郭思慧 , 文聪聪
, 文聪聪
GUO Sihui, WEN Congcong
通讯作者:
版权声明: 2017 地理科学进展 《地理科学进展》杂志 版权所有
基金资助:
作者简介:
作者简介:郭思慧(1994-),女,湖北鄂州人,博士生,主要从事空间大数据挖掘研究,E-mail: guosh@lreis.ac.cn。
展开
摘要
居民出行活动与居民的收入水平关系是公共交通、城市地理研究的重要问题。传统获取居民出行活动信息主要基于问卷调查的方式,不仅成本高、样本量有限,且研究局限于定性讨论,研究结果易因受访者的主观意识而产生偏颇。随着信息技术的革新,传感器记录的大规模人类活动信息为研究居民出行活动特征与居民收入水平关系提供了可能性。本文利用上海市居民时空轨迹数据,从居民出行活动的角度出发,首先构建居民出行活动指标,并利用主成分分析法提取居民出行活动特征的主要成分;然后对主成分进行K-Means聚类,并针对不同出行活动特征的类别,分析居民出行活动特征与居民收入水平的关系,结果表明:①居民出行地点多样性与居民出行范围大小是反映居民出行活动特征的主要成分;②移动范围越小、移动地点多样性越低的居民类别,其平均工资水平越高;③不同移动性特征的类别平均收入水平差异与各类别居民工作地的产业发展有关。研究结论可为城市规划及相关经济政策制定提供参考。
关键词:
Abstract
The relationship between income and travel behavior characteristics of urban residents is of great concern in urban geography. Income level of residents is an important indicator measuring regional social development, thus understanding this relationship is of great significance for city planning. Before the Big Data Age, due to the lack of residents' travel behavior information, it was difficult to study this relationship. However, along with the innovation of information technology, the use of ubiquitous sensors, such as mobile phones, has produced a large amount of human activity information, enabling the research on the relationship between residents' travel behaviors and income levels. In this study, based on the activity trajectory data in Shanghai Municipality from 27 December 2015 to 6 January 2016, we extracted a series of residents' mobility indicator data to measure mobility characteristics and conducted principal components analyses to extract the major components. We adopted the K-Means clustering method to classify residents into mobility groups and analyzed the feature of each group. Furthermore, the distribution of workplaces is shown to verify the difference in income levels between different mobility groups. Our results show that: (1) diversity of places to travel to and range of travel are two major components measuring residents' travel behavior; (2) residents who have smaller travel range and go to fewer places have higher average salary; (3) between the mobility groups, difference in income levels relate to industrial setup. These results may be useful for city planners to make efficient economic policies.
Keywords:
居民的出行活动与居民收入的关系是城市地理学研究的重要内容。传统获取居民出行活动信息的方式主要基于问卷调查(张文尝等, 2007; 丁威等, 2008; 周素红等, 2010; 陆锡明等, 2011),不仅成本高、获取效率低,且有效问卷的样本量小,给居民出行活动研究增加了难度。随着信息技术的革新,与居民经济活动有关的行为数据被无处不在的传感器实时记录,通过分析这些来源于社会经济系统的大数据,以较低的调查成本实时高效地了解居民微观经济属性成为可能(高见等, 2016)。例如,Soto等(2011)利用手机数据中抽取的移动模式(移动半径、移动熵等)、通话模式(通话量、短信条数等)和社交网络模式(通话联系人比例、短信联系人比例等)特征,来预测居民的个体经济水平,预测精度超过80%;Smith-Clarke等(2014)对2个发展中国家的实证研究发现,手机用户集群行为中的固有模式(如通话次数、通话网络等)特征与普查数据中的贫困指数显著相关;Blumenstock等(2015)结合卢旺达手机网络数据提取居民通话模式特征(如通话次数、通话时长)、通话联系网络特征及移动模式特征(移动范围、出行地点)来预测居民的社会经济水平(收入水平、住房情况、受教育程度等),并通过预测的居民社会经济水平重建了整个国家的财富分布状况,结果与政府普查数据高度一致。这些研究都表明,居民的社会经济活动与居民收入状况之间存在一定的关系。然而,上述研究所涉及的社会经济活动含义较广,通话模式、社交模式等都包含在内,城市居民的出行活动模式与收入水平间的关系实际未能得到充分反映。为研究居民活动与其收入水平是否存在、以及存在何种关系,本文基于上海市居民的时空轨迹数据,从居民出行活动特征的角度出发,根据居民出行活动特征的差异对上海市居民进行聚类,研究各类居民工作地的空间分异,探寻居民出行活动特征与收入水平的关系。通过上述研究,一方面可为决策者针对不同经济水平的居民实施有效的经济决策提供参考,另一方面可为利用居民出行活动特征推断居民收入水平研究提供理论依据。
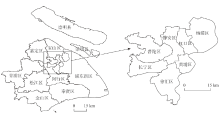
上海作为中国的经济中心城市,2015年市域总人口2415万,其中市区常住人口1443万,居民出行空间具有多样性。此外,上海是长江经济带的龙头城市,产业齐全,不同产业人员收入水平不均。因此以上海市为例进行研究具有意义。图1为上海市行政区划,市辖15区1县,包括:金山区、虹口区、杨浦区、青浦区、奉贤区、闵行区、长宁区、宝山区、嘉定区、松江区、普陀区、徐汇区、浦东新区、黄浦区、静安区和崇明县,图中放大显示的部分为上海中心城区(《上海市城市总体规划(1999年-2020年)》)。
2.2.1 数据来源
研究数据(表1)主要有:①上海市居民时空轨迹数据;②上海市各区县平均工资数据。其中,数据①来自2016年上海联通“沃数据开放应用大赛”组委会,通过对上海市642548名联通用户的手机信令数据按小时进行等时间间隔采样,获取用户各整点时刻的位置,得到用户的时空轨迹。时间为2015年12月27日-2016年1月6日,每一条记录含“日期”、“用户ID”及24小时的经纬度坐标共50个字段,如表2所示。数据②来自“搜狐新闻网”报道(https://m.sohu.com/a/114893948-391481/?pvid=000115-3w-a)。该数据以“职友集”网站对分布在上海市16个区县共8208个企业近一年内(2015年9月-2016年9月)发布的薪酬数据统计为依据;各区县内参与统计的企业个数及由此得到的平均工资,如表3所示。
表1 研究数据说明
Tab.1 Data used in the research
| 数据 | 时间 | 数据量 | 详细说明 |
|---|---|---|---|
| 居民时空轨迹数据 | 2015年12月27日-2016年1月6日 | 642548名用户5776605条轨迹 | 用户在24小时内的每整点的经纬度坐标 |
| 上海各区平均工资数据 | 2016年 | 16条 | 据16个区县内8208个企业发布薪酬统计而得 |
表2 居民时空轨迹数据示例
Tab.2 Sample data of residents' activity trajectories
| 日期 | ID | 经度 | 纬度 | … | 经度 | 纬度 |
|---|---|---|---|---|---|---|
| 20151230 | ff7cfb0e717cc3a48af443209168ef92 | 121.28 | 31.35 | … | 121.28 | 31.34 |
| 20160101 | bf3f04034044fd5c9d5f9445c3a3eda3 | 121.38 | 31.22 | … | 121.38 | 31.21 |
表3 各区县月平均工资
Tab.3 Average monthly salary in the districts of Shanghai Municipality
| 地区 | 月平均工资/元 | 样本企业个数 | 地区 | 月平均工资/元 | 样本企业个数 |
|---|---|---|---|---|---|
| 金山区 | 4590 | 80 | 宝山区 | 5340 | 214 |
| 虹口区 | 4890 | 250 | 嘉定区 | 5560 | 258 |
| 杨浦区 | 5200 | 282 | 松江区 | 5680 | 1584 |
| 青浦区 | 5230 | 166 | 普陀区 | 5790 | 432 |
| 奉贤区 | 5240 | 159 | 徐汇区 | 5960 | 477 |
| 闵行区 | 5280 | 422 | 浦东新区 | 5980 | 617 |
| 长宁区 | 5300 | 290 | 黄浦区 | 6100 | 258 |
| 崇明县 | 5310 | 103 | 静安区 | 7240 | 380 |
2.2.2 研究方法
为分析居民出行活动特征与居民收入水平的关系,一方面需要用定量化指标刻画居民的出行活动特征,另一方面需要辅助数据反映居民收入水平。结合本文使用的数据,对居民出行活动特征的刻画,通过从居民时空轨迹数据中提取一系列移动性指标来实现;居民收入水平取自居民工作单位所在行政区的月平均工资。由于居民出行活动特征是在个体层次上利用每一位居民的一系列移动性指标加以表达,而居民的收入水平状况则是在区域尺度上利用宏观统计平均值表示,因此无法直接通过传统的相关性分析方法来探究二者的相关关系。为此,本文考虑从居民出行活动特征的角度出发,根据居民出行活动特征的差异对居民进行聚类,通过分析各类别居民的收入水平变化,验证居民出行活动特征与居民收入水平的关系,方法流程如图2所示。本文主要处理步骤为:①针对居民时空轨迹,一方面通过到访频度法(Kang et al, 2010; Yuan et al, 2012; Calabrese et al, 2013)识别居民工作地;另一方面根据出行轨迹特征提取出行活动特征指标;②对出行活动特征指标进行主成分分析,从中选取刻画居民出行活动特征的主要成分;③对主成分进行K-Means聚类,得到具有不同移动性特征的各类别居民;④以各类居民为研究对象,分别求取其平均移动性指标和月平均工资,探讨各类居民月平均工资随居民出行活动特征的变化规律。
(1) 居民工作地识别及移动性指标提取
在进行居民工作地识别和移动性指标提取之前,首先对原始轨迹数据进行清洗,包括剔除24小时轨迹数据皆为空值的记录、删除同一用户在同一日的轨迹出现多种记录的错误数据、消除重复记录等。针对清洗后的居民时空轨迹数据,利用其中7个普通工作日(非周六、日且非元旦假期)背景下的轨迹来识别居民工作地:统计每个居民于上午10点至下午15点时间段内出现在不同地点的次数,将7个工作日内累积出现次数最多的坐标视为该居民的工作地坐标。
考虑到节假日(元旦)对居民出行活动的影响,将居民轨迹分为节假日和工作日2大类,采用相同的方法对2类轨迹分别提取移动性指标。由于人类出行规律的复杂性与多样性,刻画人们移动行为的指标尚未统一,但有关人们移动模式的研究主要关注出行地点的多样性及出行范围大小两方面的特征(Brockmann et al, 2006; González et al, 2008)。因此,本文选取的7个移动性指标(地点个数、移动熵、空间多样性、回旋半径、最远距离、平均出行距离、职住距离)也围绕居民到访地点及出行范围两方面特征展开。其中,地点个数(Soto et al, 2011; Frias-Martinez et al, 2013)、移动熵(Yuan et al, 2012)、空间多样性(Eagle et al, 2010)用来描述人们到访地点的多样性,例如,移动熵或空间多样性指标越大,表明居民到访不同地点的概率越均一,即居民访问不同地点的随机性较大,没有明显到访频繁的场所(Song et al, 2010)。回旋半径(Giannotti et al, 2011; Blumenstock et al, 2015)、最远距离、平均出行距离(Frias-martinez et al, 2013)、职住距离(Yuan et al, 2012)用于反映人们出行范围的大小。各项指标具体说明如下:
1) 地点个数:指研究时段内用户经过的所有不同地点个数。例如,假设用户X在研究时段内共有2条轨迹记录,分别为1月4日与1月6日的轨迹。若用户在1月4日的轨迹数据中,只有上午9点和下午15点2个时刻下有坐标记录(2个坐标不同,分别记为A点、B点),其他时刻都为空值;在1月6日的轨迹数据中,只有上午6点与上午8点有坐标记录(2个坐标相同,但不同于A、B,记为C点),其他时刻都为空值,则该用户在研究时段内的地点个数为3(A、B、C点)。
2) 移动熵:计算公式为:
3) 空间多样性:计算公式为:
4) 回旋半径:计算公式为:
其中:
5) 最远距离:用户轨迹中相隔最远的2个轨迹点之间的欧氏距离。
6) 平均出行距离:用户平均每天出行的距离大小。
7) 职住距离:用户工作地与居住地之间的欧氏距离。
8) 此外,由于本文使用的移动轨迹是通过手机信令数据转换而得,而手机信令数据记录的用户坐标连续性不一致,导致有些用户有较完善的轨迹点坐标记录(每天24小时的所处的位置都有坐标记录),而有些用户的轨迹点坐标记录则存在某些时刻缺失,因此增设“地点频次”指标来描述居民的平均签到次数(平均每天有坐标记录的次数)。仍以用户X为例,该用户共有2天轨迹记录,第1天有坐标记录的次数为2(上午9点和下午15点),第2天有坐标记录的次数也为2(上午6点与上午8点),则该用户的地点频次为
(2) 主成分提取及K-Means聚类
本文旨在从居民的出行活动角度出发,对不同出行活动特征的居民类别进行分析,因此利用移动性指标大小对居民进行聚类。考虑到移动性指标间可能存在一定的相关性,在聚类之前,首先对8个指标进行主成分变换,提取主要影响成分。为确定主成分个数,利用碎石图显示特征值随主成分个数的变化,根据Kaiser-Guttman准则(Cliff, 1988; Kaiser, 1991),选取特征值大于1的值为主成分。在此基础上针对提取的主成分对居民进行K-Means值聚类,根据Calnski-Harabasz指标(Caliński et al, 1974)确定聚类个数,利用R软件中的cascadeKM包进行聚类,得到不同出行活动特征的居民类别。
(3) 各类别居民的平均移动性指标和平均工资计算
针对各类居民进行分析:对各类居民的移动性指标求均值,得到各类别居民的平均移动性指标值。根据各类别内工作地在不同行政区的居民比例,求取该类别居民的平均工资,计算公式为:
其中:
对8个指标采用方差极大旋转(Rencher, 1992)提取主成分,每个成分仅由几个主要指标解释(即每个成分只有少数几个很大的荷载,其他都是很小的荷载)。根据Kaiser-Guttman准则(Cliff, 1988; Kaiser, 1991)选择特征值大于1的成分为主成分,节假日与工作日的主成分个数都为3,各主成分与指标间的相关系数如表4所示。
表4 方差极大旋转的主成分分析表
Tab.4 Principal component analysis by maximum variance rotation
| 相关系数 | 节假日 | 工作日 | ||||||
|---|---|---|---|---|---|---|---|---|
| 成分1 | 成分2 | 成分3 | 成分1 | 成分2 | 成分3 | |||
| 居民活动特征指标 | 地点个数 | 0.843 | 0.191 | 0.345 | 0.947 | -0.118 | ||
| 移动熵 | 0.946 | 0.193 | -0.551 | 0.885 | 0.130 | 0.395 | ||
| 空间多样性 | 0.730 | 0.490 | 0.812 | |||||
| 回旋半径 | 0.283 | 0.893 | 0.179 | 0.930 | ||||
| 最远距离 | 0.398 | 0.872 | 0.383 | 0.869 | ||||
| 平均出行距离 | 0.555 | 0.741 | 0.698 | 0.627 | ||||
| 职住距离 | -0.220 | 0.604 | -0.155 | 0.622 | 0.131 | |||
| 地点频次 | 0.925 | -0.167 | -0.912 | |||||
| 方差解释 | 方差解释度 | 0.342 | 0.320 | 0.165 | 0.326 | 0.307 | 0.211 | |
| 累计方差解释度 | 0.342 | 0.662 | 0.827 | 0.326 | 0.633 | 0.845 | ||
由表4可知,节假日与工作日背景下8个活动特征指标对3个主成分的影响特征为:①相同点:居民出行地点多样性指标(如地点个数、移动熵、空间多样性)及居民的出行范围指标(如回旋半径、最远距离、平均出行距离及职住距离)分别为成分1与成分2的主要影响因素;居民出行地点频次、出行地点倾向性(移动熵或空间多样性)为成分3的主要影响因素。②不同点:节假日背景下,若居民签到次数越多(地点频次越大)、存在频繁签到的地点(移动熵小),则成分3值越大;而工作日则相反,居民签到次数越少(地点频次越小)、无明显到访率较高的地点(空间多样性大),成分3值也较大。具体分析如下:
(1) 节假日中3个主成分的方差解释度分别为34.2%、32%、16.5%,其中成分1主要由移动熵、地点个数及空间多样性3个移动性指标来解释,且与这3个指标都成正相关,说明成分1主要刻画居民到访不同地点的多样性,居民出行地点多样性越高,成分1值越大;成分2主要解释与居民出行范围大小有关的4个指标(如回旋半径、最远距离、平均出行距离及职住距离),出行范围越大,成分2值越大;成分3与地点频次成正相关、与移动熵成负相关,说明如果居民平均每天记录的签到次数很多,且存在频繁签到的地点(到访其中几个地点的频率明显高于其他地点),则成分3的值较大。
(2) 工作日中成分1主要由地点个数、移动熵和平均出行距离3个移动性指标来解释,且与3个指标都成正相关,说明如果居民出行距离大,到访地点个数多,且没有频繁到访的地点,则成分1的值较大;成分2与节假日下的解释一致,居民出行范围越大,成分2值越大;成分3与地点频次成负相关、与空间多样性成正相关,说明如果居民平均每天记录的签到次数很少,且不存在到访概率高的地点(每个地点签到的频率都相当),则成分3的值较大。
上述分析表明,无论节假日还是工作日,从8个居民出行活动特征指标中可提取3个主成分:成分1主要描述出行地点多样性,成分2主要描述出行范围大小,成分3则与居民签到频率有关。
以3个主成分的欧氏距离为相似性大小度量指标,对3个主成分进行K-Means聚类,即相似性大(主成分间欧氏距离小)的聚为同一类,相似性小(主成分间欧氏距离大)的划分到不同类,由此得到不同出行活动特征的居民类别。在工作日,居民根据其出行活动特征可划分为10类,各类别居民的平均移动性指标大小与月平均工资水平关系如表5所示。对各类别按照月平均工资大小由高至低进行排序后发现:不同类别居民的移动性指标变化趋势与月平均工资变化趋势相反,即到访地点多样性指标(地点个数、移动熵、空间多样性)越高且出行范围指标(回旋半径、最远距离、平均出行距离、职住距离)越大的类别,其月平均工资也越高。节假日背景下按出行活动特征进行划分得到9类居民(表6),各类别居民的平均移动性指标与月平均工资的变化规律同工作日相同,即各项平均移动性指标越大,月平均工资越少。为验证各类别居民的收入差异,对各类别居民的工作地分布进行分析。
表5 非节假日平均移动性指标与各类别月平均工资水平关系
Tab.5 Average mobility indicator values and average monthly salary of each clustering group during weekdays
| 类别 | 地点个数 | 移动熵 | 空间多样性 | 回旋半径/m | 最远距离/m | 平均出行距离/m | 职住距离/m | 月平均工资/元 |
|---|---|---|---|---|---|---|---|---|
| 3 | 6.12 | 1.38 | 1.89 | 1235.65 | 3265.69 | 1447.18 | 1449.56 | 5841.57 |
| 10 | 9.71 | 1.92 | 2.05 | 3804.35 | 10562.14 | 5270.43 | 3961.99 | 5821.59 |
| 4 | 11.24 | 2.16 | 2.15 | 6341.63 | 18256.65 | 9729.46 | 6304.11 | 5780.97 |
| 9 | 12.20 | 2.31 | 2.22 | 9265.10 | 27781.88 | 14510.48 | 7496.84 | 5757.01 |
| 5 | 16.04 | 2.75 | 2.41 | 14630.49 | 46858.75 | 28486.24 | 10598.36 | 5749.18 |
| 1 | 13.98 | 2.53 | 2.32 | 11889.93 | 36941.71 | 20799.34 | 8860.73 | 5745.92 |
| 8 | 19.29 | 3.08 | 2.53 | 16699.62 | 55862.56 | 39102.57 | 12831.57 | 5730.38 |
| 2 | 22.57 | 3.37 | 2.62 | 18836.34 | 65044.98 | 52204.91 | 16626.65 | 5720.75 |
| 7 | 24.97 | 3.58 | 2.68 | 21438.91 | 76405.06 | 69622.45 | 20768.52 | 5698.25 |
| 6 | 26.47 | 3.70 | 2.69 | 25747.73 | 94385.03 | 96397.05 | 27879.74 | 5637.16 |
表6 节假日平均移动性指标与各类别月平均工资水平关系
Tab.6 Average mobility indicator values and average monthly salary of each clustering group during holidays
| 类别 | 地点个数 | 移动熵 | 空间多样性 | 回旋半径/m | 最远距离/m | 平均出行距离/m | 职住距离/m | 月平均工资/元 |
|---|---|---|---|---|---|---|---|---|
| 1 | 3.35 | 0.89 | 1.58 | 734.18 | 1772.68 | 1347.97 | 3118.66 | 5824.24 |
| 8 | 5.92 | 1.58 | 2.17 | 3415.76 | 8578.54 | 6808.19 | 6871.25 | 5793.82 |
| 7 | 6.98 | 1.86 | 2.38 | 6580.40 | 16868.21 | 14122.77 | 7912.96 | 5758.87 |
| 4 | 7.75 | 2.04 | 2.47 | 10134.06 | 26699.50 | 22858.12 | 8794.92 | 5743.65 |
| 2 | 8.86 | 2.25 | 2.57 | 13336.10 | 36107.52 | 33590.36 | 10166.70 | 5739.76 |
| 6 | 10.04 | 2.46 | 2.65 | 16609.67 | 46314.27 | 46325.09 | 12064.22 | 5738.16 |
| 9 | 11.37 | 2.67 | 2.71 | 19539.39 | 56282.00 | 63042.27 | 15180.39 | 5722.99 |
| 5 | 13.09 | 2.93 | 2.78 | 22379.24 | 67260.64 | 87637.96 | 18822.01 | 5700.55 |
| 3 | 14.26 | 3.10 | 2.83 | 26726.16 | 83624.84 | 128193.00 | 22658.60 | 5669.64 |
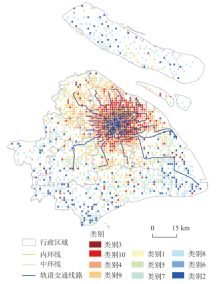
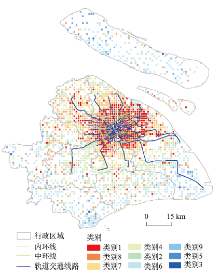
各类别居民的工作地分布如图3(工作日)、图4所示(节假日)。工作日背景下,不同类别居民的工作地分布呈现“中心—外围”的圈层结构,且平均移动性指标越小的类别越趋于分布在中心,平均移动性指标越大的类别越趋于分散在市郊周边。这种圈层结构的空间分布与上海市城市发展的总体规划(《上海市城市总体规划(1999年-2020年)》)的空间功能具有一致性:从中心内层到近郊直至远郊村镇,分别以现代服务业、第二产业、第一产业为发展重点,因此从城中心到远郊的工作人员工资水平出现递减规律。①中心城区类别:如第3类、第10类,其移动性特征为:到访不同地点的个数少(小于10个),移动熵和空间多样性指标小(表明居民会频繁到访某些地点),职住距离较短(5 km以内),平均移动范围最小(最远出行距离小于15 km);其工作地特征为:主要分布在上海的中央商务区(如外滩)和主要公共活动中心(如豫园、人民广场等),这些地区是上海市一、二级商业中心集中之地(丁亮等, 2017),以发展金融、商贸信息等现代服务业为主,因此工作地在中心城区的第3、10类居民的月平均工资水平较高。②近郊区类别:第4、9、1、5类居民,其移动性特征表现为:到访不同地点的个数居中(5~15个),职住距离在5~10 km之间,平均出行距离在25 km以内;其工作地特征为:主要分布在地铁线路可达的区域范围内,以现代制造业为主,因此这几类居民的月平均工资水平处于中等。③远郊区类别:如第7、8、6、2类居民,其移动性特征表现为:到访不同地点的个数最多(15个以上),职住距离大于10 km,平均出行距离高于25 km;其工作地特征为:主要分布在上海市远郊区的村镇,这些地区以发展现代都市农业及旅游业为主,其居民的月平均工资水平相对较低。
图3 工作日聚类结果工作地空间分布图
Fig.3 Spatial distribution of workplaces of the clustering groups during weekdays
图4 节假日聚类结果工作地空间分布图
Fig.4 Spatial distribution of workplaces of the clustering groups during holidays
节假日各类别居民的工作地分布也呈类似的圈层结构:工作地在城中心的类别主要为各项移动性指标都较小的类别(如第1、8、7类),这些类别的居民更有可能在陆家嘴等金融中心工作,其收入水平相应较高;而工作地在远郊区的主要为各项移动性指标都较大的类别(如第9、5、3类),其居民更有可能从事农业等相关工作,总体上平均收入水平相应较低。
由此可知,根据出行活动特征划分的上海市居民类别,出行地点多样性越小,出行范围越小,越有可能在城中心工作,整体上平均收入水平也越高;而出行地点多样性大,出行范围也大的类别,则更有可能在远郊区工作,整体上平均收入相对较低。
本文基于上海市居民时空轨迹数据,构建居民移动特征指标,采用K-Means方法对移动性指标的主成分进行聚类,得到不同移动性特征的居民类别。通过分析各类别居民平均移动性指标与平均工资水平变化规律,得到如下结论:①居民出行地点多样性与居民出行范围大小是反映居民出行活动特征的主要成分,分别可用到访不同地点个数、移动熵、空间多样性指标以及回旋半径、最远距离、平均出行距离、职住距离加以描述。②移动范围越小、移动地点多样性越低的类别居民,其月平均工资水平越高。③不同移动性特征的类别平均收入水平差异与各类别居民工作地分布有关,移动范围小、移动地点多样性低的类别居民,其工作地主要分布在以金融商务业为主的中心商务区,平均工资水平相应较高;相反,移动范围大、移动地点多样性高的类别居民,其工作地主要分布在以农业发展为主的远郊区,平均工资水平相应较低。
本文因数据方面的误差而存在以下不足:本文使用的居民工资数据以上海市各区县内企业发布的薪酬统计为依据,该数据表征不同行政区内工作人员的平均薪资水平,用其计算的类别平均工资只能从整体上反映不同类别间居民的薪资水平差异,未考虑各类别内居民薪资水平差异对结果造成的影响,使得本文对于居民出行活动特征与居民收入水平间关系的探讨局限于不同类别间居民的宏观比较。因此,本文结论的理论和实践意义为:一方面,从实际应用角度,有助于决策者掌握居民的收入水平状况,从而进行有针对性的决策。例如,根据《上海市城市总体规划(2016-2040)(草案)》,为提高居民幸福感,改善居民通勤状况是其中亟待解决的问题之一。通过本文的研究发现,除少部分工作地在中央商务区的居民外,大部分居民的工作地都分布在城市中心区以外,这些居民的通勤距离大,且收入水平不高,为节约出行费用成本,可能会更多地选择地铁、公交等公共交通工具出行,加大了内外环线之间公共交通需求压力,因此,政府应相应地增加地铁、公交线路,以满足与改善这部分工薪阶层的出行需求。另一方面,在理论层面,本文的结论验证了利用居民的出行活动特征可在一定程度上反映居民收入水平的高低,为进一步预测个体收入水平提供理论依据。例如,若将个体居民的出行规律用移动性指标进行量化,并能采集到部分个体居民的实际收入数据,则可运用回归分析等方法研究个体居民移动性指标与收入间的相应关系,进一步提升居民收入水平的预测水平。
但本文存在以下不足:由于使用的居民工资数据以上海市各区县内企业发布的薪酬统计为依据,该数据表征不同行政区内工作人员的平均薪资水平,用其计算的类别平均工资只能从整体上反映不同类别间居民的薪资水平差异,未考虑各类别内居民薪资水平差异对结果造成的影响,使得对于居民出行活动特征与居民收入水平间关系的探讨局限于不同类别间居民的宏观比较。因此,本文虽论证了居民出行活动特征在一定程度上反映了居民收入水平的高低,但并未深入解释两者的因果关系及相互影响机理。为更全面地揭示居民出行活动特征与其收入水平的关系,未来还需结合居民出行目的、出行方式等出行影响因素,从微观与宏观相结合的视角,对居民出行活动与收入水平的动态影响机制与模式进行深入的研究。
The authors have declared that no competing interests exist.
| [1] |
上海中心城区商业中心空间特征研究 [J].https://doi.org/10.16361/j.upf.201701008 URL [本文引用: 1] 摘要
利用手机信令数据识别游憩-居住功能联系,进一步在上海中心城区内识别出了24个城市级商业中心.依据各中心单位面积对游憩活动的吸引力判断等级,依据游憩者来源地分析各中心腹地并划分势力范围,依据与现状商业中心的距离和居住人口密度确定了商业中心布局优化方向.得出以下结论:①无论从空间分布和等级分布来看,现状商业中心都呈向心集聚特征;②中心的腹地和势力范围的空间分布受地铁、黄浦江等影响;③居民至游憩-居住功能相混合的中心平均出行距离较短;④商业中心规划需要重点关注居民游憩出行平均距离较大且居住密度较高的地区.上述结论有助于认识上海中心城区的空间结构,为商业中心规划布局提供决策支持.
A study on spatial characteristics of commercial centers in the Shanghai central city [J].https://doi.org/10.16361/j.upf.201701008 URL [本文引用: 1] 摘要
利用手机信令数据识别游憩-居住功能联系,进一步在上海中心城区内识别出了24个城市级商业中心.依据各中心单位面积对游憩活动的吸引力判断等级,依据游憩者来源地分析各中心腹地并划分势力范围,依据与现状商业中心的距离和居住人口密度确定了商业中心布局优化方向.得出以下结论:①无论从空间分布和等级分布来看,现状商业中心都呈向心集聚特征;②中心的腹地和势力范围的空间分布受地铁、黄浦江等影响;③居民至游憩-居住功能相混合的中心平均出行距离较短;④商业中心规划需要重点关注居民游憩出行平均距离较大且居住密度较高的地区.上述结论有助于认识上海中心城区的空间结构,为商业中心规划布局提供决策支持.
|
| [2] |
基于活动的居民出行行为研究综述 [J].A review of activity-based travel behavior research [J]. |
| [3] |
大数据揭示经济发展状况 [J].https://doi.org/10.3969/j.issn.1001-0548.2016.04.015 URL [本文引用: 1] 摘要
随着大数据时代的到来,与经济活动有关的数据数量和质量都得到了极大的丰富和提高。通过分析这些来源于社会经济系统中的大规模数据,人们有机会在几乎不花费调查成本的情况下对经济发展状况进行精准和实时的测量。该文关注大数据对于经济发展状况的刻画,简述了不同类型的数据在揭示宏观经济结构和微观社会状况方面的具体应用,并进一步分析了大数据助力解决区域经济发展战略和宏观产业结构升级问题的可能途径。
Big data reveal the status of economic development [J].https://doi.org/10.3969/j.issn.1001-0548.2016.04.015 URL [本文引用: 1] 摘要
随着大数据时代的到来,与经济活动有关的数据数量和质量都得到了极大的丰富和提高。通过分析这些来源于社会经济系统中的大规模数据,人们有机会在几乎不花费调查成本的情况下对经济发展状况进行精准和实时的测量。该文关注大数据对于经济发展状况的刻画,简述了不同类型的数据在揭示宏观经济结构和微观社会状况方面的具体应用,并进一步分析了大数据助力解决区域经济发展战略和宏观产业结构升级问题的可能途径。
|
| [4] |
上海市第五次居民出行调查与交通特征研究 [J].https://doi.org/10.3969/j.issn.1672-5328.2011.05.001 URL [本文引用: 1] 摘要
挖掘和分析居民出行调查的历史数据库,归纳城市交通演变的特点和规律,有利于更好地了解城市交通的发展全貌.通过对比上海市五次居民出行调查的成果,从出行强度、出行结构、出行分布等方面揭示改革开放30年来上海市居民出行特征的演变,反映出用地拓展、机动化发展给城市居民出行行为带来的变化以及对城市交通产生的影响.在相应研究分析的基础上,对未来上海交通发展的基本走向做出了判断.
The fifth travel survey of residents in Shanghai and characteristics analysis [J].https://doi.org/10.3969/j.issn.1672-5328.2011.05.001 URL [本文引用: 1] 摘要
挖掘和分析居民出行调查的历史数据库,归纳城市交通演变的特点和规律,有利于更好地了解城市交通的发展全貌.通过对比上海市五次居民出行调查的成果,从出行强度、出行结构、出行分布等方面揭示改革开放30年来上海市居民出行特征的演变,反映出用地拓展、机动化发展给城市居民出行行为带来的变化以及对城市交通产生的影响.在相应研究分析的基础上,对未来上海交通发展的基本走向做出了判断.
|
| [5] |
中国城市居民出行的时空特征及影响因素研究 [J].
城市居民交通出行是目前城市地理学和交通地理学日益关注的研究领域,其中,居民出行调查与分析是改善城市交通布局的主要依据。在介绍城市居民出行基本概念和研究内容的基础上,利用收集信息与在北京、成都和大连三市16居住区1400余份调查问卷的数据,分析了城市居民交通出行的基本特征和动态变化以及区域差异,其中重点剖析了交通出行总量、出行目的、出行方式。重点从影响因素的角度,考察了城市居民出行的发生机理,包括城市规模和城市条件、居住区位、居民经济水平等。
Spatial-temporal characteristics of urban resident trips and influence factors in China [J].
城市居民交通出行是目前城市地理学和交通地理学日益关注的研究领域,其中,居民出行调查与分析是改善城市交通布局的主要依据。在介绍城市居民出行基本概念和研究内容的基础上,利用收集信息与在北京、成都和大连三市16居住区1400余份调查问卷的数据,分析了城市居民交通出行的基本特征和动态变化以及区域差异,其中重点剖析了交通出行总量、出行目的、出行方式。重点从影响因素的角度,考察了城市居民出行的发生机理,包括城市规模和城市条件、居住区位、居民经济水平等。
|
| [6] |
基于T-GIS的广州市居民日常活动时空关系 [J].Spatio-temporal pattern of residents' daily activities based on T-GIS: A case study in Guangzhou, China [J]. |
| [7] |
Predicting poverty and wealth from mobile phone metadata [J].https://doi.org/10.1126/science.aac4420 URL PMID: 26612950 [本文引用: 1] 摘要
Accurate and timely estimates of population characteristics are a critical input to social and economic research and policy. In industrialized economies, novel sources of data are enabling new approaches to demographic profiling, but in developing countries, fewer sources of big data exist. We show that an individual's past history of mobile phone use can be used to infer his or her socioeconomic status. Furthermore, we demonstrate that the predicted attributes of millions of individuals can, in turn, accurately reconstruct the distribution of wealth of an entire nation or to infer the asset distribution of microregions composed of just a few households. In resource-constrained environments where censuses and household surveys are rare, this approach creates an option for gathering localized and timely information at a fraction of the cost of traditional methods.
|
| [8] |
The scaling laws of human travel [J].https://doi.org/10.1038/nature04292 URL PMID: 16437114 [本文引用: 1] 摘要
Abstract: The dynamic spatial redistribution of individuals is a key driving force of various spatiotemporal phenomena on geographical scales. It can synchronise populations of interacting species, stabilise them, and diversify gene pools [1-3]. Human travelling, e.g. is responsible for the geographical spread of human infectious disease [4-9]. In the light of increasing international trade, intensified human mobility and an imminent influenza A epidemic [10] the knowledge of dynamical and statistical properties of human travel is thus of fundamental importance. Despite its crucial role, a quantitative assessment of these properties on geographical scales remains elusive and the assumption that humans disperse diffusively still prevails in models. Here we report on a solid and quantitative assessment of human travelling statistics by analysing the circulation of bank notes in the United States. Based on a comprehensive dataset of over a million individual displacements we find that dispersal is anomalous in two ways. First, the distribution of travelling distances decays as a power law, indicating that trajectories of bank notes are reminiscent of scale free random walks known as Levy flights. Secondly, the probability of remaining in a small, spatially confined region for a time T is dominated by algebraically long tails which attenuate the superdiffusive spread. We show that human travelling behaviour can be described mathematically on many spatiotemporal scales by a two parameter continuous time random walk model to a surprising accuracy and conclude that human travel on geographical scales is an ambivalent effectively superdiffusive process.
|
| [9] |
Understanding individual mobility patterns from urban sensing data: A mobile phone trace example [J].https://doi.org/10.1016/j.trc.2012.09.009 URL [本文引用: 1] 摘要
Large-scale urban sensing data such as mobile phone traces are emerging as an important data source for urban modeling. This study represents a first step towards building a methodology whereby mobile phone data can be more usefully applied to transportation research. In this paper, we present techniques to extract useful mobility information from the mobile phone traces of millions of users to investigate individual mobility patterns within a metropolitan area. The mobile-phone-based mobility measures are compared to mobility measures computed using odometer readings from the annual safety inspections of all private vehicles in the region to check the validity of mobile phone data in characterizing individual mobility and to identify the differences between individual mobility and vehicular mobility. The empirical results can help us understand the intra-urban variation of mobility and the non-vehicular component of overall mobility. More importantly, this study suggests that mobile phone trace data represent a reasonable proxy for individual mobility and show enormous potential as an alternative and more frequently updatable data source and a compliment to the conventional travel surveys in mobility study. (C) 2012 Elsevier Ltd. All rights reserved.
|
| [10] |
A dendrite method for cluster analysis [J].https://doi.org/10.1080/03610927408827101 URL [本文引用: 1] 摘要
A method for identifying clusters of points in a multidimensional Euclidean space is described and its application to taxonomy considered. It reconciles, in a sense, two different approaches to the investigation of the spatial relationships between the points, viz., the agglomerative and the divisive methods. A graph, the shortest dendrite of Florek etal. (1951a), is constructed on a nearest neighbour basis and then divided into clusters by applying the criterion of minimum within cluster sum of squares. This procedure ensures an effective reduction of the number of possible splits. The method may be applied to a dichotomous division, but is perfectly suitable also for a global division into any number of clusters. An informal indicator of the "best number" of clusters is suggested. It is a"variance ratio criterion" giving some insight into the structure of the points. The method is illustrated by three examples, one of which is original. The results obtained by the dendrite method are compared with those obtained by using the agglomerative method or Ward (1963) and the divisive method of Edwards and Cavalli-Sforza (1965).
|
| [11] |
The eigenvalues-greater-than-one rule and the reliability of components [J].https://doi.org/10.1037/0033-2909.103.2.276 URL [本文引用: 2] 摘要
Abstract A commonly used criterion for the number of factors to rotate is the eigenvalues-greater-than-one rule proposed by Kaiser (1960). It states that there are as many reliable factors as there are eigenvalues greater than one. The reasoning is that an eigenvalue less than one implies that the scores on the component would have negative reliability. I show here that this rule is the result of a misapplication of the formula for internal consistency reliability. I also present a formula for the reliability of a component; it depends on the eigenvalue and the reliability of the individual measures. (PsycINFO Database Record (c) 2012 APA, all rights reserved)
|
| [12] |
Network diversity and economic development [J]. |
| [13] |
Forecasting socioeconomic trends with cell phone records [ |
| [14] |
Unveiling the complexity of human mobility by querying and mining massive trajectory data [J].https://doi.org/10.1007/s00778-011-0244-8 URL [本文引用: 1] 摘要
The technologies of mobile communications pervade our society and wireless networks sense the movement of people, generating large volumes of mobility data, such as mobile phone call records and Global Positioning System (GPS) tracks. In this work, we illustrate the striking analytical power of massive collections of trajectory data in unveiling the complexity of human mobility. We present the results of a large-scale experiment, based on the detailed trajectories of tens of thousands private cars with on-board GPS receivers, tracked during weeks of ordinary mobile activity. We illustrate the knowledge discovery process that, based on these data, addresses some fundamental questions of mobility analysts: what are the frequent patterns of people鈥檚 travels? How big attractors and extraordinary events influence mobility? How to predict areas of dense traffic in the near future? How to characterize traffic jams and congestions? We also describe M-Atlas, the querying and mining language and system that makes this analytical process possible, providing the mechanisms to master the complexity of transforming raw GPS tracks into mobility knowledge. M-Atlas is centered onto the concept of a trajectory , and the mobility knowledge discovery process can be specified by M-Atlas queries that realize data transformations, data-driven estimation of the parameters of the mining methods, the quality assessment of the obtained results, the quantitative and visual exploration of the discovered behavioral patterns and models, the composition of mined patterns, models and data with further analyses and mining, and the incremental mining strategies to address scalability.
|
| [15] |
Understanding individual human mobility patterns [J].https://doi.org/10.1038/nature06958 URL PMID: 18528393 [本文引用: 2] 摘要
Abstract Despite their importance for urban planning, traffic forecasting and the spread of biological and mobile viruses, our understanding of the basic laws governing human motion remains limited owing to the lack of tools to monitor the time-resolved location of individuals. Here we study the trajectory of 100,000 anonymized mobile phone users whose position is tracked for a six-month period. We find that, in contrast with the random trajectories predicted by the prevailing L脙漏vy flight and random walk models, human trajectories show a high degree of temporal and spatial regularity, each individual being characterized by a time-independent characteristic travel distance and a significant probability to return to a few highly frequented locations. After correcting for differences in travel distances and the inherent anisotropy of each trajectory, the individual travel patterns collapse into a single spatial probability distribution, indicating that, despite the diversity of their travel history, humans follow simple reproducible patterns. This inherent similarity in travel patterns could impact all phenomena driven by human mobility, from epidemic prevention to emergency response, urban planning and agent-based modelling.
|
| [16] |
Coefficient alpha for a principal component and the Kaiser-Guttman rule [J]. |
| [17] |
Analyzing and geo-visualizing individual human mobility patterns using mobile call records [C]// |
| [18] |
Interpretation of canonical discriminant functions, canonical variates, and principal components [J].https://doi.org/10.2307/2685219 URL [本文引用: 1] 摘要
Canonical discriminant functions are defined here as linear combinations that separate groups of observations, and canonical variates are defined as linear combinations associated with canonical correlations between two sets of variables. In standardized form, the coefficients in either type of canonical function provide information about the joint contribution of the variables to the canonical function. The standardized coefficients can be converted to correlations between the variables and the canonical function. These correlations generally alter the interpretation of the canonical functions. For canonical discriminant functions, the standardized coefficients are compared with the correlations, with partial t and F tests, and with rotated coefficients. For canonical variates, the discussion includes standardized coefficients, correlations between variables and the function, rotation, and redundancy analysis. Various approaches to interpretation of principal components are compared: the choice between the covariance and correlation matrices, the conversion of coefficients to correlations, the rotation of the coefficients, and the effect of special patterns in the covariance and correlation matrices.
|
| [19] |
Poverty on the cheap: Estimating poverty maps using aggregated mobile communication networks [
|
| [20] |
Limits of predictability in human mobility [J]. |
| [21] |
Prediction of socioeconomic levels using cell phone records [ |
| [22] |
Correlating mobile phone usage and travel behavior: A case study of Harbin, China [J].https://doi.org/10.1016/j.compenvurbsys.2011.07.003 URL [本文引用: 3] 摘要
Information and communication technologies (ICTs), such as mobile phones and the Internet, are increasingly pervasive in modern society. These technologies provide new resources for spatio-temporal data mining and geographic knowledge discovery. Since the development of ICTs also impacts physical movement of individuals in societies, much of the existing research has focused on examining the correlation between ICT and human mobility. In this paper, we aim to provide a deeper understanding of how usage of mobile phones correlates with individual travel behavior by exploring the correlation between mobile phone call frequencies and three indicators of travel behavior: (1) radius, (2) eccentricity, and (3) entropy. The methodology is applied to a large dataset from Harbin city in China. The statistical analysis indicates a significant correlation between mobile phone usage and all of the three indicators. In addition, we examine and demonstrate how explanatory factors, such as age, gender, social temporal orders and characteristics of the built environment, impact the relationship between mobile phone usage and individual activity behavior.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}