is predicted to affect water availability and food security. The Brahmaputra and Indus basins are most susceptible to reductions of flow, threatening the food security of an estimated 60 million people.
基于SWAT与新安江模型的闽江建阳流域径流模拟研究
[J].
Runoff simulation in Jianyang watershed of Minjiang River based on SWAT and Xin'anjiang model
基于改进降水输入模块的农田地表中尺度径流模拟
[J].
Simulation of mesoscale runoff on farmland surface based on improved precipitation input model
Prediction and modelling of rainfall-runoff during typhoon events using a physically-based and artificial neural network hybrid model
[J].DOI:10.1080/02626667.2014.959446 URL [本文引用: 1]
基于SOM的流域分类和无资料区径流模拟
[J].
DOI:10.11820/dlkxjz.2014.08.011
[本文引用: 1]
无资料区的径流模拟问题是国内外水文研究的难点之一。基于相似流域的参数移植法是常用的解决方法之一,但如何判断相似流域是制约此类方法发展的难点。本文以滇池流域为例,采用自组织映射神经网络(SOM)和层次聚类分析(HCA)联合模式,选取16个流域物理特征为指标进行子流域分类,以确定相似流域。运用无分层的K-means分类的SOM法将整个滇池流域划分为7类具有水文属性的子流域组,分类情景与HCA基本一致,两者实现相互验证。采用HBV水文模型模拟子流域径流过程,并选择部分子流域进行组内参数移植交叉检验。结果显示,HBV模型可较好的模拟滇池流域径流过程;此外,子流域交叉检验结果优良,表明同组内参数可以相互移植。本文不仅为解决滇池流域无资料问题提供了可靠手段,而且由于SOM实现了高维流域特征可视化展示,有助于管理者全面、深入的把握滇池流域水文属性的空间分布特征,为进行水资源管理提供指导。
Classification and runoff simulation of data-scarce basins based on self-organizing maps
DOI:10.11820/dlkxjz.2014.08.011
[本文引用: 1]
Runoff prediction in ungauged basins (PUB) is one of the difficult research areas in hydrological studies. Parameter replacement using data from similar basins is one of the common methods in dealing with the PUB problem. When basins are similar in physical properties, their hydrological behaviors are assumed to be also similar and thus the hydrological model parameters can be transferred from the donor basin to the target basin. However, it is hard to determine whether a donor basin is indeed similar to a target basin and therefore it is not always clear whether the parameters can be transferred between the basins. Existing research often focus on river basin PUB problem, with inadequate attention on lake basins that contain a number of river streams. This study addresses the PUB question using Lake Dianchi Basin as an example. Lake Dianchi Basin has a complicated river network as well as serious PUB problems. Self-organizing maps (SOM) and hierarchical clustering analysis (HCA) were jointly used to identify analogy basins based on 16 physical attributes, including area, length, slope, drainage density, Ke, mean elevation, average precipitation, six land use types and three soil types. SOM method with K-means cluster was applied to classify similar sub-basins into distinct groups and Davis-Bouldin index was used to determine the optimal group numbers. After 1000 iterations the 43 sub-basins were classified into seven groups (I-VII). This SOM-based classification result is the same as the result of HCA except for two sub-basins. Among the seven groups, group I, IV, and VII contains most of the sub-basins and the other four groups contain no more than three sub-basins each. Different groups have different characteristics and the classification result provides a guidance for local management of the lake basin. For instance, group I is located in high elevation area where the density of streams and infiltration rate of the soil are both low therefore the area is flood-prone, thus the local government should pay more attention on flood control in such area. HBV model was used to simulate the runoff process and for sub-basins where the simulation went well, their parameters were used in the cross-basin test. The cross-basins test was applied to test whether or not hydrological model parameters could be transferred between two sub-basins in the same group. Six stations in three groups were selected as examples and sub-basins in each two sub-basin pair are from the same group. The result shows that the HBV model performs well in the runoff simulation of Lake Dianchi Basin (R2≥0.718, NSE≥=0.495). The cross-basin test result is also very promising (R2≥0.654 and NSE≥0.472) — it proves that ungauged sub-basins could borrow the model parameters of gauged basins in the same group. Thus, this research provides a solution for solving the PUB problem in the Lake Dianchi Basin. This research provides a basis for solving the problem of lack of data for runoff modeling for the basin. Meanwhile, SOM visualizes multi-dimensional properties of the basin, which is useful for practitioners in water resource management to comprehensively understand the spatial distribution of hydrological characteristics of Lake Dianchi Basin.
雅鲁藏布江流域多源降水产品评估及其在水文模拟中的应用
[J].
DOI:10.18306/dlkxjz.2020.07.006
[本文引用: 1]
论文对比分析了1980—2016年基于站点插值降水数据CMA(China Meteorological Administration)和APHRODITE(Asian Precipitation-Highly-Resolved Observational Data Integration Towards Evaluation)、卫星遥感降水数据PERSIANN-CDR(Precipitation Estimation from Remotely Sensed Information using Artificial Neural Network-Climate Data Record)和GPM(Global Precipitation Measurement)、大气再分析数据GLDAS(Global Land Data Assimilation System)以及区域气候模式输出数据HAR(High Asia Refined analysis)在雅鲁藏布江7个子流域的降水时空描述,利用国家气象站点数据对各套降水数据进行单点验证,并以这6套降水数据驱动VIC(Variable Infiltration Capacity)大尺度陆面水文模型反向评估了各套降水产品在雅鲁藏布江各子流域径流模拟中的应用潜力。结果表明:① PERSIANN-CDR和GLDAS年均降水量最高(770~790 mm),其次是HAR和GPM(650~660 mm),CMA和APHRODITE年均降水量最低(460~500 mm)。除GPM外,其他降水产品在各子流域都能表现季风流域的降水特征,约70%~90%的年降水量集中在6—9月份。② 除PERSIANN-CDR和GLDAS外,其他降水产品皆捕捉到流域降水自东南向西北递减的空间分布特征。其中,HAR数据空间分辨率最高,表现出更详细的流域内部降水空间分布特征。③ 与对应网格内的国家气象站降水数据对比显示,APHRODITE、GPM和HAR降水整体低估(低估10%~30%),且严重低估的站点主要集中在下游(低估40%~120%)。PERSIANN-CDR和GLDAS整体表现为高估上游流域站点降水(高估28%~60%),但低估下游流域站点降水(低估11%~21%)。④ 在流域径流模拟上,当前的6套降水产品在精度或时段上仍无法满足水文模型模拟的需求。⑤ 通过水文模型反向评估,6套降水产品中区域气候模式输出的HAR在流域平均降水量和季节分配上更合理。
Evaluation of multiple precipitation datasets and their potential utilities in hydrologic modeling over the Yarlung Zangbo River Basin
DOI:10.18306/dlkxjz.2020.07.006
[本文引用: 1]
The gauge-based precipitation data from the National Climate Center, China Meteorological Administ-ration (CMA), Asian Precipitation-Highly-Resolved Observational Data Integration Towards Evaluation (APHRODITE), Precipitation Estimation from Remotely Sensed Information using Artificial Neural Network-Climate Data Record (PERSIANN-CDR), Global Precipitation Measurement (GPM), Global Land Data Assimilation System (GLDAS), High Asia Refined analysis (HAR) are compared with each other and evaluated by the precipitation data from 16 national meteorological stations during 1980-2016 in the Yarlung Zangbo River and its sub-basins. The potential utilities of these multiple precipitation datasets are then systematically evaluated as inputs for the variable infiltration capacity (VIC) macroscale land surface hydrologic model. The results show that: 1) PERSIANN-CDR and GLDAS contain the largest precipitation estimates among the six datasets with mean annual precipitation of 770-790 mm, followed by the HAR and GPM (650-660 mm), while CMA and APHRODITE contain the lowest precipitation estimates with mean annual precipitation of 460-500 mm. All the products can detect the large-scale monsoon-dominated precipitation regime in the Yarlung Zangbo River and its sub-basins with 70%-90% of annual total precipitation occurring in June-September except the GPM. 2) The general spatial pattern of the annual mean precipitation fields is roughly in agreement among the six datasets, with a decreasing trend from the southeast to the northwest in the Yarlung Zangbo River Basin except the PERSIANN-CDR and GLDAS. 3) Relative to the data from the national meteorological stations, APHRODITE, GPM, and HAR generally underestimate precipitation by 10%-30%, while PERSIANN-CDR and GLDAS overestimate precipitation from stations in upstream sub-basins by 28%-60% and underestimate precipitation from stations in downstream sub-basins by 11%-21%. 4) The six precipitation datasets cannot satisfy the needs of hydrological simulation in term of accuracy or period in the basin. 5) HAR precipitation data—output of regional climate model—show more reasonable amount and seasonal pattern among the six datasets in the upper Brahmaputra according to the inverse evaluation by VIC hydrological model.
Calibration of hydrological models using flow-duration curves
[J].
DOI:10.5194/hess-15-2205-2011
URL
[本文引用: 1]
. The degree of belief we have in predictions from hydrologic models will normally depend on how well they can reproduce observations. Calibrations with traditional performance measures, such as the Nash-Sutcliffe model efficiency, are challenged by problems including: (1) uncertain discharge data, (2) variable sensitivity of different performance measures to different flow magnitudes, (3) influence of unknown input/output errors and (4) inability to evaluate model performance when observation time periods for discharge and model input data do not overlap. This paper explores a calibration method using flow-duration curves (FDCs) to address these problems. The method focuses on reproducing the observed discharge frequency distribution rather than the exact hydrograph. It consists of applying limits of acceptability for selected evaluation points (EPs) on the observed uncertain FDC in the extended GLUE approach. Two ways of selecting the EPs were tested – based on equal intervals of discharge and of volume of water. The method was tested and compared to a calibration using the traditional model efficiency for the daily four-parameter WASMOD model in the Paso La Ceiba catchment in Honduras and for Dynamic TOPMODEL evaluated at an hourly time scale for the Brue catchment in Great Britain. The volume method of selecting EPs gave the best results in both catchments with better calibrated slow flow, recession and evaporation than the other criteria. Observed and simulated time series of uncertain discharges agreed better for this method both in calibration and prediction in both catchments. An advantage with the method is that the rejection criterion is based on an estimation of the uncertainty in discharge data and that the EPs of the FDC can be chosen to reflect the aims of the modelling application, e.g. using more/less EPs at high/low flows. While the method appears less sensitive to epistemic input/output errors than previous use of limits of acceptability applied directly to the time series of discharge, it still requires a reasonable representation of the distribution of inputs. Additional constraints might therefore be required in catchments subject to snow and where peak-flow timing at sub-daily time scales is of high importance. The results suggest that the calibration method can be useful when observation time periods for discharge and model input data do not overlap. The method could also be suitable for calibration to regional FDCs while taking uncertainties in the hydrological model and data into account.\n
CMORPH卫星站点融合降水的沂河流域径流模拟适用性评估
[J].
Applicability evaluation of CMORPH merged rainfall in hydrologic simulation Yihe River Basin
Can artificial intelligence and data-driven machine learning models match or even replace process-driven hydrologic models for streamflow simulation? A case study of four watersheds with different hydro-climatic regions across the CONUS
[J].
Reply to comment by Keith J. Beven and Hannah L. Cloke on "Hyperresolution global land surface modeling: Meeting a grand challenge for monitoring Earth's terrestrial water"
[J].
Effective and efficient global optimization for conceptual rainfall-runoff models
[J].DOI:10.1029/91WR02985 URL [本文引用: 1]
基于SWAT模型的渭河流域干旱时空分布
[J].
DOI:10.18306/dlkxjz.2015.09.008
[本文引用: 1]
以渭河流域为例,从流域水文循环的角度出发,在SWAT(Soil and Water Assessment Tool)分布式水文模型和Palmer干旱指数(Palmer Drought Severity Index)原理的基础上提出了干旱分析模型SWAT-PDSI,对渭河流域干旱的时空演变规律和发生频率进行了分析。研究结果表明:①经率定和验证的SWAT模型能够较好地模拟渭河流域的水文变化过程;②利用SWAT-PDSI对典型干旱事件(1995年干旱)的评估结果显示,该模型能较好地反映渭河流域干旱的时空差异和变化规律;③渭河流域、渭河干流和泾河流域均表现为变干的趋势,而北洛河流域表现为变湿的趋势,但均未通过95%的置信水平检验;④渭河流域多数子流域的SWAT-PDSI多年平均值处于-1~1,说明该流域多数地区处于正常状态;⑤渭河流域北部的北洛河流域和泾河流域的上游地区易发生干旱,发生中等以上、严重以上和极端干旱事件的频率最高。
Spatiotemporal patterns of droughts based on SWAT model for the Weihe River Basin
DOI:10.18306/dlkxjz.2015.09.008
[本文引用: 1]
Drought is a complex natural hazard that is difficult to define and assess. By considering the hydrological cycle of river basins, a drought evaluation model SWAT-PDSI was constructed based on the Palmer Drought Severity Index(PDSI) and simulated results of SWAT (Soil and Water Assessment Tool) in the Weihe River Basin. Moreover, characteristics of the spatiotemporal distribution and frequency of drought hazard in the basin were analyzed. Results showed that: (1) The calibrated and validated SWAT model can be used to predict the hydrological process in the Weihe River Basin since it results in similar simulated trend of change as the observed data; (2) The SWAT-PDSI model based on SWAT and PDSI well describes the characteristics of drought in the Weihe River Basin as verified by the drought indices in 1995; (3) Temporally, the Weihe River Basin, Weihe River mainstream, and Jinghe River Basin showed a drying trend and the Beiluohe River Basin showed a wetter trend, but these were not statistically significant at the 0.05 confidence level; (4) Spatially, the annual average of SWAT-PDSI was between -1 and 1 in most subbasins; (5) High frequency drought areas were mainly distributed in the upstream of the Beiluohe River Basin and the Jinghe River Basin.
Application of soft computing models in streamflow forecasting
[J].
DOI:10.1680/jwama.16.00075
[本文引用: 1]
The accuracy of five soft computing techniques was assessed for the prediction of monthly streamflow of the Gilgit river basin by a cross-validation method. The five techniques assessed were the feed-forward neural network (FFNN), the radial basis neural network (RBNN), the generalised regression neural network (GRNN), the adaptive neuro fuzzy inference system with grid partition (Anfis-GP) and the adaptive neuro fuzzy inference system with subtractive clustering (Anfis-SC). The interaction between temperature and streamflow was considered in the study. Two statistical indexes, mean square error (MSE) and coefficient of determination (R-2), were used to evaluate the performances of the models. In all applications, RBNN and Anfis-SC were found to give more accurate results than the FFNN, GRNN and Anfis-GP models. The effect of periodicity was also examined by adding a periodicity component into the applied models and the results were compared with a statistical model (seasonal autoregressive integrated moving average (Sarima)) to check the prediction accuracy. The results of this comparison showed that periodicity inputs improved the prediction accuracy of the applied models and, in all cases, the soft computing models performed much better than the Sarima model. The periodic RBNN and Anfis-SC models increased the MSE accuracy of Sarima by 25.5-24.7%.
A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region
[J].DOI:10.1016/j.jhydrol.2013.11.054 URL [本文引用: 1]
Use of data driven techniques for short lead time streamflow forecasting in Mahanadi Basin
[J].DOI:10.1016/j.aqpro.2015.02.122 URL [本文引用: 1]
A transdisciplinary review of deep learning research and its relevance for water resources scientists
[J].DOI:10.1029/2018WR022643 URL [本文引用: 1]
人工神经网络峰值识别理论及其在洪水预报中的应用
[J].
Peak value recognition theory of artificial neural network and its application to flood forecasting
Development and application of a decision group back-propagation neural network for flood forecasting
[J].DOI:10.1016/j.jhydrol.2010.02.019 URL [本文引用: 1]
Comparison between kinematic wave and artificial neural network models in event-based runoff simulation for an overland plane
[J].DOI:10.1016/j.jhydrol.2008.05.015 URL [本文引用: 1]
基于遗忘因子的BP神经网络水文实时预报方法
[J].
Real-time hydrological forecasting method of artificial neural network based on forgetting factor
Employing machine learning algorithms for streamflow prediction: A case study of four river basins with different climatic zones in the United States
[J].DOI:10.1007/s11269-020-02659-5 [本文引用: 1]
Pruning of support vector networks on flood forecasting
[J].DOI:10.1016/j.jhydrol.2007.08.029 URL [本文引用: 1]
基于改进支持向量机回归的日径流预测模型
[J].
Daily runoff forecast based on improved support vector machine regression model
Artificial neural network model for rainfall-runoff: A case study
[J].
Support vector machine-based models for hourly reservoir inflow forecasting during typhoon-warning periods
[J].DOI:10.1016/j.jhydrol.2009.03.032 URL [本文引用: 1]
Long short-term memory
[J].
DOI:10.1162/neco.1997.9.8.1735
PMID:9377276
[本文引用: 1]
Learning to store information over extended time intervals by recurrent backpropagation takes a very long time, mostly because of insufficient, decaying error backflow. We briefly review Hochreiter's (1991) analysis of this problem, then address it by introducing a novel, efficient, gradient-based method called long short-term memory (LSTM). Truncating the gradient where this does not do harm, LSTM can learn to bridge minimal time lags in excess of 1000 discrete-time steps by enforcing constant error flow through constant error carousels within special units. Multiplicative gate units learn to open and close access to the constant error flow. LSTM is local in space and time; its computational complexity per time step and weight is O(1). Our experiments with artificial data involve local, distributed, real-valued, and noisy pattern representations. In comparisons with real-time recurrent learning, back propagation through time, recurrent cascade correlation, Elman nets, and neural sequence chunking, LSTM leads to many more successful runs, and learns much faster. LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms.
基于时序分解与机器学习的非平稳径流序列集成模型与应用
[J].
Integrated model and application of non-stationary runoff based on time series decomposition and machine learning
Using a long short-term memory (LSTM) neural network to boost river streamflow forecasts over the western United States
[J].
DOI:10.5194/hess-26-5449-2022
URL
[本文引用: 1]
. Accurate river streamflow forecasts are a vital tool in the fields of water security, flood preparation and agriculture, as well as in industry more generally. Traditional physics-based models used to produce streamflow forecasts have become increasingly sophisticated, with forecasts improving accordingly. However, the development of such models is often bound by two soft limits: empiricism – many physical relationships are represented empirical formulae; and data sparsity – long time series of observational data are often required for the calibration of these models. Artificial neural networks have previously been shown to be highly effective at simulating non-linear systems where knowledge of the underlying physical relationships is incomplete. However, they also suffer from issues related to data sparsity. Recently, hybrid forecasting systems, which combine the traditional physics-based approach with statistical forecasting techniques, have been investigated for use in hydrological applications. In this study, we test the efficacy of a type of neural network, the long short-term memory (LSTM), at predicting streamflow at 10 river gauge stations across various climatic regions of the western United States. The LSTM is trained on the catchment-mean meteorological and hydrological variables from the ERA5 and Global Flood Awareness System (GloFAS)–ERA5 reanalyses as well as historical streamflow observations. The performance of these hybrid forecasts is evaluated and compared with the performance of both raw and bias-corrected output from the Copernicus Emergency Management Service (CEMS) physics-based GloFAS. Two periods are considered, a testing phase (June 2019 to June 2020), during which the models were fed with ERA5 data to investigate how well they simulated streamflow at the 10 stations, and an operational phase (September 2020 to October 2021), during which the models were fed forecast variables from the European Centre for Medium-Range Weather Forecasts (ECMWF) Integrated Forecasting System (IFS), to investigate how well they could predict streamflow at lead times of up to 10 d. Implications and potential improvements to this work are discussed. In summary, this is the first time an LSTM has been used in a hybrid system to create a medium-range streamflow forecast, and in beating established physics-based models, shows promise for the future of neural networks in hydrological forecasting.\n
Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales
[J].
Transferring hydrologic data across continents-leveraging data-rich regions to improve hydrologic prediction in data-sparse regions
[J].
Rainfall-runoff prediction at multiple timescales with a single long short-term memory network
[J].
DOI:10.5194/hess-25-2045-2021
URL
[本文引用: 1]
. Long Short-Term Memory (LSTM) networks have been applied to daily discharge prediction with remarkable success.\nMany practical applications, however, require predictions at more granular timescales.\nFor instance, accurate prediction of short but extreme flood peaks can make a lifesaving difference, yet such peaks may escape the coarse temporal resolution of daily predictions.\nNaively training an LSTM on hourly data, however, entails very long input sequences that make learning difficult and computationally expensive.\nIn this study, we propose two multi-timescale LSTM (MTS-LSTM) architectures that jointly predict multiple timescales within one model, as they process long-past inputs at a different temporal resolution than more recent inputs.\nIn a benchmark on 516 basins across the continental United States, these models achieved significantly higher Nash–Sutcliffe efficiency (NSE) values than the US National Water Model.\nCompared to naive prediction with distinct LSTMs per timescale, the multi-timescale architectures are computationally more efficient with no loss in accuracy.\nBeyond prediction quality, the multi-timescale LSTM can process different input variables at different timescales, which is especially relevant to operational applications where the lead time of meteorological forcings depends on their temporal resolution.\n
基于LSTM神经网络与蒙特卡罗模型的辽河源头区径流预测
[J].
Runoff prediction of source area of Liaohe River based on LSTM neural network and Monte Carlo model
基于LSTM的青藏高原冻土区典型小流域径流模拟及预测
[J].
DOI:10.7522/j.issn.1000-0240.2021.0056
[本文引用: 1]
冻土覆盖率高的小流域的径流形成受温度因素控制明显,普通水文模型不适用,而常规冻土水文模型因需要较多的气象观测要素而难以应用。考虑冻土流域产流机制,利用青藏高原腹地风火山小流域2017—2018年逐日降水、气温、径流观测数据,以降水、气温为输入,径流为输出,基于长短期记忆神经网络(LSTM)建立了适用于小流域尺度的冻土水文模型,并利用2019年观测数据进行验证。模型得益于LSTM特殊的细胞状态和门结构能够学习、反映活动层冻融过程和土壤含水量变化,具有一定的冻土水文学意义,能很好地模拟冻土区径流过程。模型训练期R<sup>2</sup>、NSE均为0.93,RMSE为0.63 m<sup>3</sup>·s<sup>-1</sup>,验证期R<sup>2</sup>、NSE分别为0.81、0.77,RMSE为0.69 m<sup>3</sup>·s<sup>-1</sup>。同时,为了验证模型可靠性,将模型应用于邻近的沱沱河流域,模型训练期(1990—2009年)R<sup>2</sup>、NSE均为0.73,验证期(2010—2019年)R<sup>2</sup>、NSE分别为0.66、0.64,模拟结果较好。考虑到未来气候变化,通过模型对风火山流域径流进行了预测:降水每增加10%,年径流增加约12%;气温每升高0.5 ℃,年径流增加约1%;春季融化期、秋季冻结期径流增幅明显,而由于蒸发加剧、活动层加深,径流在8月出现了减少。模型经训练后依靠降水、气温作为输入能较好地模拟、预测青藏高原冻土区小流域径流,为缺少土壤温度、水分等观测数据的冻土小流域径流研究提供了一种简单有效并具有一定物理意义的方法。
Runoff simulation and prediction of a typical small watershed in permafrost region of the Qinghai-Tibet Plateau based on LSTM
DOI:10.7522/j.issn.1000-0240.2021.0056
[本文引用: 1]
The Qinghai-Tibet Plateau, known as the Third Pole, with 42.4% permafrost coverage, is sensitive to climate change. Runoff generation of small-scale watershed with high permafrost coverage is significantly controlled by temperature factor, which makes ordinary hydrological model unsuitable for this area, while lack of measured data such as soil temperature and moisture makes common permafrost hydrological model difficult to be applied. Moreover, increase in air temperature will result in permafrost degradation, which fundamentally changes the hydrogeological conditions in permafrost regions and finally changes the runoff process in permafrost watershed. Thus, the air temperature is a key factor in permafrost runoff modeling. LSTM (long short-term memory) is a special recurrent neural network with a more detailed internal processing unit, which contains cell state and gate structures, helping it effectively use long-distance time series information in hydrology. In this study, we developed a permafrost hydrological model at small-scale watershed based on LSTM neural networks with the consideration of runoff generation mechanism in permafrost. And it was applied in Fenghuoshan watershed, a tributary of the source region of the Yangtze River with 100% permafrost coverage, located at the central of Qinghai-Tibet Plateau. In the LSTM permafrost hydrological model, the precipitation and air temperature are employed as model inputs, while the runoff is regarded as the output. The daily precipitation, air temperature, and runoff observation data from year 2017 to 2018 were employed to train the model, and the dataset of year 2019 was used for model validation. Benefiting from the special cell state and gate structures of LSTM, the model is capable of learning and reflecting freeze-thaw processes and soil moisture seasonal variation in the active layer, with cell state evolution of some LSTM neurons consistent with these processes. It gives the model a certain permafrost hydrological significance and the high performance of permafrost runoff simulation. The values of R2, NSE and RMSE were 0.93, 0.93, 0.63 m3·s-1 during training period, 0.81, 0.77, 0.69 m3·s-1 during validation period, respectively. Besides, the model performed well in all periods within the year, including spring flood period, summer recession period, summer flood period, autumn recession period and winter freezing period. The model was also applied in the Tuotuohe watershed, which is close to Fenghuoshan watershed. The values of R2, NSE were 0.73, 0.73 during training period, 0.66, 0.64 during validation period, respectively. The model result was comparable to the results of CRHM model and WEB-DHM-SF model, which demonstrates it was reasonable and reliable. And the model was employed to predict runoff changes of Fenghuoshan watershed under 10 different climate change scenarios, those were 10% or 20% increase in precipitation with 0 ℃, 1.0 ℃, 2.0 ℃ increase in air temperature and 0.5 ℃, 1.0 ℃, 1.5 ℃, 2.0 ℃ increase in air temperature with precipitation unchanged. It shows that every 10% increase in the precipitation will result in approximately 12% increase in the annual runoff, while every 0.5 ℃ increase in the air temperature will result in approximately 1% increase. The thaw of underground ice induced by increase in air temperature contributes little to the runoff increase. However, it significantly changes the runoff process through altering the freeze-thaw processes in the active layer, which has a different influence on the runoff during different periods. Increase in the air temperature will result in significant increase in the runoff during spring thaw and autumn freeze period, while the runoff decreases in August due to the increased evaporation and deepened active layer caused by the increase in the air temperature. Meanwhile, increase in the air temperature prolongs the thaw period and shortens the freeze period, which will change the runoff compositions. This illustrates the temperature-induced variable source area runoff generation process, namely the runoff generation in permafrost region not solely determined by soil moisture but controlled by temperature conditions. The results show that the trained model can be employed to simulate and predict runoff of small permafrost watershed with only precipitation and air temperature as inputs, which are easier available in permafrost areas. It provides a simple and effective method, with a certain physical meaning, for permafrost watershed lacking observation data such as soil temperature and moisture.
Learning representations by back-propagating errors
[J].DOI:10.1038/323533a0 [本文引用: 1]
Generalization of backpropagation with application to a recurrent gas market model
[J].
LSTM network: A deep learning approach for short-term traffic forecast
[J].DOI:10.1049/itr2.v11.2 URL [本文引用: 1]
Deep learning with long short-term memory networks for financial market predictions
[J].DOI:10.1016/j.ejor.2017.11.054 URL [本文引用: 1]
Rainfall-runoff modelling using Long Short-Term Memory (LSTM) networks
[J].
DOI:10.5194/hess-22-6005-2018
URL
[本文引用: 1]
. Rainfall–runoff modelling is one of the key\nchallenges in the field of hydrology. Various approaches exist, ranging from\nphysically based over conceptual to fully data-driven models. In this paper,\nwe propose a novel data-driven approach, using the Long Short-Term Memory\n(LSTM) network, a special type of recurrent neural network. The advantage of\nthe LSTM is its ability to learn long-term dependencies between the provided\ninput and output of the network, which are essential for modelling storage\neffects in e.g. catchments with snow influence. We use 241 catchments of the\nfreely available CAMELS data set to test our approach and also compare the\nresults to the well-known Sacramento Soil Moisture Accounting Model (SAC-SMA)\ncoupled with the Snow-17 snow routine. We also show the potential of the LSTM\nas a regional hydrological model in which one model predicts the discharge\nfor a variety of catchments. In our last experiment, we show the possibility\nto transfer process understanding, learned at regional scale, to individual\ncatchments and thereby increasing model performance when compared to a LSTM\ntrained only on the data of single catchments. Using this approach, we were\nable to achieve better model performance as the SAC-SMA + Snow-17, which\nunderlines the potential of the LSTM for hydrological modelling applications.\n
An empirical comparison of voting classification algorithms: Bagging, boosting, and variants
[J].DOI:10.1023/A:1007515423169 URL [本文引用: 1]
汉江流域安康站日径流预测的LSTM模型初步研究
[J].
DOI:10.18306/dlkxjz.2020.04.010
[本文引用: 1]
论文基于2003—2014年水文资料,采用长短期记忆神经网络(Long-Short Term Memory,LSTM),构建了汉江上游安康站日径流预测模型,评价了不同输入条件下日径流预测的精度。结果表明:当预见期为1 d时,在仅以安康站前期日径流量作为输入的条件下,LSTM模型在训练期和检验期的效率系数分别达到0.68和0.74;如再将流域前期面雨量和上游石泉站前期日径流量加入LSTM网络作为输入变量,安康站日径流量预测效果将更好,训练期和检验期的效率系数最高可达到0.83和0.84,均方根误差也有显著削减,且对主要洪峰流量的预测能力也有一定提高。此外,LSTM可以有效避免过拟合等问题,具有较好的泛化性能。但当预见期从1 d延长至2、3 d时,LSTM的预测精度显著降低。
Daily runoff predication using LSTM at the Ankang Station, Hanjiang River
River flow forecasting through conceptual models part III: The Ray catchment at Grendon Underwood
[J].DOI:10.1016/0022-1694(70)90098-3 URL [本文引用: 1]
Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation
[J].
World water tower: An atmospheric perspective
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}