1 引言
人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 )。准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力。人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 )。当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 )。遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化。许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 )。但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素。
本文试图利用随机森林模型探索夜间灯光数据、道路网络数据、水域分布数据、建成区数据、数字高程模型和地形坡度数据等空间变量与珠江三角洲人口分布数据之间的关系,利用生成的随机森林模型实现珠江三角洲30 m网格人口空间化,并基于随机森林模型得到的变量因子重要性,分析珠江三角洲人口空间分布的影响因素。
2 研究区域与数据
2.1 研究区域
珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 )。三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 )。1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分。珠江三角洲是全国经济发展最迅速的地区之一。随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 )。
图1 珠江三角洲区位图
Fig.1 Location of the Pearl River Delta
2.2 数据简介
本文使用的数据包括:①2010年的夜间灯光数据,来源于美国国家地理数据中心(http://ngdc.noaa.gov/eog/dmsp/downloadV4composites.html ),采用的是基于F18传感器的2010年夜间非辐射定标平均稳态数据,可见像素值范围为0~63;②珠江三角洲2010年30 m分辨率土地覆盖数据,包括建成区、道路、河流、水体数据,利用2010年Landsat5 TM卫星影像,通过基于面向对象的人机交互目视解译获得,经过与更高分辨率的影像对比及野外核查,分类总体精度达到90%以上;③珠江三角洲90 m分辨率的SRTM数字高程模型及计算的地形坡度数据;④2010年珠江三角洲区县级、广州市镇街级第六次人口普查数据;⑤珠江三角洲区县级行政区划矢量边界及广州市镇街级行政区划矢量边界数据;⑥用于精度检验的公开数据集,包括:a) 2010年的WorldPop数据集,来源于WorldPop项目官网(http://www.worldpop.org.uk ),空间分辨率为100 m;b) 2010年的GPW v4数据集,来源于NASA的社会经济数据和应用中心(http://sedac.ciesin.columbia.edu ),空间分辨率是30弧秒,赤道处约为1 km;c)2010年的中国公里网格人口分布数据集,数据来源于国家科技基础条件平台——国家地球系统科学数据共享平台(http://www.geodata.cn ),空间分辨率为1 km。
2.3 数据预处理
数据预处理主要包括投影转换和人口分布的影响因子的计算。首先将前述所有空间数据投影至统一坐标系统下,然后计算人口分布影响因子,具体步骤如下:
(1) 将河流、水体、道路网和建成区转换成30 m栅格数据,分别与行政区划边界叠加得到二值化栅格数据,即如果一个栅格的土地覆盖类型为河流、水体、道路网和建成区四种类型之一,则该栅格的值为1,否则为0。计算出珠江三角洲范围内每个30 m×30 m网格分别到河流、水体、道路网和建成区的欧氏距离后,再利用珠江三角洲区县级行政区划边界统计每个区县内分别到河流、水体、道路网和建成区的平均距离。
(2) 对于栅格格式的夜间灯光数据、数字高程模型和地形坡度数据,利用珠江三角洲区县级行政区划边界对其统计得到每个区县内的平均夜间灯光强度、平均高程和平均坡度。
(3) 对于道路网和水域,分别统计每个区县内的铁路长度、国道长度、省道长度和县道长度,同时引入路网密度(RSD)和河网密度(WSD)两个评价指标,其中路网密度计算公式为:
RSD = ( 3 × N r + 3 × N ne + 2 × N pe + 1 × N cr ) / A (1)
式中:RSD 为路网密度;N r 、N ne 、N pe 、N cr 分别为各区县内铁路、国家主干道、省级公路、县道长度(km);A 为区县行政单元面积(km2 )。考虑到不同等级公路的运输容量和通行能力的差异,将各等级道路里程换算为标准县道长度,式中系数3、3、2、1分别为铁路、国家主干道、省级公路、县道的换算系数(柏中强, 王卷乐, 杨雅萍等, 2015 )。
河网密度计算公式为
WSD = N w / A (2)
式中:N w 为各个区县内的总河流长度(km);A 为各个区县的面积(km2 )。按照上述方法,统计每个30 m×30 m网格内的铁路长度、国道长度、省道长度、县道长度以及路网密度和河网密度。
(4) 对于人口数据,统计每个区县的土地面积后计算每个区县的人口密度,对结果取对数。
3 研究方法
本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素。相关的技术路线如图2 所示。
图2 技术路线图
Fig.2 Flowchart of spatializing population based on random forest model
3.1 随机森林模型
随机森林是由Leo Breiman和Cutlery Adele在2001年提出的一种分类回归树的数据挖掘方法,是一种组合式的自学习技术(引自张雷等, 2014 )。随机森林中每棵树的训练集是应用bootstrap方法从总训练集中有放回地随机抽样获得。假设有M 个原始变量,对于采集的样本随机选择mtry (mtry <<M )个特征向量作为决策树分裂的候选变量,从这mtry 个候选变量中选择信息含量最丰富的变量进行节点分裂,而且在树的生长过程不进行修剪。按照这种方式生成ntree 棵决策树,然后通过ntree 棵树的反馈进行预测,如果是分类则由多数投票决定,如果是回归则计算平均值。每次未被抽到的样本组成了袋外数据(Out-Of-Bag, OOB),这些袋外数据可用于度量变量因子的重要性,变量重要性的值越大说明该变量因子的重要性越高、越能解释因变量。变量因子重要性的度量方法常用的有两种,分别为平均精度减少法和平均基尼系数下降法。平均精度减少法通过计算袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量来衡量变量的重要性;平均基尼系数下降法则是遍历所有树节点,统计每个特征变量对应的基尼系数下降总和作为该特征的贡献度。OOB数据还可以用于估计模型的性能,Breiman通过实验证明OOB估计是无偏估计(Breiman, 2001a )。
随机森林模型的优点在于:第一,避免了过度拟合。因为在决策树生长过程中bootstrap的采样方法使得每棵决策树不是由全部样本生成,在生成决策树生长过程也不是利用全部变量进行分裂。第二,它对异常值和噪声具有很高的容忍度(Breiman, 2001b ; 方匡南等, 2011 )。第三,它能度量变量的重要性,对于了解影响人口分布的机制有明显的积极作用。第四,随机森林能在运算量没有显著提高的前提下提高预测精度,为快速且准确地实现大范围精细栅格的人口空间化提供有力支撑。同时Stevens等(2015)指出,在人口空间化中使用随机森林模型,需要和GIS行政区域边界匹配得很好的人口普查数据。
基于上述优点,本文在获得珠江三角洲2010年准确的行政边界及第六次人口普查数据的基础上,基于R语言的randomForest包实现利用随机森林模型进行珠江三角洲30 m网格的人口空间化。首先输入样本,以珠江三角洲43个区县的人口密度作为因变量,13个影响因子作为自变量,包括夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度。然后对随机森林模型进行训练,训练时有两个重要的参数:ntree 和mtry 。ntree 表示决策树的数量,mtry 表示决策树分裂时候选变量的个数。由于采样时使用的是bootstrap有放回的采样方法,因此原始训练集中约63.2%的样本被采集,剩余的36.8%样本组成袋外数据,对样本进行交叉验证(方匡南等, 2011 )。所以本文利用OOB无偏估计得到不同参数设置下随机森林模型的精度,进行参数设置(陈凯等, 2015 )。首先确定参数mtry ,在决策树的棵数较大的前提下(ntree =500),测试mtry 不同取值时随机森林模型的精度。如图3 所示,通过OOB无偏估计得到的模型精度随着mtry 的增加先大幅提高后缓慢降低,在mtry =4处取得最大值89.83%,所以本文中mtry 参数设置为4。当mtry =4时,ntree 的增加使得模型精度不断提高,在ntree =500时模型精度达到89.93%,之后精度都接近90%并有小幅度波动(图4 )。综合考虑模型精度与计算机运行性能,本文中ntree 参数设置为500。采用设置好的参数,在珠江三角洲区县级进行随机森林模型的训练,然后将生成的随机森林应用到每个30 m×30 m的网格中,预测每个30 m×30 m网格的人口密度,初步实现珠江三角洲30 m×30 m格网的人口空间化。基于OOB数据,采用平均基尼系数下降法对变量因子进行重要性度量。
图3 模型精度与mtry 之间的关系(ntree =500)
Fig.3 Relationship between model accuracy and predictive variables with 500 trees
图4 模型精度与ntree 之间的关系(mtry =4)
Fig.4 Relationship between model accuracy and ntree with 4 predictive variables
3.2 分区密度制图
由于用随机森林模型估计得到的每个网格的人口数是根据区县级的人口变量因子与人口数生成的随机森林估计,所以实际的人口密度分布需要每个区县的人口总数进行总量控制,按照随机森林得到的每个网格的人口占一个区县所有网格总人口的比例重新分配每个网格的人口数,公式如下:
P i = S j × D i / D j (3)
式中:i 为每个网格,j 为每个行政区,Pi 为每个网格内的人口数;Sj 为该网格所在的行政区的人口总数;Di 为该网格根据随机森林模型估计得到的人口数;Dj 为该网格所在行政区的所有网格根据随机森林模型估计得到的人口总数。
3.3 精度检验
本文模拟30 m网格人口分布是根据区县级人口普查数据进行的人口数据空间化,为反映人口空间化模型的精度水平,选取广州市166个乡镇街道的人口普查数据进行精度检验。将166个乡镇街道按照第六次人口普查数据计算得到的人口密度分成三组:人口密度小于0.5万人/km2 的人口密度低组(72个镇街),介于0.5万人/km2 和5.6万人/km2 之间的人口密度中等组(80个镇街),以及大于5.6万人/km2 的人口密度高组(14个镇街);同时采用平均绝对误差(MAE )、均方根误差(RMSE )和相对均方根误差(%RMSE )来衡量对比每组及全部的人口普查数据与WorldPop数据集、GPW v4数据集、中国公里网格人口分布数据集的精度,并进一步采用Taylor图(Taylor, 2001 )对比本文模拟结果和三种公开数据集。其中MAE 是相对误差取绝对值再算平均,避免了正负相抵消的情况;%RMSE 是通过均方根误差除以人口普查数的平均值得到,可以反映模型模拟的精度高低(Stevens et al, 2015 )。
MAE = 1 N ∑ f i - r i (4)
RMSE = 1 N ∑ f i - r i 2 (5)
%RMSE = RMSE 1 N ∑ r i (6)
式中:fi 是第i 组数据的估算值,即本文进行人口空间化后得到的人口密度估算值;ri 是第i 组数据的参考值,即由人口普查数据得到的人口密度值;N 代表组数数据。
4 结果分析
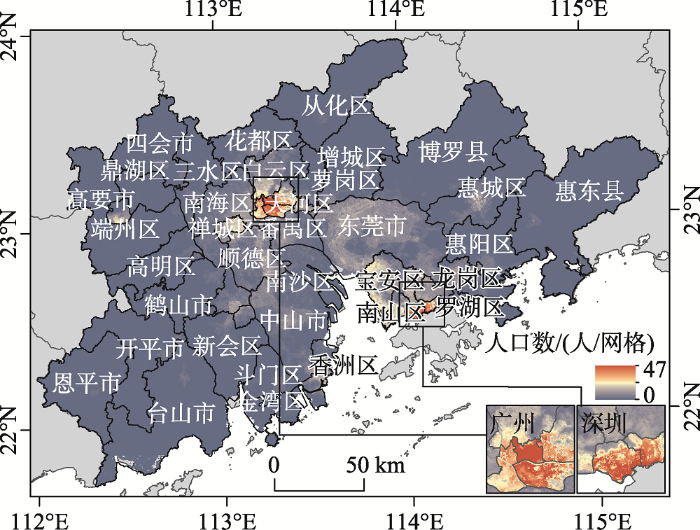
经过随机森林学习及分区密度制图后得到2010年珠江三角洲30 m网格空间分辨率的人口密度分布图(图5 )。2010年珠江三角洲人口分布总体呈现出较显著的“双核心—边缘—外围”结构,人口大量集中分布在广州越秀区、荔湾区、海珠区和天河区以及深圳福田区和罗湖区,最高人口密度出现在广州市越秀区。
图5 2010年珠江三角洲30 m网格空间分辨率的人口分布图
Fig.5 Spatial distribution of population of the Pearl River Delta in 30 m × 30 m grids, 2010
4.1 精度检验
将广州市166个街道进行人口密度空间化结果与WorldPop、GPW、中国公里网格人口数据集三个公开数据集进行对比分析,误差计算结果如表1 所示。由表1 可知,在验证区广州市,本文模拟整体精度达到82.32%,均优于WorldPop数据集以及中国公里网格人口数据集,略低于GPW数据集。在人口密度低的区域,本文的模拟精度低于另外三个数据集;在人口密度中等的区域,本文的模拟精度明显优于另外三个数据集;在人口密度较高的区域,本文的模拟精度明显优于WorldPop数据集以及中国公里网格人口数据集,略低于GPW数据集。
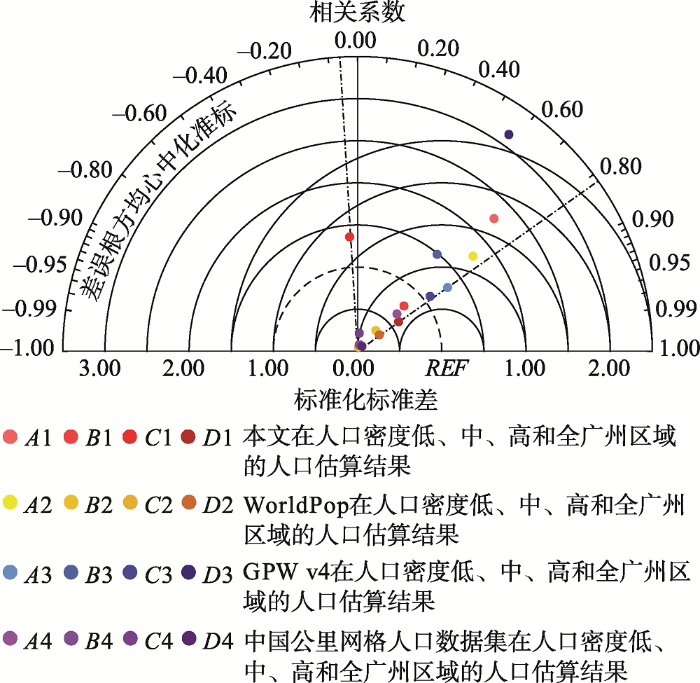
采用Taylor图将本文结果与三个数据集进行对比。图6 中的虚线同心圆弧表示标准化的标准差,实线同心圆弧代表了标准化的中心均方根误差,数据点与圆心的连线与90°的半径所围成扇形的角度代表了相关系数。也就是说,数据点到半径为1的虚线圆弧的距离越近,则它的标准差越小,数据点离实线圆弧的圆心的距离越小,则它的中心均方根误差就越小,数据点与圆心的连线与90°的半径所围成的扇形的角度越大则相关系数越高。总而言之,数据点与REF 点的距离越小则精度越高,距离相等时越接近值为1的虚线圆弧的精度越高。
图6 四个数据集的Taylor图
Fig.6 Taylor diagram of the four datasets
将四个数据集在人口密度较低、中等、较高以及全广州区域的模拟结果分别以点表示在Taylor图上,如图6 所示。可以看出,D 1、D 2、D 3和D 4四个点中,D 1与REF 的距离最近,所以本文的模拟结果是四个数据集中的最优。而且在人口密度中等的区域,即B 1、B 2、B 3和B 4四个点中,B 1与REF 的距离最近,所以B 1的精度优于B 2、B 3、B 4,亦即是本文的模拟结果在人口密度中等的区域优于其他三个数据集。同理,在人口密度较低的区域,本文模拟结果低于其他三个数据集;在人口密度较高的区域,本文的模拟结果均优于WorldPop与中国公里网格人口数据集,略差于GPW数据集。
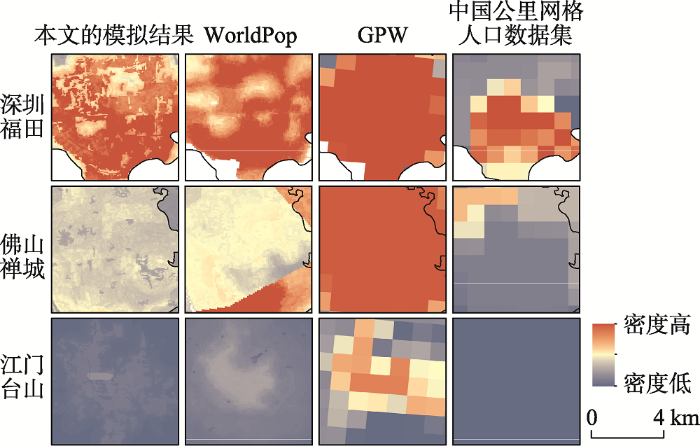
从数据精度分析来看,本文方法的空间化人口数据在广州市乡镇级尺度精度评价结果相比其他三种数据源的提升不明显,但是本文数据空间分辨率的优势是数据能够展示更多空间细节和格局差异。选取人口密度高的深圳福田、人口密度中等的佛山禅城、人口密度低的江门台山进行人口空间化比较结果展示(图7 )。四个数据集的人口密度分布趋势大致相同,但本文30 m格网化结果不管在人口密度高、中或低的区域人口分布异质性更大,而且在同一比例尺下,边缘锯齿状不明显,过渡更加自然符合实际,可以反映更加丰富的人口密度信息。
图7 四个数据集在不同人口密度区域的空间显示效果
Fig.7 Four datasets displayed in space in different density area
4.2 变量因子重要性
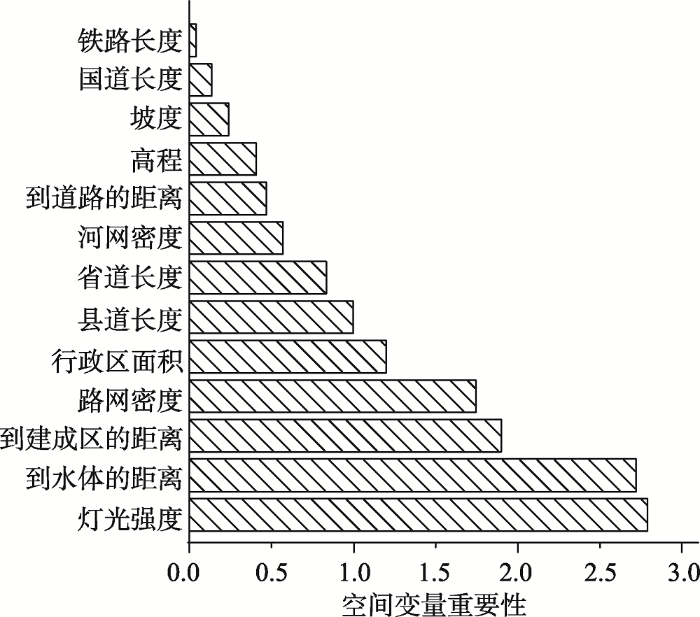
基于随机森林模型的OOB数据得到变量因子重要性值(图8 ),值越大,表明该变量因子作用越大。
图8 随机森林模型生成的变量因子重要性图
Fig.8 Variable importance for random forest regression
从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用。这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 )。改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集。珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素。城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型。路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素。
通过与其他三个人口空间化数据集对比,发现四个数据集的人口分布趋势是相同的,本文的估算值也接近人口普查的人口数,说明本文结果科学合理。30 m空间分辨率的人口分布数据是实现人口、资源、环境和社会经济综合有效管理的基础,为精细化城市管理提供了重要参考,具备实用意义。
5 结论与讨论
本文利用夜间灯光遥感数据、土地覆盖数据、数字高程模型及地形坡度数据,基于随机森林模型,对珠江三角洲区域2010年的人口统计数据进行30 m格网的空间化,利用平均绝对误差、均方根误差和相对均方根误差以及Taylor图分析对模拟结果作精度对比评价,并利用随机森林模型的变量因子重要性分析珠江三角洲人口分布的影响因素。主要结论如下:
(1) 本文模拟整体精度达到82.32%,均优于WorldPop数据集以及中国公里网格人口数据集,接近GPW数据集,而且在人口密度中等区域的模拟精度最高,在人口密度较低或较高区域模拟精度均有所下降。同时本文的最终模拟结果的空间分辨率为30 m,较另外三种公开人口数据能细致地描述珠江三角洲人口分布的空间异质性,同时能满足精细化城市管理的需求以及多种尺度需求的应用。
(2) 夜间灯光强度是珠江三角洲人口分布的最重要指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用。
本文结果与方瑜等(2012) 的研究结果,即地形因子是影响人口分布的重要因素不一致,原因是该研究为全国尺度的,全国地形分为三级阶梯,地形起伏大,而珠江三角洲是冲积平原,大部分区域是平原或丘陵,整体地形比较平缓,高程、坡度略高的区域的气候环境变化不明显,因此地形因子对珠江三角洲区域的人口分布约束较小。
虽然本文整体的模拟精度较高,但在人口密度较低或较高的区域模拟精度不够理想,这可能由于随机森林模型建立时选取的因素不能完全反映人口密度较低或较高的区域的人口分布的特征,因此后续研究可考虑对研究区进行分级建模,同时进一步研究人口分布的机制,更加准确合理地选择变量因子。
The authors have declared that no competing interests exist.
参考文献
文献选项
[1]
柏中强 , 王卷乐 , 姜浩 , 等 . 2015 . 基于多源信息的人口分布格网化方法研究
[J]. 地球信息科学学报 , 17 (6 ): 653 -660 .
https://doi.org/10.3724/SP.J.1047.2015.00653
URL
Magsci
[本文引用: 1]
摘要
<p>格网化人口分布数据比行政单元人口密度数据更易直观表达人口的真实分布状况。本文面向人口格网化管理的区域发展需求, 以延安市为研究对象, 基于增强居民地空间分布及其内部结构信息的理念, 利用乡镇界线和乡镇级人口统计数据为输入控制单元, 以土地利用数据、居民点信息、DEM、夜晚灯光数据等多源信息为指示因子, 采用多元回归建模方法获得了延安市2010年100 m格网人口分布数据。结果表明, 本文采用的人口格网化建模方法最终模型选用变量数少, 决定系数(<em>R</em><sup>2</sup>)达到0.872。最终模型在用于验证的24个乡镇中, 有18个乡镇的估计人口数与统计值误差绝对值小于10%。分析认为, 该建模策略结果可信, 多源的人口分布指示信息在人口格网化方法上明显优于单独的土地利用数据方法。本文获得的100 m格网延安市人口数据格网化结果, 显著增强了人口空间分布的细节信息, 对于县市一级的人口数据格网化具有借鉴意义。</p>
[Bai Z Q Wang J L Jiang H et al. 2015 . The gridding approach to redistribute population based on multi-source data
[J]. Journal of Geo-Information Science , 17 (6 ): 653 -660 .]
https://doi.org/10.3724/SP.J.1047.2015.00653
URL
Magsci
[本文引用: 1]
摘要
<p>格网化人口分布数据比行政单元人口密度数据更易直观表达人口的真实分布状况。本文面向人口格网化管理的区域发展需求, 以延安市为研究对象, 基于增强居民地空间分布及其内部结构信息的理念, 利用乡镇界线和乡镇级人口统计数据为输入控制单元, 以土地利用数据、居民点信息、DEM、夜晚灯光数据等多源信息为指示因子, 采用多元回归建模方法获得了延安市2010年100 m格网人口分布数据。结果表明, 本文采用的人口格网化建模方法最终模型选用变量数少, 决定系数(<em>R</em><sup>2</sup>)达到0.872。最终模型在用于验证的24个乡镇中, 有18个乡镇的估计人口数与统计值误差绝对值小于10%。分析认为, 该建模策略结果可信, 多源的人口分布指示信息在人口格网化方法上明显优于单独的土地利用数据方法。本文获得的100 m格网延安市人口数据格网化结果, 显著增强了人口空间分布的细节信息, 对于县市一级的人口数据格网化具有借鉴意义。</p>
[2]
柏中强 , 王卷乐 , 杨雅萍 , 等 . 2015 . 基于乡镇尺度的中国25省区人口分布特征及影响因素
[J]. 地理学报 , 70 (8 ): 1229 -1242 .
[本文引用: 3]
[Bai Z Q Wang J L Yang Y P et al. 2015 . Characterizing spatial patterns of population distribution at township level across the 25 provinces in China
[J]. Acta Geographica Sinica , 70 (8 ): 1229 -1242 .]
[本文引用: 3]
[3]
陈凯 , 刘凯 , 柳林 , 等 . 2015 . 基于随机森林的元胞自动机城市扩展模拟: 以佛山市为例
[J]. 地理科学进展 , 34 (8 ): 937 -946 .
[本文引用: 1]
[Chen K Liu K Liu L et al. 2015 . Urban expansion simulation by random-forest-based cellular automata: A case study of Foshan City
[J]. Progress in Geography , 34 (8 ): 937 -946 .]
[本文引用: 1]
[4]
陈晴 , 侯西勇 , 吴莉 . 2014 . 基于土地利用数据和夜间灯光数据的人口空间化模型对比分析: 以黄河三角洲高效生态经济区为例
[J]. 人文地理 , 29 (5 ): 94 -100 .
[本文引用: 1]
[Chen Q Hou X Y Wu L. 2014 . Comparing of population spatialization models based on land use data and DMSP/OLS data respectively: A case study in the efficient ecological economic zone of the Yellow River Delta
[J]. Human Geography , 29 (5 ): 94 -100 .]
[本文引用: 1]
[5]
方匡南 , 吴见彬 , 朱建平 , 等 . 2011 . 随机森林方法研究综述
[J]. 统计与信息论坛 , 26 (3 ): 32 -38 .
https://doi.org/10.3969/j.issn.1007-3116.2011.03.006
URL
[本文引用: 2]
摘要
随机森林(RF)是一种统计学习理论,它是利用bootsrap重抽样方法从原始样本中抽取多个样本,对每个bootsrap样本进行决策树建模,然后组合多棵决策树的预测,通过投票得出最终预测结果。它具有很高的预测准确率,对异常值和噪声具有很好的容忍度,且不容易出现过拟合,在医学、生物信息、管理学等领域有着广泛的应用。为此,介绍了随机森林原理及其有关性质,讨论其最新的发展情况以及一些重要的应用领域。
[Fang K N Wu J B Zhu J P et al. 2011 . A review of technologies on random forests
[J]. Statistics & Information Forum , 26 (3 ): 32 -38 .]
https://doi.org/10.3969/j.issn.1007-3116.2011.03.006
URL
[本文引用: 2]
摘要
随机森林(RF)是一种统计学习理论,它是利用bootsrap重抽样方法从原始样本中抽取多个样本,对每个bootsrap样本进行决策树建模,然后组合多棵决策树的预测,通过投票得出最终预测结果。它具有很高的预测准确率,对异常值和噪声具有很好的容忍度,且不容易出现过拟合,在医学、生物信息、管理学等领域有着广泛的应用。为此,介绍了随机森林原理及其有关性质,讨论其最新的发展情况以及一些重要的应用领域。
[6]
方瑜 , 欧阳志云 , 郑华 , 等 . 2012 . 中国人口分布的自然成因
[J]. 应用生态学报 , 23 (12 ): 3488 -3495 .
URL
Magsci
[本文引用: 2]
摘要
<p>中国多样化的自然环境造就了人口分布的区域差异性,明晰人口分布格局与自然环境的相互关系对于增进对人地关系的理解,实现人口、资源、环境的可持续管理具有重要作用.本文以人口密度为指标,采用洛伦兹曲线与空间统计相结合的方法,分析了中国人口分布状况,并探讨了自然因素组合对人口分布的影响以及人口分布与年均温度、年均降水量、干燥度、净初级生产力、地表粗糙度、距海岸线距离等16个指标的相互关系.结果表明: 中国人口分布集聚现象显著,东、中、西部地区分别以高、中、低人口密度为主,空间上呈现出明显的正空间关联特征;人口密度与河网密度、年均温度、年均降水量、净初级生产力、≥5 ℃积温、降水量变异、相对湿度、温暖指数呈极显著的正相关关系,与相对高差、平均高程、日照时数、地表粗糙度、距海岸线距离呈显著负相关;气候因子(年均温度、温暖指数、降水量变异、净初级生产力)、地形因子(地表粗糙度、相对高差)和水系因子(河网密度)为影响人口分布的主要自然因素.建议加强对东部高人口密度区的生态环境监控,避免因人口增长导致生态环境退化;同时,强调对中西部生态环境脆弱地区的生态环境保育,增强这些地区的人口承载能力,减缓东部地区高人口密度的生态环境压力.</p>
[Fang Y Ouyang Z Y Zheng H et al. 2012 . Natural forming causes of China population distribution
[J]. Chinese Journal of Applied Ecology , 23 (12 ): 3488 -3495 .]
URL
Magsci
[本文引用: 2]
摘要
<p>中国多样化的自然环境造就了人口分布的区域差异性,明晰人口分布格局与自然环境的相互关系对于增进对人地关系的理解,实现人口、资源、环境的可持续管理具有重要作用.本文以人口密度为指标,采用洛伦兹曲线与空间统计相结合的方法,分析了中国人口分布状况,并探讨了自然因素组合对人口分布的影响以及人口分布与年均温度、年均降水量、干燥度、净初级生产力、地表粗糙度、距海岸线距离等16个指标的相互关系.结果表明: 中国人口分布集聚现象显著,东、中、西部地区分别以高、中、低人口密度为主,空间上呈现出明显的正空间关联特征;人口密度与河网密度、年均温度、年均降水量、净初级生产力、≥5 ℃积温、降水量变异、相对湿度、温暖指数呈极显著的正相关关系,与相对高差、平均高程、日照时数、地表粗糙度、距海岸线距离呈显著负相关;气候因子(年均温度、温暖指数、降水量变异、净初级生产力)、地形因子(地表粗糙度、相对高差)和水系因子(河网密度)为影响人口分布的主要自然因素.建议加强对东部高人口密度区的生态环境监控,避免因人口增长导致生态环境退化;同时,强调对中西部生态环境脆弱地区的生态环境保育,增强这些地区的人口承载能力,减缓东部地区高人口密度的生态环境压力.</p>
[7]
高义 , 王辉 , 王培涛 , 等 . 2013 . 基于人口普查与多源夜间灯光数据的海岸带人口空间化分析
[J]. 资源科学 , 35 (12 ): 2517 -2523 .
URL
[本文引用: 1]
摘要
我国海岸带区域是台风、风暴潮、地震海啸和海岸侵蚀等海洋灾害的重灾区,精细空间分辨率的人口数据,能够有效服务海岸带灾害风险管理.本文基于我国第六次人口普查资料、OLS/DMSP和NPP/VIIRS DNB两种夜间灯光数据及Landsat卫星遥感影像,综合利用遥感与地理信息系统理论与技术,进行了我国海岸带人口空间化方法与应用研究.利用建筑物与裸地增强指数法(EBBI)基于Landsat卫星遥感影像提取了我国沿海区县建成区数据,作为人口分布的空间控制因素,以普查人口数与夜间灯光数据回归函数关系为依据,对人口进行空间化处理.反演得到了我国海岸带区县1km×1km和0.5km×0.5km两个空间尺度的人口格网数据.并利用福建省沿海乡镇人口数据对人口空间化结果进行了精度评价.研究结果表明NPP/VIIRS DNB夜间灯光数据适用于人口空间化研究,且其反演精度整体优于基于DMSP/OLS传统夜间灯光数据反演的人口格网模型.通过本文实践,可以发现NPP/VIIRS DNB夜间灯光数据具有实现人口和社会经济数据空间化的巨大潜力.
[Gao Y Wang H Wang P T et al. 2013 . Population spatial processing for Chinese coastal zones based on census and multiple night light data
[J]. Resources Science , 35 (12 ): 2517 -2523 .]
URL
[本文引用: 1]
摘要
我国海岸带区域是台风、风暴潮、地震海啸和海岸侵蚀等海洋灾害的重灾区,精细空间分辨率的人口数据,能够有效服务海岸带灾害风险管理.本文基于我国第六次人口普查资料、OLS/DMSP和NPP/VIIRS DNB两种夜间灯光数据及Landsat卫星遥感影像,综合利用遥感与地理信息系统理论与技术,进行了我国海岸带人口空间化方法与应用研究.利用建筑物与裸地增强指数法(EBBI)基于Landsat卫星遥感影像提取了我国沿海区县建成区数据,作为人口分布的空间控制因素,以普查人口数与夜间灯光数据回归函数关系为依据,对人口进行空间化处理.反演得到了我国海岸带区县1km×1km和0.5km×0.5km两个空间尺度的人口格网数据.并利用福建省沿海乡镇人口数据对人口空间化结果进行了精度评价.研究结果表明NPP/VIIRS DNB夜间灯光数据适用于人口空间化研究,且其反演精度整体优于基于DMSP/OLS传统夜间灯光数据反演的人口格网模型.通过本文实践,可以发现NPP/VIIRS DNB夜间灯光数据具有实现人口和社会经济数据空间化的巨大潜力.
[8]
康停军 , 张新长 , 赵元 , 等 . 2012 . 基于多智能体的城市人口分布模型
[J]. 地理科学 , 32 (7 ): 790 -797 .
URL
Magsci
[本文引用: 1]
摘要
人口是城市发展中最为活跃的因素,快速增长的人口给城市安全、经济和生态环境带来了深远的影响,获取不同尺度的高精度人口空间分布信息对于城市安全管理、提高资源环境的综合管理能力具有非常重要的意义。针对常用的城市人口空间分布模拟方法存在的不足,构建了基于多智能体的城市人口分布模型,模型由影响要素、智能体、决策规则等组成。在两个不同尺度区域进行了模型应用实验,并以重力模型进行了对比分析。实验结果表明,与重力模型相比,此模型所模拟的结果具有更高的精度,且接近于实际的人口空间分布,为城市人口分布模拟提供了新的思路。
[Kang T J Zhang X C Zhao Y et al. 2012 . Agent-based urban population distribution model
[J]. Scientia Geographica Sinica , 32 (7 ): 790 -797 .]
URL
Magsci
[本文引用: 1]
摘要
人口是城市发展中最为活跃的因素,快速增长的人口给城市安全、经济和生态环境带来了深远的影响,获取不同尺度的高精度人口空间分布信息对于城市安全管理、提高资源环境的综合管理能力具有非常重要的意义。针对常用的城市人口空间分布模拟方法存在的不足,构建了基于多智能体的城市人口分布模型,模型由影响要素、智能体、决策规则等组成。在两个不同尺度区域进行了模型应用实验,并以重力模型进行了对比分析。实验结果表明,与重力模型相比,此模型所模拟的结果具有更高的精度,且接近于实际的人口空间分布,为城市人口分布模拟提供了新的思路。
[9]
李玲 , 沈静 , 袁媛 . 2008 . 人口发展与区域规划 [M]. 北京 : 科学出版社 .
[本文引用: 1]
[Li L Shen J Yuan Y. 2008 . Renkou fazhan yu quyu guihua [M]. Beijing , China: Science Press .]
[本文引用: 1]
[10]
廖顺宝 , 孙九林 . 2003 . 基于GIS的青藏高原人口统计数据空间化
[J]. 地理学报 , 58 (1 ): 25 -33 .
https://doi.org/10.3321/j.issn:0375-5444.2003.01.004
URL
[本文引用: 2]
摘要
根据2000年第5次全国人口普查数据分析,西藏、青海2省区各市县平均人口密度与海拔高度、土地利用、主要道路有较强的相关关系,河流水系对居民点分布的影响较为明显,而居民点是人口分布的重要指示因子.以GIS软件为工具,通过较为客观的方式赋予各影响因子人口分布影响权重,运用多源数据融合技术进行了人口统计数据的空间化.结果显示,通过数据融合产生的人口密度与各市县实际人口密度的相关系数大于0.80,与试验区各乡镇的实际人口密度的相关系数大于 0.75.最终生成的栅格人口密度数据既与各市县统计型人口数据保持一致,又反映了各市县内部人口分布的空间变化.
[Liao S B Sun J L. 2003 . GIS based spatialization of population census data in Qinghai-Tibet Plateau
[J]. Acta Geographica Sinica , 58 (1 ): 25 -33 .]
https://doi.org/10.3321/j.issn:0375-5444.2003.01.004
URL
[本文引用: 2]
摘要
根据2000年第5次全国人口普查数据分析,西藏、青海2省区各市县平均人口密度与海拔高度、土地利用、主要道路有较强的相关关系,河流水系对居民点分布的影响较为明显,而居民点是人口分布的重要指示因子.以GIS软件为工具,通过较为客观的方式赋予各影响因子人口分布影响权重,运用多源数据融合技术进行了人口统计数据的空间化.结果显示,通过数据融合产生的人口密度与各市县实际人口密度的相关系数大于0.80,与试验区各乡镇的实际人口密度的相关系数大于 0.75.最终生成的栅格人口密度数据既与各市县统计型人口数据保持一致,又反映了各市县内部人口分布的空间变化.
[11]
刘志佳 , 黄河清 . 2015 . 珠三角地区建设用地扩张与经济、人口变化之间相互作用的时空演变特征分析
[J]. 资源科学 , 37 (7 ): 1394 -1402 .
URL
Magsci
[本文引用: 1]
摘要
改革开放以来珠三角地区社会经济发展迅速,城市建设用地急剧扩张,同时这些变化之间呈现出既相互依赖又相互制约的复杂关系。通过对1979-2009年间遥感影像的分类解译,获得珠三角地区四期间隔为10年左右的土地利用变化数据,结合生产总值、常住人口等统计数据,定量分析过去30年来珠三角地区城市建设用地扩张、生产总值、常住人口的时空变化及其相互作用关系演变特征,结果表明:①珠三角地区的建设用地面积占地区总土地面积的比重已从0.5%上升到了10.8%,其中深圳、东莞已超过了40%,这些建设用地的增加主要是以农业用地的减少为代价;②珠三角地区常住人口与经济增长有明显的相关性:2000年以前人口每增长1万人,经济增长3.2亿元;2000年以后变为16.2亿元/万人;③整个区域尺度上常住人口、生产总值与建设用地具有很好的线性关系。根据线性回归方程,珠三角地区的常住人口每增长1万人,城市建设用地面积大约增长0.99km<sup>2</sup>;生产总值每增长1亿元,城市建设用地面积增长约0.16km<sup>2</sup>。但是生产总值与建设用地呈现出复杂的关系:在城市扩张的初期,经济增长中土地资源的贡献度较大,生产总值与建设用地表现出紧密的幂函数关系;随着经济的发展和产业结构升级转型,土地资源的贡献度逐渐下降,经济增长与建设用地扩张的相关性显著下降。
[Liu Z J Huang H Q. 2015 . Tempo-spatial characteristics of interactions among changes in built-up land, GDP and demography in the Pearl River Delta
[J]. Resources Science , 37 (7 ): 1394 -1402 .]
URL
Magsci
[本文引用: 1]
摘要
改革开放以来珠三角地区社会经济发展迅速,城市建设用地急剧扩张,同时这些变化之间呈现出既相互依赖又相互制约的复杂关系。通过对1979-2009年间遥感影像的分类解译,获得珠三角地区四期间隔为10年左右的土地利用变化数据,结合生产总值、常住人口等统计数据,定量分析过去30年来珠三角地区城市建设用地扩张、生产总值、常住人口的时空变化及其相互作用关系演变特征,结果表明:①珠三角地区的建设用地面积占地区总土地面积的比重已从0.5%上升到了10.8%,其中深圳、东莞已超过了40%,这些建设用地的增加主要是以农业用地的减少为代价;②珠三角地区常住人口与经济增长有明显的相关性:2000年以前人口每增长1万人,经济增长3.2亿元;2000年以后变为16.2亿元/万人;③整个区域尺度上常住人口、生产总值与建设用地具有很好的线性关系。根据线性回归方程,珠三角地区的常住人口每增长1万人,城市建设用地面积大约增长0.99km<sup>2</sup>;生产总值每增长1亿元,城市建设用地面积增长约0.16km<sup>2</sup>。但是生产总值与建设用地呈现出复杂的关系:在城市扩张的初期,经济增长中土地资源的贡献度较大,生产总值与建设用地表现出紧密的幂函数关系;随着经济的发展和产业结构升级转型,土地资源的贡献度逐渐下降,经济增长与建设用地扩张的相关性显著下降。
[12]
苏飞 , 张平宇 . 2010 . 辽中南城市群人口分布的时空演变特征
[J]. 地理科学进展 , 29 (1 ): 96 -102 .
https://doi.org/10.11820/dlkxjz.2010.01.013
URL
Magsci
[本文引用: 1]
摘要
<p>采用人口分布的结构指数和空间自相关分析方法,并结合GIS技术对20世纪90年代以来辽中南城市群人口分布的时空演变特征进行分析。研究结果表明:① 2007年,辽中南城市群的人口分布具有各地市人口总量差异较大、人口密度呈西高东低态势、市县人口密度差异显著、人口沿交通轴线集中分布、人口分布的局部空间集聚现象十分显著等现状特征;② 20世纪90年代以来,城市群的人口分布变化具有各地市人口增幅差异明显、人口分布具有不断集中趋势、人口重心逐渐由东北向西南方向移动,人口分布趋同趋势不断增强等演变特征。研究结果表明空间自相关的统计分析方法能够更好地揭示出人口的分布特征、人口集聚及其变化的热点,对于人口的合理布局方案等政府决策具有重要的参考价值。</p>
[Su F Zhang P Y. 2010 . Spatio-temporal dynamics of population distribution in the middle and southern Liaoning Urban Agglomeration
[J]. Progress in Geography , 29 (1 ): 96 -102 .]
https://doi.org/10.11820/dlkxjz.2010.01.013
URL
Magsci
[本文引用: 1]
摘要
<p>采用人口分布的结构指数和空间自相关分析方法,并结合GIS技术对20世纪90年代以来辽中南城市群人口分布的时空演变特征进行分析。研究结果表明:① 2007年,辽中南城市群的人口分布具有各地市人口总量差异较大、人口密度呈西高东低态势、市县人口密度差异显著、人口沿交通轴线集中分布、人口分布的局部空间集聚现象十分显著等现状特征;② 20世纪90年代以来,城市群的人口分布变化具有各地市人口增幅差异明显、人口分布具有不断集中趋势、人口重心逐渐由东北向西南方向移动,人口分布趋同趋势不断增强等演变特征。研究结果表明空间自相关的统计分析方法能够更好地揭示出人口的分布特征、人口集聚及其变化的热点,对于人口的合理布局方案等政府决策具有重要的参考价值。</p>
[13]
王鹤饶 , 郑新奇 , 袁涛 . 2012 . DMSP/OLS数据应用研究综述
[J]. 地理科学进展 , 31 (1 ): 11 -19 .
https://doi.org/10.11820/dlkxjz.2012.01.002
URL
[本文引用: 1]
摘要
DMSP/OLS夜间灯光数据主要包括稳定灯光数据、辐射标定夜间灯光强度数据、非辐射标定夜间灯光强度数据3种产品。该数据产品具有获取容易、能够探测低强度灯光、不受光线阴影影响、方便为城市化强度及其时空分异分析提供条件等优点。目前,关于DMSP/OLS数据的研究成果已有很多,主要集中于城市发展研究、人类活动及效应研究、生态环境影响研究等方面,但对成果的系统归纳总结性研究却几乎没有。基于此,本文分析比较了现有DMSP/OLS数据研究实例,针对已有成果研究目的、技术方法以及方法优缺点等进行归纳总结,探索DMSP/OLS夜间灯光平均强度数据的应用前景。最后,总结了该数据的未来研究趋势:①对数据本身处理方法深入研究;②数据应用领域应进一步扩展;③DMSP/OLS数据与其他数据模型的集成研究应进一步深化;④将现有研究成果结合,进一步研究地理现象机制问题。
[Wang H R Zheng X Q Yuan T. 2012 . Overview of researches based on DMSP/OLS nighttime light data
[J]. Progress in Geography , 31 (1 ): 11 -19 .]
https://doi.org/10.11820/dlkxjz.2012.01.002
URL
[本文引用: 1]
摘要
DMSP/OLS夜间灯光数据主要包括稳定灯光数据、辐射标定夜间灯光强度数据、非辐射标定夜间灯光强度数据3种产品。该数据产品具有获取容易、能够探测低强度灯光、不受光线阴影影响、方便为城市化强度及其时空分异分析提供条件等优点。目前,关于DMSP/OLS数据的研究成果已有很多,主要集中于城市发展研究、人类活动及效应研究、生态环境影响研究等方面,但对成果的系统归纳总结性研究却几乎没有。基于此,本文分析比较了现有DMSP/OLS数据研究实例,针对已有成果研究目的、技术方法以及方法优缺点等进行归纳总结,探索DMSP/OLS夜间灯光平均强度数据的应用前景。最后,总结了该数据的未来研究趋势:①对数据本身处理方法深入研究;②数据应用领域应进一步扩展;③DMSP/OLS数据与其他数据模型的集成研究应进一步深化;④将现有研究成果结合,进一步研究地理现象机制问题。
[14]
王静 , 杨小唤 , 石瑞香 . 2012 . 山东省人口空间分布格局的多尺度分析
[J]. 地理科学进展 , 31 (2 ): 176 -182 .
https://doi.org/10.11820/dlkxjz.2012.02.006
URL
Magsci
[本文引用: 1]
摘要
人口空间分布具有一定的尺度依赖性,从不同尺度上对人口空间分布格局进行分析,可以更确切、真实地揭示人口的空间分布规律,为制定区域发展规划、灾害评价、环境保护等提供科学依据。本文以山东省为研究区,运用空间自相关方法和统计相关分析方法,比较市级、县级、1 km三个尺度上人口分布的空间自相关性及其与环境—经济因子的统计相关性,试图探讨不同尺度下人口的空间分布模式及影响(指示)因素,从不同尺度揭示人口的空间分布格局特征。结果表明:①从不同尺度对人口的空间分布格局进行分析,可以得到从宏观到微观不同详细程度的信息。从市级尺度分析,可以得到山东省整体的人口空间分布特征;从县级尺度分析,可以得到山东省各市内部的人口空间分布特征;从1 km尺度分析,可以得到山东省各县内部的人口空间分布特征。②不同尺度上,人口的空间分布格局特征不同。市级和县级尺度上,人口分布受环境—经济因子的影响表现出与一些因子显著相关,而受空间集聚的作用较小;1 km尺度上,人口分布与环境—经济因子的相关性较小,而主要受空间集聚的作用,在县内部,人口往往集中分布于某一区域,呈现出典型的集聚分布模式。
[Wang J Yang X H Shi R X. 2012 . Spatial distribution of the population in Shandong Province at multi-scales
[J]. Progress in Geography , 31 (2 ): 176 -182 .]
https://doi.org/10.11820/dlkxjz.2012.02.006
URL
Magsci
[本文引用: 1]
摘要
人口空间分布具有一定的尺度依赖性,从不同尺度上对人口空间分布格局进行分析,可以更确切、真实地揭示人口的空间分布规律,为制定区域发展规划、灾害评价、环境保护等提供科学依据。本文以山东省为研究区,运用空间自相关方法和统计相关分析方法,比较市级、县级、1 km三个尺度上人口分布的空间自相关性及其与环境—经济因子的统计相关性,试图探讨不同尺度下人口的空间分布模式及影响(指示)因素,从不同尺度揭示人口的空间分布格局特征。结果表明:①从不同尺度对人口的空间分布格局进行分析,可以得到从宏观到微观不同详细程度的信息。从市级尺度分析,可以得到山东省整体的人口空间分布特征;从县级尺度分析,可以得到山东省各市内部的人口空间分布特征;从1 km尺度分析,可以得到山东省各县内部的人口空间分布特征。②不同尺度上,人口的空间分布格局特征不同。市级和县级尺度上,人口分布受环境—经济因子的影响表现出与一些因子显著相关,而受空间集聚的作用较小;1 km尺度上,人口分布与环境—经济因子的相关性较小,而主要受空间集聚的作用,在县内部,人口往往集中分布于某一区域,呈现出典型的集聚分布模式。
[15]
王珂靖 , 蔡红艳 , 杨小唤 . 2016 . 多元统计回归及地理加权回归方法在多尺度人口空间化研究中的应用
[J]. 地理科学进展 , 35 (12 ): 1494 -1505 .
[本文引用: 1]
[Wang K J Cai H Y Yang X H. 2016 . Multiple scale spatialization of demographic data with multi-factor linear regression and geographically weighted regression models
[J]. Progress in Geography , 35 (12 ): 1494 -1505 .]
[本文引用: 1]
[16]
肖荣波 , 丁琛 . 2011 . 城市规划中人口空间分布模拟方法研究
[J]. 中国人口·资源与环境 , 21 (6 ): 13 -18 .
[本文引用: 1]
[Xiao R B Ding C. 2011 . Modeling spatial distribution of population density for urban planning
[J]. China Population Resources and Environment , 21 (6 ): 13 -18 .]
[本文引用: 1]
[17]
张建辰 , 王艳慧 . 2014 . 基于土地利用类型的村级人口空间分布模拟: 以湖北鹤峰县为例
[J]. 地球信息科学学报 , 16 (3 ): 435 -442 .
https://doi.org/10.3724/SP.J.1047.2014.00435
URL
Magsci
[本文引用: 1]
摘要
<p>在人口分布及其相关研究中,常常会遇到小尺度人口数据部分缺失的问题。本文以湖北省鹤峰县为例,在分析土地利用与人口分布关系的基础上,从全局与局部、线性回归与非线性回归考虑,基于土地利用类型,分别利用地理加权回归(GWR)方法、格网方法、BP神经网络方法对缺失数据的行政村人口数据进行模拟,并进行了多角度精度对比验证。研究结果表明:(1)各种土地利用类型中,耕地、林地、城镇村及工矿用地、交通用地是影响研究区村级人口分布的主要因素;(2)30个调查村中,3种方法模拟的人口总数误差小于3%,通过每个村的模拟值与实际值相比,BP神经网络方法能更好地模拟研究区村级人口的分布,格网方法次之,GWR方法最差;(3)研究区各村人口分布呈现较高的空间正相关性,各乡镇的人口密度在空间上并不独立,而是呈现紧密的集聚特征。</p>
[Zhang J C Wang Y H. 2014 . Simulation of village-level population distribution based on land use: A case study of Hefeng County in Hubei Province
[J]. Journal of Geo-Information Science , 16 (3 ): 435 -442 .]
https://doi.org/10.3724/SP.J.1047.2014.00435
URL
Magsci
[本文引用: 1]
摘要
<p>在人口分布及其相关研究中,常常会遇到小尺度人口数据部分缺失的问题。本文以湖北省鹤峰县为例,在分析土地利用与人口分布关系的基础上,从全局与局部、线性回归与非线性回归考虑,基于土地利用类型,分别利用地理加权回归(GWR)方法、格网方法、BP神经网络方法对缺失数据的行政村人口数据进行模拟,并进行了多角度精度对比验证。研究结果表明:(1)各种土地利用类型中,耕地、林地、城镇村及工矿用地、交通用地是影响研究区村级人口分布的主要因素;(2)30个调查村中,3种方法模拟的人口总数误差小于3%,通过每个村的模拟值与实际值相比,BP神经网络方法能更好地模拟研究区村级人口的分布,格网方法次之,GWR方法最差;(3)研究区各村人口分布呈现较高的空间正相关性,各乡镇的人口密度在空间上并不独立,而是呈现紧密的集聚特征。</p>
[18]
张雷 , 王琳琳 , 张旭东 , 等 . 2014 . 随机森林算法基本思想及其在生态学中的应用: 以云南松分布模拟为例
[J]. 生态学报 , 34 (3 ): 650 -659 .
[本文引用: 1]
[Zhang L Wang L L Zhang X D et al. 2014 . The basic principle of random forest and its applications in ecology: A case study of Pinus yunnanensis
[J]. Acta Ecologica Sinica , 34 (3 ): 650 -659 .]
[本文引用: 1]
[19]
周成虎 , 欧阳 , 马廷 . 2009 . 地理格网模型研究进展
[J]. 地理科学进展 , 28 (5 ): 657 -662 .
https://doi.org/10.11820/dlkxjz.2009.05.002
URL
Magsci
[本文引用: 1]
摘要
<p>地理格网系统起源于早期的制图研究,并发展成为表达复杂地理现象、综合分析自然与人文数据、模拟地理系统功能与行为的基本方法。地理格网系统的组成包括格元、格边和格点,格元代表了区域面状特征,格点确定了格元的基本位置和点状特征,格边用于度量格元间的通量关系。在现代地球测量技术驱动下,地理格网系统的功能从传统的地图定位框架与地理现象表达,进一步拓展出多源地理空间数据融合、地理综合分析等新功能。研究椭球空间下的地理格网系统构建模型、误差分布、地学计算等是地理格网系统研究的前沿和基础性科学问题。</p>
[Zhou C H Ou Y Ma T. 2009 . Progresses of geographical grid systems researches
[J]. Progress in Geography , 28 (5 ): 657 -662 .]
https://doi.org/10.11820/dlkxjz.2009.05.002
URL
Magsci
[本文引用: 1]
摘要
<p>地理格网系统起源于早期的制图研究,并发展成为表达复杂地理现象、综合分析自然与人文数据、模拟地理系统功能与行为的基本方法。地理格网系统的组成包括格元、格边和格点,格元代表了区域面状特征,格点确定了格元的基本位置和点状特征,格边用于度量格元间的通量关系。在现代地球测量技术驱动下,地理格网系统的功能从传统的地图定位框架与地理现象表达,进一步拓展出多源地理空间数据融合、地理综合分析等新功能。研究椭球空间下的地理格网系统构建模型、误差分布、地学计算等是地理格网系统研究的前沿和基础性科学问题。</p>
[20]
周春山 , 金万富 , 史晨怡 . 2015 . 新时期珠江三角洲城市群发展战略的思考
[J]. 地理科学进展 , 34 (3 ): 302 -312 .
URL
Magsci
[本文引用: 1]
摘要
近年来,国内外经济形势发生显著变化,以传统制造业为主的珠三角城市群面临新的挑战,珠三角下一步如何发展成为必须解决的新问题。现状,将其与国内外城市群对比,提出了珠三角发展战略思路。研究结果表明:2000-2013年期间,珠三角城市群经济发展速度有所降低,区域经济发展差距逐渐缩小;人口红利面临枯竭;产业结构向高级化转变,经济全球化程度下降等;珠三角城市群发展水平和竞争力与国外世界级城市群相比差距较大;与国内长三角、京津冀城市群相比,总体发展势头下降。在此背景下,应将产业技术创新、土地节约集约利用、人口政策创新、区域合作与人文引领作为新时期珠三角城市群发展战略的主要方向。
[Zhou C S Jin W F Shi C Y. 2015 . Development strategy of the Pearl River Delta Urban Agglomeration under the current socioeconomic situation
[J]. Progress in Geography , 34 (3 ): 302 -312 .]
URL
Magsci
[本文引用: 1]
摘要
近年来,国内外经济形势发生显著变化,以传统制造业为主的珠三角城市群面临新的挑战,珠三角下一步如何发展成为必须解决的新问题。现状,将其与国内外城市群对比,提出了珠三角发展战略思路。研究结果表明:2000-2013年期间,珠三角城市群经济发展速度有所降低,区域经济发展差距逐渐缩小;人口红利面临枯竭;产业结构向高级化转变,经济全球化程度下降等;珠三角城市群发展水平和竞争力与国外世界级城市群相比差距较大;与国内长三角、京津冀城市群相比,总体发展势头下降。在此背景下,应将产业技术创新、土地节约集约利用、人口政策创新、区域合作与人文引领作为新时期珠三角城市群发展战略的主要方向。
[21]
珠江三角洲城市群年鉴编纂委员会 . 2015 . 珠江三角洲城市群年鉴2015 [M]. 广州 : 广东人民出版社 .
[本文引用: 1]
[Urban Agglomeration in the Pearl River Delta Yearbook Committee Compilation . 2015 . Urban Agglomeration in the Pearl River Delta yearbook 2015 [M]. Guangzhou, China : Guangdong People's Publishing House .]
[本文引用: 1]
[22]
卓莉 , 黄信锐 , 陶海燕 , 等 . 2014 . 基于多智能体模型与建筑物信息的高空间分辨率人口分布模拟
[J]. 地理研究 , 33 (3 ): 520 -531 .
https://doi.org/10.11821/dlyj201403011
URL
[本文引用: 1]
摘要
自上而下的人口分布模拟模型自动化程度较低,难以分析人口分布成因,且因精细尺度的人口样本较难获取而不太适用于高空间分辨率人口分布模拟。提出了一种基于多智能体模型和建筑物信息的高空间分辨率人口分布模拟模型。首先利用建筑物三维分布数据提取住宅建筑,构建智能体人口分布模拟模型的环境;然后基于统计、调研数据定义智能体属性,确定智能体居住选择行为规则;最后以泰日社区为例进行了居住人口分布仿真模拟。研究结果表明,基于建筑物信息的人口分布多智能体模型,可以获取每栋建筑物上的人口,改进了当前高分辨率人口模拟主要只模拟小区或者居委会人口的不足;多智能体模型具有较高的自动化程度,不仅能获得较好的模拟结果,而且可在一定程度上从微观机理解释宏观居住分布模式,是对传统统计模型的有益补充。
[Zhuo L Huang X R Tao H Y et al. 2014 . High spatial resolution population distribution simulation based on building information and multi-agent
[J]. Geographical Research , 33 (3 ): 520 -531 .]
https://doi.org/10.11821/dlyj201403011
URL
[本文引用: 1]
摘要
自上而下的人口分布模拟模型自动化程度较低,难以分析人口分布成因,且因精细尺度的人口样本较难获取而不太适用于高空间分辨率人口分布模拟。提出了一种基于多智能体模型和建筑物信息的高空间分辨率人口分布模拟模型。首先利用建筑物三维分布数据提取住宅建筑,构建智能体人口分布模拟模型的环境;然后基于统计、调研数据定义智能体属性,确定智能体居住选择行为规则;最后以泰日社区为例进行了居住人口分布仿真模拟。研究结果表明,基于建筑物信息的人口分布多智能体模型,可以获取每栋建筑物上的人口,改进了当前高分辨率人口模拟主要只模拟小区或者居委会人口的不足;多智能体模型具有较高的自动化程度,不仅能获得较好的模拟结果,而且可在一定程度上从微观机理解释宏观居住分布模式,是对传统统计模型的有益补充。
[23]
Breiman L. 2001 a. Random forests
[J]. Machine Learning , 45 (1 ): 5 -32 .
https://doi.org/10.1023/A:1010933404324
URL
[本文引用: 1]
[24]
Breiman L. 2001 b. Statistical modeling: The two cultures
[J]. Statistical Science , 16 (3 ): 199 -231 .
URL
[本文引用: 1]
[25]
Gaughan A E Stevens F R Huang Z J et al. 2016 . Spatiotemporal patterns of population in mainland China, 1990 to 2010
[J]. Scientific Data , 3 : 160005 .
https://doi.org/10.1038/sdata.2016.5
URL
PMID: 26881418
[本文引用: 3]
摘要
According to UN forecasts, global population will increase to over 8 billion by 2025, with much of this anticipated population growth expected in urban areas. In China, the scale of urbanization has, and continues to be, unprecedented in terms of magnitude and rate of change. Since the late 1970s, the percentage of Chinese living in urban areas increased from ~18% to over 50%. To quantify these patterns spatially we use time-invariant or temporally-explicit data, including census data for 1990, 2000, and 2010 in an ensemble prediction model. Resulting multi-temporal, gridded population datasets are unique in terms of granularity and extent, providing fine-scale (~100?m) patterns of population distribution for mainland China. For consistency purposes, the Tibet Autonomous Region, Taiwan, and the islands in the South China Sea were excluded. The statistical model and considerations for temporally comparable maps are described, along with the resulting datasets. Final, mainland China population maps for 1990, 2000, and 2010 are freely available as products from the WorldPop Project website and the WorldPop Dataverse Repository.
[26]
Martin D. 1989 . Mapping population data from zone centroid locations
[J]. Transactions of the Institute of British Geographers , 14 (1 ): 90 -97 .
https://doi.org/10.2307/622344
URL
PMID: 12281689
[本文引用: 1]
摘要
Abstract The author describes the difficulties associated with the use of maps to represent census data. "A review of the problems associated with population mapping is followed by a discussion of [an alternative method known as] a raster method for handling census data, based on population-weighted centroids, and its implications for GIS "[geographic information systems]." The geographical scope is worldwide, with an example provided using data for Wales. excerpt
[27]
Qi W Liu S H Gao X L et al. 2015 . Modeling the spatial distribution of urban population during the daytime and at night based on land use: A case study in Beijing, China
[J]. Journal of Geographical Sciences , 25 (6 ): 756 -768 .
https://doi.org/10.1007/s11442-015-1200-0
URL
[本文引用: 1]
[28]
Stevens F R Gaughan A E Linard C et al. 2015 . Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data
[J]. PLoS One , 10 (2 ): e0107042 .
https://doi.org/10.1371/journal.pone.0107042
URL
PMID: 25689585
[本文引用: 2]
摘要
Abstract High resolution, contemporary data on human population distributions are vital for measuring impacts of population growth, monitoring human-environment interactions and for planning and policy development. Many methods are used to disaggregate census data and predict population densities for finer scale, gridded population data sets. We present a new semi-automated dasymetric modeling approach that incorporates detailed census and ancillary data in a flexible, "Random Forest" estimation technique. We outline the combination of widely available, remotely-sensed and geospatial data that contribute to the modeled dasymetric weights and then use the Random Forest model to generate a gridded prediction of population density at ~100 m spatial resolution. This prediction layer is then used as the weighting surface to perform dasymetric redistribution of the census counts at a country level. As a case study we compare the new algorithm and its products for three countries (Vietnam, Cambodia, and Kenya) with other common gridded population data production methodologies. We discuss the advantages of the new method and increases over the accuracy and flexibility of those previous approaches. Finally, we outline how this algorithm will be extended to provide freely-available gridded population data sets for Africa, Asia and Latin America.
[29]
Taylor K E. 2001 . Summarizing multiple aspects of model performance in a single diagram
[J]. Journal of Geophysical Research , 106 (D7 ): 7183 -7192 .
https://doi.org/10.1029/2000JD900719
URL
[本文引用: 1]
摘要
A diagram has been devised that can provide a concise statistical summary of how well patterns match each other in terms of their correlation, their root-mean-square difference, and the ratio of their variances. Although the form of this diagram is general, it is especially useful in evaluating complex models, such as those used to study geophysical phenomena. Examples are given showing that the diagram can be used to summarize the relative merits of a collection of different models or to track changes in performance of a model as it is modified. Methods are suggested for indicating on these diagrams the statistical significance of apparent differences and the degree to which observational uncertainty and unforced internal variability limit the expected agreement between model-simulated and observed behaviors. The geometric relationship between the statistics plotted on the diagram also provides some guidance for devising skill scores that appropriately weight among the various measures of pattern correspondence.
基于多源信息的人口分布格网化方法研究
1
2015
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于多源信息的人口分布格网化方法研究
1
2015
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于乡镇尺度的中国25省区人口分布特征及影响因素
3
2015
... 式中:RSD 为路网密度;N r 、N ne 、N pe 、N cr 分别为各区县内铁路、国家主干道、省级公路、县道长度(km);A 为区县行政单元面积(km2 ).考虑到不同等级公路的运输容量和通行能力的差异,将各等级道路里程换算为标准县道长度,式中系数3、3、2、1分别为铁路、国家主干道、省级公路、县道的换算系数(柏中强, 王卷乐, 杨雅萍等, 2015 ). ...
... 本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素.相关的技术路线如图2 所示. ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
基于乡镇尺度的中国25省区人口分布特征及影响因素
3
2015
... 式中:RSD 为路网密度;N r 、N ne 、N pe 、N cr 分别为各区县内铁路、国家主干道、省级公路、县道长度(km);A 为区县行政单元面积(km2 ).考虑到不同等级公路的运输容量和通行能力的差异,将各等级道路里程换算为标准县道长度,式中系数3、3、2、1分别为铁路、国家主干道、省级公路、县道的换算系数(柏中强, 王卷乐, 杨雅萍等, 2015 ). ...
... 本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素.相关的技术路线如图2 所示. ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
基于随机森林的元胞自动机城市扩展模拟: 以佛山市为例
1
2015
... 基于上述优点,本文在获得珠江三角洲2010年准确的行政边界及第六次人口普查数据的基础上,基于R语言的randomForest包实现利用随机森林模型进行珠江三角洲30 m网格的人口空间化.首先输入样本,以珠江三角洲43个区县的人口密度作为因变量,13个影响因子作为自变量,包括夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度.然后对随机森林模型进行训练,训练时有两个重要的参数:ntree 和mtry .ntree 表示决策树的数量,mtry 表示决策树分裂时候选变量的个数.由于采样时使用的是bootstrap有放回的采样方法,因此原始训练集中约63.2%的样本被采集,剩余的36.8%样本组成袋外数据,对样本进行交叉验证(方匡南等, 2011 ).所以本文利用OOB无偏估计得到不同参数设置下随机森林模型的精度,进行参数设置(陈凯等, 2015 ).首先确定参数mtry ,在决策树的棵数较大的前提下(ntree =500),测试mtry 不同取值时随机森林模型的精度.如图3 所示,通过OOB无偏估计得到的模型精度随着mtry 的增加先大幅提高后缓慢降低,在mtry =4处取得最大值89.83%,所以本文中mtry 参数设置为4.当mtry =4时,ntree 的增加使得模型精度不断提高,在ntree =500时模型精度达到89.93%,之后精度都接近90%并有小幅度波动(图4 ).综合考虑模型精度与计算机运行性能,本文中ntree 参数设置为500.采用设置好的参数,在珠江三角洲区县级进行随机森林模型的训练,然后将生成的随机森林应用到每个30 m×30 m的网格中,预测每个30 m×30 m网格的人口密度,初步实现珠江三角洲30 m×30 m格网的人口空间化.基于OOB数据,采用平均基尼系数下降法对变量因子进行重要性度量. ...
基于随机森林的元胞自动机城市扩展模拟: 以佛山市为例
1
2015
... 基于上述优点,本文在获得珠江三角洲2010年准确的行政边界及第六次人口普查数据的基础上,基于R语言的randomForest包实现利用随机森林模型进行珠江三角洲30 m网格的人口空间化.首先输入样本,以珠江三角洲43个区县的人口密度作为因变量,13个影响因子作为自变量,包括夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度.然后对随机森林模型进行训练,训练时有两个重要的参数:ntree 和mtry .ntree 表示决策树的数量,mtry 表示决策树分裂时候选变量的个数.由于采样时使用的是bootstrap有放回的采样方法,因此原始训练集中约63.2%的样本被采集,剩余的36.8%样本组成袋外数据,对样本进行交叉验证(方匡南等, 2011 ).所以本文利用OOB无偏估计得到不同参数设置下随机森林模型的精度,进行参数设置(陈凯等, 2015 ).首先确定参数mtry ,在决策树的棵数较大的前提下(ntree =500),测试mtry 不同取值时随机森林模型的精度.如图3 所示,通过OOB无偏估计得到的模型精度随着mtry 的增加先大幅提高后缓慢降低,在mtry =4处取得最大值89.83%,所以本文中mtry 参数设置为4.当mtry =4时,ntree 的增加使得模型精度不断提高,在ntree =500时模型精度达到89.93%,之后精度都接近90%并有小幅度波动(图4 ).综合考虑模型精度与计算机运行性能,本文中ntree 参数设置为500.采用设置好的参数,在珠江三角洲区县级进行随机森林模型的训练,然后将生成的随机森林应用到每个30 m×30 m的网格中,预测每个30 m×30 m网格的人口密度,初步实现珠江三角洲30 m×30 m格网的人口空间化.基于OOB数据,采用平均基尼系数下降法对变量因子进行重要性度量. ...
基于土地利用数据和夜间灯光数据的人口空间化模型对比分析: 以黄河三角洲高效生态经济区为例
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于土地利用数据和夜间灯光数据的人口空间化模型对比分析: 以黄河三角洲高效生态经济区为例
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
随机森林方法研究综述
2
2011
... 随机森林模型的优点在于:第一,避免了过度拟合.因为在决策树生长过程中bootstrap的采样方法使得每棵决策树不是由全部样本生成,在生成决策树生长过程也不是利用全部变量进行分裂.第二,它对异常值和噪声具有很高的容忍度(Breiman, 2001b ; 方匡南等, 2011 ).第三,它能度量变量的重要性,对于了解影响人口分布的机制有明显的积极作用.第四,随机森林能在运算量没有显著提高的前提下提高预测精度,为快速且准确地实现大范围精细栅格的人口空间化提供有力支撑.同时Stevens等(2015)指出,在人口空间化中使用随机森林模型,需要和GIS行政区域边界匹配得很好的人口普查数据. ...
... 基于上述优点,本文在获得珠江三角洲2010年准确的行政边界及第六次人口普查数据的基础上,基于R语言的randomForest包实现利用随机森林模型进行珠江三角洲30 m网格的人口空间化.首先输入样本,以珠江三角洲43个区县的人口密度作为因变量,13个影响因子作为自变量,包括夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度.然后对随机森林模型进行训练,训练时有两个重要的参数:ntree 和mtry .ntree 表示决策树的数量,mtry 表示决策树分裂时候选变量的个数.由于采样时使用的是bootstrap有放回的采样方法,因此原始训练集中约63.2%的样本被采集,剩余的36.8%样本组成袋外数据,对样本进行交叉验证(方匡南等, 2011 ).所以本文利用OOB无偏估计得到不同参数设置下随机森林模型的精度,进行参数设置(陈凯等, 2015 ).首先确定参数mtry ,在决策树的棵数较大的前提下(ntree =500),测试mtry 不同取值时随机森林模型的精度.如图3 所示,通过OOB无偏估计得到的模型精度随着mtry 的增加先大幅提高后缓慢降低,在mtry =4处取得最大值89.83%,所以本文中mtry 参数设置为4.当mtry =4时,ntree 的增加使得模型精度不断提高,在ntree =500时模型精度达到89.93%,之后精度都接近90%并有小幅度波动(图4 ).综合考虑模型精度与计算机运行性能,本文中ntree 参数设置为500.采用设置好的参数,在珠江三角洲区县级进行随机森林模型的训练,然后将生成的随机森林应用到每个30 m×30 m的网格中,预测每个30 m×30 m网格的人口密度,初步实现珠江三角洲30 m×30 m格网的人口空间化.基于OOB数据,采用平均基尼系数下降法对变量因子进行重要性度量. ...
随机森林方法研究综述
2
2011
... 随机森林模型的优点在于:第一,避免了过度拟合.因为在决策树生长过程中bootstrap的采样方法使得每棵决策树不是由全部样本生成,在生成决策树生长过程也不是利用全部变量进行分裂.第二,它对异常值和噪声具有很高的容忍度(Breiman, 2001b ; 方匡南等, 2011 ).第三,它能度量变量的重要性,对于了解影响人口分布的机制有明显的积极作用.第四,随机森林能在运算量没有显著提高的前提下提高预测精度,为快速且准确地实现大范围精细栅格的人口空间化提供有力支撑.同时Stevens等(2015)指出,在人口空间化中使用随机森林模型,需要和GIS行政区域边界匹配得很好的人口普查数据. ...
... 基于上述优点,本文在获得珠江三角洲2010年准确的行政边界及第六次人口普查数据的基础上,基于R语言的randomForest包实现利用随机森林模型进行珠江三角洲30 m网格的人口空间化.首先输入样本,以珠江三角洲43个区县的人口密度作为因变量,13个影响因子作为自变量,包括夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度.然后对随机森林模型进行训练,训练时有两个重要的参数:ntree 和mtry .ntree 表示决策树的数量,mtry 表示决策树分裂时候选变量的个数.由于采样时使用的是bootstrap有放回的采样方法,因此原始训练集中约63.2%的样本被采集,剩余的36.8%样本组成袋外数据,对样本进行交叉验证(方匡南等, 2011 ).所以本文利用OOB无偏估计得到不同参数设置下随机森林模型的精度,进行参数设置(陈凯等, 2015 ).首先确定参数mtry ,在决策树的棵数较大的前提下(ntree =500),测试mtry 不同取值时随机森林模型的精度.如图3 所示,通过OOB无偏估计得到的模型精度随着mtry 的增加先大幅提高后缓慢降低,在mtry =4处取得最大值89.83%,所以本文中mtry 参数设置为4.当mtry =4时,ntree 的增加使得模型精度不断提高,在ntree =500时模型精度达到89.93%,之后精度都接近90%并有小幅度波动(图4 ).综合考虑模型精度与计算机运行性能,本文中ntree 参数设置为500.采用设置好的参数,在珠江三角洲区县级进行随机森林模型的训练,然后将生成的随机森林应用到每个30 m×30 m的网格中,预测每个30 m×30 m网格的人口密度,初步实现珠江三角洲30 m×30 m格网的人口空间化.基于OOB数据,采用平均基尼系数下降法对变量因子进行重要性度量. ...
中国人口分布的自然成因
2
2012
... 本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素.相关的技术路线如图2 所示. ...
... 本文结果与方瑜等(2012) 的研究结果,即地形因子是影响人口分布的重要因素不一致,原因是该研究为全国尺度的,全国地形分为三级阶梯,地形起伏大,而珠江三角洲是冲积平原,大部分区域是平原或丘陵,整体地形比较平缓,高程、坡度略高的区域的气候环境变化不明显,因此地形因子对珠江三角洲区域的人口分布约束较小. ...
中国人口分布的自然成因
2
2012
... 本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素.相关的技术路线如图2 所示. ...
... 本文结果与方瑜等(2012) 的研究结果,即地形因子是影响人口分布的重要因素不一致,原因是该研究为全国尺度的,全国地形分为三级阶梯,地形起伏大,而珠江三角洲是冲积平原,大部分区域是平原或丘陵,整体地形比较平缓,高程、坡度略高的区域的气候环境变化不明显,因此地形因子对珠江三角洲区域的人口分布约束较小. ...
基于人口普查与多源夜间灯光数据的海岸带人口空间化分析
1
2013
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于人口普查与多源夜间灯光数据的海岸带人口空间化分析
1
2013
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于多智能体的城市人口分布模型
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于多智能体的城市人口分布模型
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
1
2008
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
1
2008
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于GIS的青藏高原人口统计数据空间化
2
2003
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
基于GIS的青藏高原人口统计数据空间化
2
2003
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
珠三角地区建设用地扩张与经济、人口变化之间相互作用的时空演变特征分析
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
珠三角地区建设用地扩张与经济、人口变化之间相互作用的时空演变特征分析
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
辽中南城市群人口分布的时空演变特征
1
2010
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
辽中南城市群人口分布的时空演变特征
1
2010
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
DMSP/OLS数据应用研究综述
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
DMSP/OLS数据应用研究综述
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
山东省人口空间分布格局的多尺度分析
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
山东省人口空间分布格局的多尺度分析
1
2012
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
多元统计回归及地理加权回归方法在多尺度人口空间化研究中的应用
1
2016
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
多元统计回归及地理加权回归方法在多尺度人口空间化研究中的应用
1
2016
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
城市规划中人口空间分布模拟方法研究
1
2011
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
城市规划中人口空间分布模拟方法研究
1
2011
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于土地利用类型的村级人口空间分布模拟: 以湖北鹤峰县为例
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于土地利用类型的村级人口空间分布模拟: 以湖北鹤峰县为例
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
随机森林算法基本思想及其在生态学中的应用: 以云南松分布模拟为例
1
2014
... 随机森林是由Leo Breiman和Cutlery Adele在2001年提出的一种分类回归树的数据挖掘方法,是一种组合式的自学习技术(引自张雷等, 2014 ).随机森林中每棵树的训练集是应用bootstrap方法从总训练集中有放回地随机抽样获得.假设有M 个原始变量,对于采集的样本随机选择mtry (mtry <<M )个特征向量作为决策树分裂的候选变量,从这mtry 个候选变量中选择信息含量最丰富的变量进行节点分裂,而且在树的生长过程不进行修剪.按照这种方式生成ntree 棵决策树,然后通过ntree 棵树的反馈进行预测,如果是分类则由多数投票决定,如果是回归则计算平均值.每次未被抽到的样本组成了袋外数据(Out-Of-Bag, OOB),这些袋外数据可用于度量变量因子的重要性,变量重要性的值越大说明该变量因子的重要性越高、越能解释因变量.变量因子重要性的度量方法常用的有两种,分别为平均精度减少法和平均基尼系数下降法.平均精度减少法通过计算袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量来衡量变量的重要性;平均基尼系数下降法则是遍历所有树节点,统计每个特征变量对应的基尼系数下降总和作为该特征的贡献度.OOB数据还可以用于估计模型的性能,Breiman通过实验证明OOB估计是无偏估计(Breiman, 2001a ). ...
随机森林算法基本思想及其在生态学中的应用: 以云南松分布模拟为例
1
2014
... 随机森林是由Leo Breiman和Cutlery Adele在2001年提出的一种分类回归树的数据挖掘方法,是一种组合式的自学习技术(引自张雷等, 2014 ).随机森林中每棵树的训练集是应用bootstrap方法从总训练集中有放回地随机抽样获得.假设有M 个原始变量,对于采集的样本随机选择mtry (mtry <<M )个特征向量作为决策树分裂的候选变量,从这mtry 个候选变量中选择信息含量最丰富的变量进行节点分裂,而且在树的生长过程不进行修剪.按照这种方式生成ntree 棵决策树,然后通过ntree 棵树的反馈进行预测,如果是分类则由多数投票决定,如果是回归则计算平均值.每次未被抽到的样本组成了袋外数据(Out-Of-Bag, OOB),这些袋外数据可用于度量变量因子的重要性,变量重要性的值越大说明该变量因子的重要性越高、越能解释因变量.变量因子重要性的度量方法常用的有两种,分别为平均精度减少法和平均基尼系数下降法.平均精度减少法通过计算袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量来衡量变量的重要性;平均基尼系数下降法则是遍历所有树节点,统计每个特征变量对应的基尼系数下降总和作为该特征的贡献度.OOB数据还可以用于估计模型的性能,Breiman通过实验证明OOB估计是无偏估计(Breiman, 2001a ). ...
地理格网模型研究进展
1
2009
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
地理格网模型研究进展
1
2009
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
新时期珠江三角洲城市群发展战略的思考
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
新时期珠江三角洲城市群发展战略的思考
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
1
2015
... 珠江三角洲位于中国广东省中部沿海,是西江、北江冲积形成的大三角洲和东江冲积形成的小三角洲的合称(图1 ).三角洲属于亚热带气候,雨热同期,土壤肥沃,河道纵横,适宜农业种植(珠江三角洲城市群年鉴编纂委员会, 2015 ).1995年,广东省政府在《珠江三角洲经济区经济社会发展规划(1996-2010年)》中,将“珠江三角洲经济区”范围调整为位于珠江沿岸的广州、深圳、佛山、珠海、东莞、中山、江门7个地级行政区及惠州、肇庆2个地级行政区的一部分.珠江三角洲是全国经济发展最迅速的地区之一.随着经济的快速发展,大量外来人口迁入,如今珠江三角洲是中国市场化程度最高、经济最发达、人口密度最高的地域之一(刘志佳等, 2015 ; 周春山等, 2015 ). ...
基于多智能体模型与建筑物信息的高空间分辨率人口分布模拟
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
基于多智能体模型与建筑物信息的高空间分辨率人口分布模拟
1
2014
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
Random forests
1
2001
... 随机森林是由Leo Breiman和Cutlery Adele在2001年提出的一种分类回归树的数据挖掘方法,是一种组合式的自学习技术(引自张雷等, 2014 ).随机森林中每棵树的训练集是应用bootstrap方法从总训练集中有放回地随机抽样获得.假设有M 个原始变量,对于采集的样本随机选择mtry (mtry <<M )个特征向量作为决策树分裂的候选变量,从这mtry 个候选变量中选择信息含量最丰富的变量进行节点分裂,而且在树的生长过程不进行修剪.按照这种方式生成ntree 棵决策树,然后通过ntree 棵树的反馈进行预测,如果是分类则由多数投票决定,如果是回归则计算平均值.每次未被抽到的样本组成了袋外数据(Out-Of-Bag, OOB),这些袋外数据可用于度量变量因子的重要性,变量重要性的值越大说明该变量因子的重要性越高、越能解释因变量.变量因子重要性的度量方法常用的有两种,分别为平均精度减少法和平均基尼系数下降法.平均精度减少法通过计算袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量来衡量变量的重要性;平均基尼系数下降法则是遍历所有树节点,统计每个特征变量对应的基尼系数下降总和作为该特征的贡献度.OOB数据还可以用于估计模型的性能,Breiman通过实验证明OOB估计是无偏估计(Breiman, 2001a ). ...
Statistical modeling: The two cultures
1
2001
... 随机森林模型的优点在于:第一,避免了过度拟合.因为在决策树生长过程中bootstrap的采样方法使得每棵决策树不是由全部样本生成,在生成决策树生长过程也不是利用全部变量进行分裂.第二,它对异常值和噪声具有很高的容忍度(Breiman, 2001b ; 方匡南等, 2011 ).第三,它能度量变量的重要性,对于了解影响人口分布的机制有明显的积极作用.第四,随机森林能在运算量没有显著提高的前提下提高预测精度,为快速且准确地实现大范围精细栅格的人口空间化提供有力支撑.同时Stevens等(2015)指出,在人口空间化中使用随机森林模型,需要和GIS行政区域边界匹配得很好的人口普查数据. ...
Spatiotemporal patterns of population in mainland China, 1990 to 2010
3
2016
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
... 本文基于前人关于人口分布影响因素的研究(方瑜等, 2012 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Gaughan et al, 2016 ),并结合珠江三角洲的特点,选取夜间灯光强度、到水体的距离、到道路的距离、到建成区的距离、铁路长度、国道长度、省道长度、县道长度、路网密度、河网密度、行政区面积、高程和坡度作为人口分布的变量因子,运用随机森林模型建立人口密度与变量因子之间的关系,并利用生成的随机森林树对每个30 m×30 m栅格的人口密度进行估算,通过分区密度制图得到珠江三角洲的30 m×30 m网格的人口分布图并作精度验证,最后对变量因子进行重要性度量,分析影响珠江三角洲人口分布的因素.相关的技术路线如图2 所示. ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
Mapping population data from zone centroid locations
1
1989
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
Modeling the spatial distribution of urban population during the daytime and at night based on land use: A case study in Beijing, China
1
2015
... 人口分布状况反映一个地区自然地理条件的差异和经济发展水平的高低,研究人口分布意义在于揭示人口分布的地域特点,进一步掌握人口空间分布的规律性(李玲等, 2008 ; 苏飞等, 2010 ).准确掌握人口的空间分布信息,有助于科学制定区域发展规划、灾害风险防范与救助、经济建设、环境与生态保护等相关政策,有助于高效管理城市、改善居民生活环境,有助于提高人口、资源、环境综合管理的能力.人口密度网格化比人口密度行政单元更接近人口实际分布,而且是实现人口数据与其他社会统计数据、资源环境数据融合,提高人口、资源、环境综合管理能力的重要途径之一(周成虎等, 2009 ; 肖荣波等, 2011 ; 王鹤饶等, 2012 ; 卓莉等, 2014 ).当前广泛使用的人口数据通常是以行政区划为单元,通过普查、抽样统计等方式逐级汇总获得的典型人口统计数据,在实际应用中存在时间分辨率低、空间分辨率低、直观性差、不支持空间运算和分析等不足(高义等, 2013 ).遥感技术以其获取数据速度快、周期短、数据量大等优势在人口数据空间化中提供大量变量因子的数据来源,推动了基于多源数据融合的人口数据空间化.许多学者已经对不同数据源、不同尺度、不同模拟方法作了很多有益的探索(廖顺宝等, 2003 ; 康停军等, 2012 ; 王静等, 2012 ; 陈晴等, 2014 ; 张建辰等, 2014 ; Qi et al, 2015 ; 柏中强, 王卷乐, 姜浩等, 2015 ; Gaughan et al, 2016 ; 王珂靖等, 2016 ).但中尺度的研究较少,空间分辨率大部分为1 km,难以达到精细化城市管理的要求,而且对于变量因子的解释性较弱,较少利用空间变量分析影响人口分布的因素. ...
Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data
2
2015
... 本文模拟30 m网格人口分布是根据区县级人口普查数据进行的人口数据空间化,为反映人口空间化模型的精度水平,选取广州市166个乡镇街道的人口普查数据进行精度检验.将166个乡镇街道按照第六次人口普查数据计算得到的人口密度分成三组:人口密度小于0.5万人/km2 的人口密度低组(72个镇街),介于0.5万人/km2 和5.6万人/km2 之间的人口密度中等组(80个镇街),以及大于5.6万人/km2 的人口密度高组(14个镇街);同时采用平均绝对误差(MAE )、均方根误差(RMSE )和相对均方根误差(%RMSE )来衡量对比每组及全部的人口普查数据与WorldPop数据集、GPW v4数据集、中国公里网格人口分布数据集的精度,并进一步采用Taylor图(Taylor, 2001 )对比本文模拟结果和三种公开数据集.其中MAE 是相对误差取绝对值再算平均,避免了正负相抵消的情况;%RMSE 是通过均方根误差除以人口普查数的平均值得到,可以反映模型模拟的精度高低(Stevens et al, 2015 ). ...
... 从上述分析可见,夜间灯光强度是珠江三角洲人口分布最重要的指示性指标,到水域的距离、到建成区的距离和路网密度对珠江三角洲人口分布均具有重要作用.这个结果也和前人的研究基本一致(廖顺宝等, 2003 ; 柏中强, 王卷乐, 杨雅萍等, 2015 ; Stevens et al, 2015 ; Gaughan et al, 2016 ).改革开放以来,以广州市、深圳市为中心的珠江三角洲地区的第二、三产业快速发展,城市也开始快速扩展,成为经济增长的热点区域,吸引了大量的外来人口迁入,为城市管理与正常运行需要,基础设施逐步完善,例如路灯设施,所以夜间灯光强度与人口分布具有显著的相关性,灯光强的区域人口分布密集.珠江三角洲地区地处珠江流域下游,气候温热多雨,有着数目繁多的池塘与沼泽湿地,给原始居民创造了得天独厚的区位条件,于是流传下来的依山傍水而居思想影响了后代人对居住地的选择,所以到水域的距离也成为影响珠江三角洲人口分布的一个重要因素.城市发展具有集聚效应,建设用地连片形成建成区,建成区内市政设施完善,政府机关较多,卫生教育机构齐全,商业发达,吸引住户商户,所以建成区内的人口密度最高,按照距离衰减学说(Martin, 1989 ),距离建成区越远则人口分布越稀疏,珠江三角洲的人口分布也符合此模型.路网密度也是影响珠江三角洲人口分布的重要因素之一,因为在城市中物质与居民的交流运输都要依靠道路,路网密度越高,则道路的通达性越好,就越吸引居民居住;同时越多的居民迁入后,为了居民的出行也会更加完善道路交通,路网密度进一步提高,所以路网密度也是影响人口分布的重要因素. ...
Summarizing multiple aspects of model performance in a single diagram
1
2001
... 本文模拟30 m网格人口分布是根据区县级人口普查数据进行的人口数据空间化,为反映人口空间化模型的精度水平,选取广州市166个乡镇街道的人口普查数据进行精度检验.将166个乡镇街道按照第六次人口普查数据计算得到的人口密度分成三组:人口密度小于0.5万人/km2 的人口密度低组(72个镇街),介于0.5万人/km2 和5.6万人/km2 之间的人口密度中等组(80个镇街),以及大于5.6万人/km2 的人口密度高组(14个镇街);同时采用平均绝对误差(MAE )、均方根误差(RMSE )和相对均方根误差(%RMSE )来衡量对比每组及全部的人口普查数据与WorldPop数据集、GPW v4数据集、中国公里网格人口分布数据集的精度,并进一步采用Taylor图(Taylor, 2001 )对比本文模拟结果和三种公开数据集.其中MAE 是相对误差取绝对值再算平均,避免了正负相抵消的情况;%RMSE 是通过均方根误差除以人口普查数的平均值得到,可以反映模型模拟的精度高低(Stevens et al, 2015 ). ...
 , 刘凯
, 刘凯




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}