张珣 , 陈健璋, 于重重
, 陈健璋, 于重重
ZHANG Xun, CHEN Jianzhang, YU Chongchong
通讯作者:
版权声明: 2017 地理科学进展 《地理科学进展》杂志 版权所有
基金资助:
作者简介:
作者简介:张珣(1986-),男,吉林辽源人,副教授,硕导,从事商业地理分析、GIS软件技术研究,E-mail: zhangxun@btbu.edu.cn。
展开
摘要
在京津冀协同发展战略背景下,以建设京津冀世界级城市群为引领,遵循城市发展规律,优化城市空间布局,明确京津冀城市群等级结构及其空间特征具有重要意义。本文以京津冀城市群156个区县为研究对象,从经济中心性、交通中心性、信息中心性、人口中心性4个角度,利用4种空间聚类方法进行5个等级的聚类分析,并基于克氏中心地理论对京津冀城市群等级划分结果进行空间结构分析。结果显示,自组织特征映射神经网络算法(SOM)较适合京津冀城市群的等级划分;京津冀城市群正从以北京城区为单核心的圈层空间结构向3条带型空间结构转变,其中京津都市发展走廊发育成熟,沿海都市发展带也初具规模,而包括雄安新区在内的京石都市发展带正在孕育。
关键词:
Abstract
With the main focus of regional competition shifting from cities to urban agglomerations, it is important to analyze the spatial structure and direction of coordinated development in urban agglomerations. This is especially significant in the Beijing-Tianjin-Hebei urban agglomeration, which is a core urban agglomeration in China. Machine learning algorithms are relatively new methods for addressing geographical problems. Clustering method, as unsupervised learning, is useful for classifying geographical units without the need for priori knowledge. Using data from 156 counties in the Beijing-Tianjin-Hebei urban agglomeration, this study applied four clustering algorithms: the K-means, density-based spatial clustering of applications with noise (DBSCAN), Chameleon, and self-organizing map (SOM) methods, for classifying counties and districts in the Beijing-Tianjin-Hebei urban agglomeration from the perspectives of economic centrality, traffic centrality, information centrality, and population centrality. GDP of the counties in 2014 was used to represent economic centrality; density of road networks in counties and attraction factor, calculated by the unsold train tickets in different time periods of the year, represent traffic centrality; Sina Weibo check-in data were used to represent information centrality; and county/district population represents population centrality. The result classifies the urban agglomeration into several levels. Respectively, K-means algorithm classifies counties into five levels; DBSCAN algorithm classifies counties into six levels; Chameleon algorithm classifies counties into six levels; and SOM algorithm classifies counties into five levels. SOM is the most applicable algorithm for the division of the urban agglomeration because the structure of counties is stable. This study further analyzed the spatial structure of the urban agglomeration with the central place theory, which points out that an agglomeration should contain certain number of counties in every level. The result of the SOM algorithm matches the central place theory. This research shows that there were remarkable gaps between different levels of the urban agglomeration. The central area of Beijing, as the core of the region, has strong radiation effect on the surrounding areas, but its functions are shared by the nearby counties. Moreover, the second and third level central cities distribute evenly and play an important role in regional development.
Keywords:
随着全球化进程日益加快,区域竞争的主体已经从区域范围内城市间的竞争转向城市群经济实体在更广阔范围内的全球竞争。城市群逐渐成为中国经济增长的核心,是中国新型城镇化的重要载体及国家区域政策的重要空间单元(黄金川等, 2014)。由于城市—区域系统的空间异质性、空间复杂性和空间开放性特点,城市间存在较大差异并且表现出发展不协调(牛方曲等, 2015)。城市群空间从模块化向网络化发展的趋势,迫切需要对城市群网络层级结构进行研究。城市的中心地理论广泛用于划分城市等级层次,描述城市体系空间交互作用的结构,还可对城市体系进行横向、纵向比较提供指导(Preston, 1970; Marshall, 1989; 周一星等, 2001)。
近年来,利用空间聚类方法探索城市区域系统逐渐成为研究热点。李新延等(2005)利用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法,基于空间相似性对某城市商业网点和中小学等公共设施进行了空间聚类分析,该研究尚未考虑属性数据影响;Gong(2010)应用ARMA-GRNN神经网络模型对1991-2008年北京—上海的空中客流进行了分析预测;陈园园等(2011)运用SOM神经网络分级模型,基于经济和交通指标,评价辽中南城市群10个节点城市的空间联系能力并进行层次划分;杨志民等(2015)构建基于K-means方法的金融中心登记识别模型,对长三角城市群的各级城市金融中心级别进行了识别。顾朝林等(2015)采用因子分析和聚类分析方法对绍兴城市群基于功能区的行政区调整进行了研究。方碧琪等(1991)利用基于距离划分的聚类方法研究北京市各区县经济分类;马林靖等(2010)应用聚类方法对进行研究,分析天津12个涉农区县的均衡发展情况;袁媛等(2014)应用SOFM网络对河北省县域贫困度进行分类。
可以看出,空间聚类算法对于区域空间层级分析具有重要价值,但是相关研究绝大部分只应用了基于欧氏距离的聚类方法,虽然这种算法易于理解和实现,但是对分布规律性不明显的现象聚类结果往往不太理想,层级划分的准确度较低。而且,目前针对京津冀城市群区域空间结构研究的分级指标考虑较单一,划分结果说服力不足。因此,本文着重从政治地位、经济实力、城市规模、区域辐射力等多个角度构建中心性指标体系,试验4种聚类方法在城市群空间结构划分中的适用性并进一步基于中心地理论深入分析京津冀城市群网络层级的空间结构特征。
京津冀城市群为中国三大城市群之一。按照国家发展和改革委员会界定,京津冀城市群范围涵盖北京市、天津市和河北省的石家庄、唐山、保定、秦皇岛、廊坊、沧州、承德、张家口8个地市及其所属的通州新城、顺义新城、滨海新区和唐山曹妃甸工业新区,面积为18.84万km2(刘卫东等, 2011)。2016年,京津冀城市群生产总值68857.15亿元,总人口1.1亿(李国平等, 2017)。目前,随着国家京津冀协同战略的实施,京津冀城市群存在核心城市带动作用不明显、区域发展不协调等问题(张旺等, 2012)。本文以京津冀156个区县为研究对象进行等级划分和空间结构分析,其中,北京、天津2个直辖市和河北省8个地级市所辖城区如表1。
表1 直辖市、地级市城区统计表
Tab.1 Urban districts of provincial-level municipalities and prefectural-level cities
| 城区名称 | 包含区 |
|---|---|
| 北京城区 | 东城区、西城区、朝阳区、丰台区、海淀区、石景山区 |
| 天津城区 | 和平区、河东区、河西区、南开区、河北区、红桥区 |
| 保定城区 | 莲池区、竞秀区(含高新区)、徐水区、清苑区、满城区 |
| 沧州城区 | 新华区、运河区 |
| 承德城区 | 双桥区、双滦区、高新区、营子区 |
| 邢台城区 | 桥东区、桥西区 |
| 张家口城区 | 桥东区、桥西区、宣化区、下花园区、万全区、崇礼区 |
| 唐山城区 | 路北区、路南区、古冶区、开平区、丰润区、丰南区、曹妃甸区 |
| 石家庄城区 | 桥西区、新华区、长安区、裕华区、井陉矿区、藁城区、鹿泉区、栾城区 |
| 廊坊城区 | 安次区、广阳区 |
| 邯郸城区 | 丛台区、复兴区、邯山区、峰峰矿区 |
| 秦皇岛城区 | 海港区、山海关区、北戴河区、抚宁区 |
空间聚类算法是典型的无监督机器学习算法,能在描述数据是如何组织或聚类的同时,从总体中给出的样本信息对总体做出某些推断(闫友彪等, 2004)。经过聚类后的数据,可根据其数据特征生成以簇为单位的数据对象集合。同一个簇中的对象彼此相似,不同簇中的对象彼此相异(金建国, 2014)。聚类算法旨在生成对象彼此相似的簇,且实现簇内对象相似度最大,簇间对象相似度最小(Ferrari et al, 2015)。将聚类算法应用于城市群内网络层级划分,是将城市群内区县为研究对象,基于多维指标数据,对所属区县进行更为综合和系统的划分。划分的结果应体现出簇内各区县特征相对一致,簇间各区县数据特征相差最大,即同一发展特征的区县聚为一簇。空间聚类算法的分析重点在于对基于空间距离的空间相似性和基于属性的非空间相似性的融合。从算法的角度,需要讨论算法是否有较好的可伸缩性、效率,算法能否处理不同类型属性的数据,是否能够发现任意形状的聚类,以及是否具有良好的处理噪声数据的能力(Grubesic et al, 2014)。主要的聚类算法包括以下4种(Duda et al, 2001):基于划分的聚类算法(Hagen et al, 2006)、基于层次的聚类算法(Gómeza et al, 2015)、基于密度的聚类算法(Zhou et al, 2011)、基于神经网络的聚类算法(Lin et al, 2007)。本文对4种聚类算法进行比较试验研究。
(1) K-means
K-means是基于划分的聚类方法。其聚类过程为:首先,需要确定K个质心,即希望聚成的簇的数量;其次,鉴于每个指标代表空间内一个维度的坐标,计算各指标的欧氏距离,并集成计算对象间的空间距离;第三,多次运行,使每次每组随机选择质心,直到选取具有最小误差平方和的簇集;第四,计算所有像素点到质点的距离,假使像素点P距离质点S最近,那么P属于S簇;最后,迭代算法直至聚类结果稳定。
(2) Chameleon
Chameleon聚类算法属于自下而上的层次聚类算法。但与一般的凝聚聚类算法不同,Chameleon算法以树的形式分为2个主要阶段(Gómeza et al, 2015)。第一个阶段将分散的对象点,采用k最近邻算法连接起来,形成若干小簇。簇的每一个节点表示数据项,每一条边表示数据项的相似度,各指标集成计算出的空间欧氏距离即为每一条边的长度;第二个阶段计算任意2个簇的相对互连性RI和相对互连性RC和度量函数Metric,合并2个子簇。合并过程为:首先给定度量函数距离阈值MinMetric。访问每个簇,计算它与邻近的每个簇的相对互连性RI和相对互连性RC,通过度量函数公式计算出临时距离TempMetric。找到最大的临时距离,如果最大的临时距离超过距离阈值,则将簇与此值对应的簇合并。如果找到的最大的临时距离没有超过距离阈值,则表明此聚簇已合并完成,移除聚簇列表,加入到结果聚簇中。递归此步骤,直到待合并聚簇列表最终大小为空(Gómeza et al, 2015)。
式中:|Ci|为簇i内数据点的个数;EC(Ci)为簇i内所有边的加权和;EC(Ci, Cj)为跨越2个簇的所有边的加权和。
(3) DBSCAN
DBSCAN是基于密度的聚类算法,在计算中需先确定2个参数:一是簇扫描半径Eps,它表示以给定点P为中心,Eps为半径的邻域范围;二是以P为中心的邻域内最小包含点数阈值。DBSCAN聚类的过程为:首先,扫描整个数据集,将各指标通过计算欧氏距离的方法集成计算对象点间的空间距离,每个指标代表空间内一个维度的坐标;其次,确定一个核心点P,寻找从该核心点出发的所有密度相连的数据点对点P所在簇进行扩充(Baselice et al, 2015)。遍历该核心点P为中心,Eps为半径的邻域内的所有核心点,寻找与这些数据点密度相连的点,直到没有可以扩充的数据点为止,使聚类成簇的边界节点都是非核心数据点;第三,重新扫描剩下的数据集,寻找没有被聚类的核心点,再重复上面的步骤,对该核心点进行扩充直到数据集中没有新的核心点为止。
(4) SOM
SOM聚类由Tenvo Kohonen提出(Kohonen, 1990),是一种无监督学习的聚类算法(Bação et al, 2005)。它由m个神经元组成的输入层和由a
式中:
通过计算,得到具有最近距离的胜出神经元即为j*,并给出临近神经元集合。根据式(5)修正j*及其邻近神经元的权值。
式中:
因为不同数据集的数据特征不同,所以并不存在一种聚类算法适用于所有的数据集。4种聚类算法的优缺点见表2。
表2 4种聚类算法效果比较表
Tab.2 Comparison of the characteristics of four clustering algorithms
| 算法 | 算法效率 | 适合的数据类型 | 发现的聚类类型 | 对噪声数据或异常数据的敏感性 | 对输入顺序的敏感性 | 其他 |
|---|---|---|---|---|---|---|
| K-means | 高 | 数值 | 凸形或球形 | 不敏感 | 一般 | 易于理解和实现,时间复杂度低 |
| Chameleon | 一般 | 任意 | 任意形状 | 不敏感 | 不敏感 | 算法灵活但执行时间长 |
| DBSCAN | 一般 | 数值 | 任意形状 | 敏感 | 敏感 | 处理高纬度数据效果差 |
| SOM | 高 | 任意 | 任意形状 | 不敏感 | 敏感 | 结果有特征映射,能可视化 |
可以看出,K-means和Chameleon算法只能对点数据和基于距离的空间相似性进行分析聚类,无法做到对不同属性的数据进行相似性分析。DBSCAN可以同时考虑空间和属性数据的相似性,SOM作为辅助性聚类方法也同时考虑了空间和属性特征。
京津冀城市群各区县的等级应由该区县的中心性来衡量,中心性越大,为周围地区提供的货物越多,则所要求的门槛人口越多,吸引和影响的范围就越大,中心地的等级越高;反之,中心地等级越低(Bell et al, 2015)。不同研究对中心性指标的选取不尽相同 (马林靖等, 2010; 韩玉刚等, 2016)。为全面地衡量各区县的中心性,本文从经济中心性、信息中心性、交通中心性和人口中心性4个角度,综合评价各区县的等级。其中,以GDP表征经济中心性;以社交网络(新浪微博)签到数表征信息中心性;以铁路吸引子和公路路网密度表征交通中心性(马林靖等, 2010);以人口总数表征人口中心性。鉴于新浪微博为代表的新型网络社区已成为当代人们交流的新型媒介(王波等, 2016),以社交网络签到数据表征区域的信息中心性。通过互联网爬虫技术推算的客流量刻画交通中心性。网络爬取12306铁路列车班次、始发站、终点站、余票量等信息,并依此测算各区县铁路交通吸引力。选定2016年7月25-29日余票总数作为淡季余票的样本,2016年7月30-31日作为旺季余票的样本;同时选定2016年10月6日的余票作为“十一黄金周”特殊时段的余票样本。
本文假设:已获取的工作日、休息日余票数据样本作为实验样本,代表铁路客运正常运营水平。特殊节假日的数据,由“十一黄金周”客流情况作为代替。代入铁路日均客流量计算,铁路承载的客流量如下:
式中:
为量化各个区县客流吸引能力,使之能够作为区县分级的重要指标之一,定义吸引因子ε如下:
式中:
在K-means算法实验中,通过计算不同K值聚类结果的各簇内对象点的距离均值和类间距离均值的比值,当K为5时,类内距离均值和类间距离均值比值曲线趋于平滑,且距离均值和类间距离均值比值标准差较小,所以选择聚类簇数为5。同理,SOM算法的输入神经元个数也为5。Chameleon和DBSCAN算法的各参数由实验时对照不同实验结果的参数进行微调得到(表3)。可以看出,K-means算法和SOM算法的迭代次数均是使聚类结果稳定的相对较小迭代次数。
表3 聚类算法参数设置表
Tab.3 Parameters of the four clustering algorithms
| 聚类算法 | 参数设置 |
|---|---|
| K-means | 质心个数k=5;迭代次数n=15 |
| Chameleon | k最邻近值设定为k=3;度量函数距离阈值MinMetric=0.015 |
| DBSCAN | 中心点P的扫描邻域半径Eps=3;以P为中心的邻域内最小包含点数阈值min=3 |
| SOM | 输入层输入神经元k=5;迭代次数n=300 |
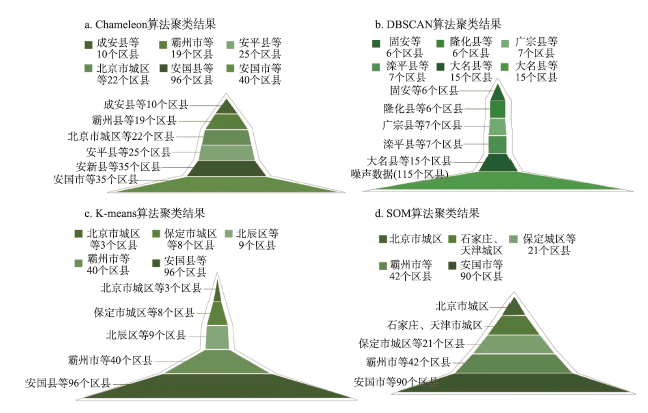
各聚类算法最终计算结果如表4和图1所示。从聚类结果看,K-means能成功地将京津冀城市群区域分为合理的5级,但未能识别出城市群核心区,且大多数区县被划在最低级别,这种基于简单距离划分的聚类方法,未能发现大小差别很大的簇。Chameleon算法能适应线性分布的数据几何形状,但是划分出的6类数据缺乏逻辑关系,即数值明显较小的区县被划在了较高簇群,而数值高的区县则没有被安放在较高层。DBSCAN算法将大部分数据归于噪声,也就是说当数据集的密度不均、类间距差相差很大时,基于密度的DBSCAN算法聚类效果不好。
表4 4种聚类算法结果
Tab.4 Results of the four cluster algorithms
| 第一类 | 第二类 | 第三类 | 第四类 | 第五类 | 第六类 | |
|---|---|---|---|---|---|---|
| K-means | 北京市城区等3个区县 | 保定市城区等8个区县 | 北辰区等9个区县 | 霸州市等40个区县 | 安国县等96个区县 | |
| Chameleon | 成安县等10个区县 | 霸州市等19个区县 | 安平县等25个区县 | 北京市城区等22个区县 | 安新县等35个区县 | 安国市等40个区县 |
| DBSCAN | 固安县等6个区县 | 隆化县等6个区县 | 广宗县等7个区县 | 滦平县等7个区县 | 大名县等15个区县 | 噪声数据(115个区县) |
| SOM | 北京市城区 | 石家庄、天津市城区 | 保定市城区等21个区县 | 霸州市等42个区县 | 安国市等90个区县 |
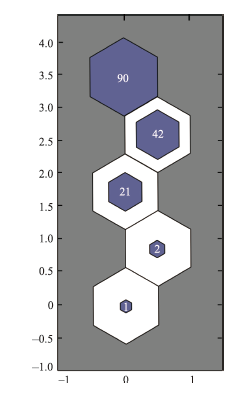
图1 聚类结果网络层次结构特性漏斗图
Fig.1 Funnel plot of network hierarchical characteristic of the clustering result
SOM算法通过输入模式反复学习,获取各个输入数据特征,从空间数据相似性出发,基于五维数据的非空间属性特征进行自组织,基于神经元之间的距离,得到5个神经元内分别含有90,42,21,2,1个数据节点,整体呈现正三角形的空间稳定结构。从结果来看,SOM算法将京津冀城市群各区县分为5级,且竞争层节点间存在逻辑和拓扑关系(图2-3)。最上方小正六边形代表SOM聚类结果的第五类(安国市等90个区县),第二个小正六边形代表第四类(霸州市等42个区县),第三个小六边形代表第三类(保定市城区等21各区县),第四个小六边形代表第二类(石家庄和天津市城区),最下方小六边形代表第一类(北京市城区)。由此可见,SOM算法能准确识别区县间的数据差别并设定类间距离,并在结果中显示,比较适合城市群区域空间网络层级划分。
根据克氏中心地理论,德国南部地区在市场、交通、行政三原则共同作用下,一个地区城镇等级体系应当由1个一级城市,2个二级城市,6~12个三级城市,42~54个四级城市,118个五级城市组成(Bell et al, 2015)。下面对基于SOM聚类算法得到的京津冀城市群5级结构进行空间分析。
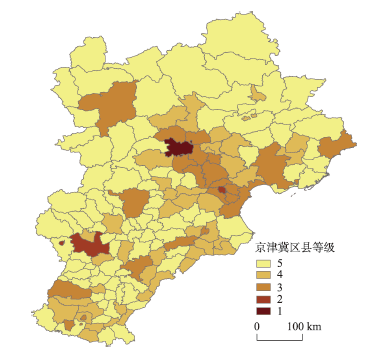
京津冀区域标准化后的各区县数据如表5。可以看出,北京作为全国的政治中心、文化中心、国际交流中心、科技创新中心,具有明显优势,是无可争议的一级区域辐射核心。其中,北京在人口中心性、经济中心性和信息中心性等方面优势尤为显著。从京津冀协同发展的角度,北京城区应加快推动与首都功能不符合的功能转移,辐射带动周边区县快速发展,缓解核心城区的交通、人口、就业等压力,并力争在生态、住房、教育、养老、医疗、环境、科技等领域取得引领性突破。二级区县包括石家庄城区和天津城区。其中,石家庄城区作为京津冀南部地区唯一核心,承担着联合南部区县加强承接京津两市的功能疏解和协同任务。第三级别的区县中,位于京津冀城市群东北部的唐山城区和秦皇岛城区以及位于北部的承德城区,对京津冀城市群区域协同均有重要作用。环京津的欠发达区县多处于第四、五级,大部分位于京津冀西部和北部地区。就吸引因子而言,第二级区县路网密度平均值高于第一级,表明第二级区县的交通基础设施较第一级区县更为完善;京津冀城市群区域各区县交通中心性差距较小,说明区域发展到一定程度后,交通设施已经接近区域均等化,成为京津冀协同发展的基本条件。
表5 各级别区县数据标准化后平均值
Tab.5 Average values of every level of districts and counties after normalization
| 人口 | GDP | 路网密度 | 吸引因子 | 微博签到数 | |
|---|---|---|---|---|---|
| 第一级 | 1.000000 | 1.000000 | 0.566022 | 0.925568 | 1.000000 |
| 第二级 | 0.187632 | 0.323590 | 0.712439 | 0.824197 | 0.089826 |
| 第三级 | 0.079778 | 0.066928 | 0.263885 | 0.202920 | 0.016356 |
| 第四级 | 0.015132 | 0.036220 | 0.096532 | 0.052529 | 0.003622 |
| 第五级 | 0.008050 | 0.025172 | 0.048087 | 0.013577 | 0.000620 |
从京津冀各级区县的空间结构和发展态势来看,京津冀城市群正从以北京为单核心的圈层结构向带型空间结构转变(图4)。其中,京津两市之间的区域是先行发展成熟的都市走廊,对周边区县辐射效果明显,总体发展在城市群之中处于领先水平。包括秦皇岛、唐山、天津、沧州等区县的沿海都市发展带也已初具规模,基本连片,成为京津冀沿海战略推进的重要空间。其中,天津应集中提升滨海新区的发展规模和层级,打造为北方地区的物流枢纽中心,形成最便利的海关通关,经济承接北京城区的功能疏解和科技成果转化任务。包括雄安新区、石家庄等在内的沿京广交通走廊都市发展带正在孕育,将成为京津冀城市群未来增长潜力最大的带型区域。尤其是雄安新区的开发建设,将是京津冀城市群京石都市发展带的重大引爆点,推动京津冀城市群区域结构的加速优化。作为北京、天津功能疏解的主要承接地,河北省各区县应继续加强交通网络基础设施建设,提高交通可达性。尤其是石家庄、唐山、秦皇岛3城区应积极发挥次区域辐射核心的带动作用,加快城市群南部地区和东北部地区各区县的协同发展。承德和张家口作为西部地区的三级城区,应分别承担起带动京津冀城市群西北部和北部协同发展的任务,通过加强与京津两市科技、文化交流和产业对接,促进西北部和北部山区的绿色产业发展。
通过4种聚类算法对比试验发现,非监督学习的自组织特征映射(SOM)算法比较适合于城市群区域的等级划分:一是基于神经网络的自组织特征映射(SOM)算法结果的区县簇等级结构较为合理,由低级别至高级别呈明显的三角型稳定结构;二是簇间区别明显,能够准确甄别出区域核心城区及其他级别区县。
基于SOM算法对京津冀城市群的聚类结果显示:①京津冀城市群正从以北京为单核心的圈层结构向3条带型空间结构转变;其中京津城区优势明显,在多数维度上与其他区县差距较大,应该凸显其作为区域辐射核心的带动作用;②京津冀城市群的五级数量结构符合克里斯塔勒的中心地理论,城市群空间结构较稳定;③京津冀城市群正在形成3条空间发展带,推动京津冀协同发展,其中,京津都市发展走廊已经发育成熟,沿海都市发展带也已初具规模,包括雄安新区的京石都市发展带正在加速孕育。
下一步研究可集中在以下两方面:一是进一步挖掘京津冀城市群的等级数量结构和空间结构的内涵,形成更完善的城市群空间网络体系;二是将基于神经网络的自组织特征映射(SOM)聚类算法扩大到全国城市群区域的等级结构分析,根据不同城市群地区的数据特点,调整参数,完善方法,最终形成一种可适用于广泛区域的城市群等级划分通解。
The authors have declared that no competing interests exist.
| [1] |
城市群空间联系能力与SOM 神经网络分级研究: 以辽中南城市群为例 [J].
以辽中南城市群为例,通过经济联系强度模型、城市流模型和城市通达性模型,构建系列空间联系能力数理模型,定量分析辽中南城市群空间联系能力的空间分异特征。在此基础上构建了SOM神经网络分级模型,以评价辽中南城市群十个节点城市的空间联系能力。研究表明:①沈阳的经济联系总量最大,沈阳与其他城市的经济联系强度和沈阳距其铁路距离呈S形曲线关系。②依据城市流强度值的大小将辽中南城市群十个节点城市划分为高、中、低三个档次,大连的值最大,营口则显现出作为该城市群中部区域极点的潜力。③沈大高速公路集中了通达性处于前三位的三个城市,辽阳在城市通达性方面显现出显著的优势,四项通达性指标全位居第一。④从SOM神经网络的分级结果看,沈阳都作为独立的一级,表明沈阳的空间联系能力最强,体现了其中心性的地位。
Spatial combination capacity and classification based on SOM network of urban agglomerations: A case study of central and southern Liaoning urban agglomerations [J].
以辽中南城市群为例,通过经济联系强度模型、城市流模型和城市通达性模型,构建系列空间联系能力数理模型,定量分析辽中南城市群空间联系能力的空间分异特征。在此基础上构建了SOM神经网络分级模型,以评价辽中南城市群十个节点城市的空间联系能力。研究表明:①沈阳的经济联系总量最大,沈阳与其他城市的经济联系强度和沈阳距其铁路距离呈S形曲线关系。②依据城市流强度值的大小将辽中南城市群十个节点城市划分为高、中、低三个档次,大连的值最大,营口则显现出作为该城市群中部区域极点的潜力。③沈大高速公路集中了通达性处于前三位的三个城市,辽阳在城市通达性方面显现出显著的优势,四项通达性指标全位居第一。④从SOM神经网络的分级结果看,沈阳都作为独立的一级,表明沈阳的空间联系能力最强,体现了其中心性的地位。
|
| [2] |
北京市各区县经济分析的聚类方法 [J].https://doi.org/10.3969/j.issn.1002-1566.1999.01.006 URL 摘要
本文讨论用聚类分析方法分析大城市城郊区经济发展的问题.以北京市经济94-95两年统计数据为基础,按照多种经济意义进行多次分类,提供了一种分析多层次大城市区域经济特点的方法.
Clustering analysis on the economy of Beijing regions [J].https://doi.org/10.3969/j.issn.1002-1566.1999.01.006 URL 摘要
本文讨论用聚类分析方法分析大城市城郊区经济发展的问题.以北京市经济94-95两年统计数据为基础,按照多种经济意义进行多次分类,提供了一种分析多层次大城市区域经济特点的方法.
|
| [3] |
基于功能区的行政区划调整研究: 以绍兴城市群为例 [J].https://doi.org/10.11821/dlxb201508001 URL 摘要
本文构建了基于功能区的行政区划调整研究框架.首先,运用功能区思想,以大城市地区的街道或乡镇为空间单元,采集相关的自然、历史、文化、产业、客流和信息流数据,进行要素功能区的分析,准确获取不同层次相互依赖的功能空间单元,使城市在空间上充分适应和支撑多变的社会经济环境,为城市的多样性提供充分的弹性空间依据.其次,在城市基层单元的要素功能区的基础上,进一步采用因子分析和聚类分析方法,进行城市功能区的划分,可以为行政区划调整提供基于城市功能区有机的空间组织科学依据.在上述行政区划调整研究框架的基础上,以绍兴市为例进行了案例研究,结果表明,绍兴市域内自然、文化功能区清晰,块状经济特征明显,基层区之间的经济、文化、通勤和信息联系已经突破现在的市县行政区边界,按照综合功能区的思想进行行政区划调整.总体上说,基于功能区的行政区划调整,对大城市地区或城市群地区,保证其物质环境和社会空间的快速和谐发展,有效利用资源,具有重要的科学意义和实用价值.
Research on administrative divisions based on functional areas analysis: A case of Shaoxing metropolitan area [J].https://doi.org/10.11821/dlxb201508001 URL 摘要
本文构建了基于功能区的行政区划调整研究框架.首先,运用功能区思想,以大城市地区的街道或乡镇为空间单元,采集相关的自然、历史、文化、产业、客流和信息流数据,进行要素功能区的分析,准确获取不同层次相互依赖的功能空间单元,使城市在空间上充分适应和支撑多变的社会经济环境,为城市的多样性提供充分的弹性空间依据.其次,在城市基层单元的要素功能区的基础上,进一步采用因子分析和聚类分析方法,进行城市功能区的划分,可以为行政区划调整提供基于城市功能区有机的空间组织科学依据.在上述行政区划调整研究框架的基础上,以绍兴市为例进行了案例研究,结果表明,绍兴市域内自然、文化功能区清晰,块状经济特征明显,基层区之间的经济、文化、通勤和信息联系已经突破现在的市县行政区边界,按照综合功能区的思想进行行政区划调整.总体上说,基于功能区的行政区划调整,对大城市地区或城市群地区,保证其物质环境和社会空间的快速和谐发展,有效利用资源,具有重要的科学意义和实用价值.
|
| [4] |
中国欠发达省际边缘区核心城市的选择与区域带动效应: 以豫皖省际边缘区为例 [J].https://doi.org/10.11821/dlyj201606010 URL [本文引用: 1] 摘要
中国省际边缘区由于边缘性区位条件、增长核心缺乏、发展政策缺位等因素综合影响,相对省域核心区而言一般较为落后.豫皖省际边缘区是中国较为典型的“弱弱型”省际边缘区,核心城市实力弱小、相互联系有限、空间经济结构松散,急需遴选核心城市,重构区域空间结构,以推进豫皖省际边缘区的快速发展.基于此种思考,从城市规模、商业服务、公共服务、交通通讯4个维度构建了城市中心性评价模型,利用因子分析法和熵值法测度豫皖省际边缘区城市中心性,利用场强模型和GIS技术划分城市腹地.结果表明:在豫皖省际边缘区城市中,阜阳市中心性得分总分最高,在城市规模和交通通讯方面得分领先于其他城市,具有建设成豫皖省际边缘区核心城市的内部基础;阜阳市的腹地面积最大,直接腹地跨越了阜阳市市域、豫皖省界的范围,触及豫皖省际边缘区的所有城市,具有建设成为豫皖省际边缘区核心城市的外部环境.最后结合阜阳市内外发展条件,从跨界空间整合、内外交通组织、产业联动协同、经济社会示范4个方面,分析了其对豫皖省际边缘区的区域带动效应.
Core city selection in Chinese undeveloped provincial border-region and its promoting effects on regional development: A case study of Anhui-Henan Provincial Border-region [J].https://doi.org/10.11821/dlyj201606010 URL [本文引用: 1] 摘要
中国省际边缘区由于边缘性区位条件、增长核心缺乏、发展政策缺位等因素综合影响,相对省域核心区而言一般较为落后.豫皖省际边缘区是中国较为典型的“弱弱型”省际边缘区,核心城市实力弱小、相互联系有限、空间经济结构松散,急需遴选核心城市,重构区域空间结构,以推进豫皖省际边缘区的快速发展.基于此种思考,从城市规模、商业服务、公共服务、交通通讯4个维度构建了城市中心性评价模型,利用因子分析法和熵值法测度豫皖省际边缘区城市中心性,利用场强模型和GIS技术划分城市腹地.结果表明:在豫皖省际边缘区城市中,阜阳市中心性得分总分最高,在城市规模和交通通讯方面得分领先于其他城市,具有建设成豫皖省际边缘区核心城市的内部基础;阜阳市的腹地面积最大,直接腹地跨越了阜阳市市域、豫皖省界的范围,触及豫皖省际边缘区的所有城市,具有建设成为豫皖省际边缘区核心城市的外部环境.最后结合阜阳市内外发展条件,从跨界空间整合、内外交通组织、产业联动协同、经济社会示范4个方面,分析了其对豫皖省际边缘区的区域带动效应.
|
| [5] |
基于GIS的中国城市群发育格局识别研究 [J].The identification of urban agglomeration distribution in China based on GIS analysis [J]. |
| [6] |
聚类方法综述 [J].Review of clustering method [J]. |
| [7] |
京津冀地区人口与经济协调发展关系研究 [J].https://doi.org/10.18306/dlkxjz.2017.01.003 URL [本文引用: 1] 摘要
京津冀地区是中国重要的人口集聚区和经济增长极,在京津冀协同发展的背景下研究京津冀地区人口与经济的协调发展关系,对于促进区域内经济的可持续发展具有重要意义。本文基于京津冀地区2000-2010年各区(县)和2000-2014年各城市的人口、GDP数据,运用人口—经济增长弹性、地理集中度、不一致指数、重心分析等方法探究京津冀地区人口与经济的协调发展关系,结果表明:1在总量规模上,京津冀地区整体人口增长与经济增长的协调度较高,但各城市人口增长与经济增长的协调度存在较大差异。2在空间分布上,从地理集中度来看,京津冀地区人口、经济地理集中度均呈现北部低、中南部高的分布特征,其中北京、天津经济地理集中度高于人口地理集中度,河北多数城市人口地理集中度高于经济地理集中度;从重心来看,京津冀地区整体的人口与经济重心都向东北方向移动,且经济重心的移动幅度大于人口重心,2个重心偏离距离不断加大,此外各城市的人口重心与经济重心也出现不同程度的分离。最后,提出了促进京津冀地区人口与经济协调发展的政策建议。
Coordinated development between population and economy in the Beijing-Tianjin-Hebei region [J].https://doi.org/10.18306/dlkxjz.2017.01.003 URL [本文引用: 1] 摘要
京津冀地区是中国重要的人口集聚区和经济增长极,在京津冀协同发展的背景下研究京津冀地区人口与经济的协调发展关系,对于促进区域内经济的可持续发展具有重要意义。本文基于京津冀地区2000-2010年各区(县)和2000-2014年各城市的人口、GDP数据,运用人口—经济增长弹性、地理集中度、不一致指数、重心分析等方法探究京津冀地区人口与经济的协调发展关系,结果表明:1在总量规模上,京津冀地区整体人口增长与经济增长的协调度较高,但各城市人口增长与经济增长的协调度存在较大差异。2在空间分布上,从地理集中度来看,京津冀地区人口、经济地理集中度均呈现北部低、中南部高的分布特征,其中北京、天津经济地理集中度高于人口地理集中度,河北多数城市人口地理集中度高于经济地理集中度;从重心来看,京津冀地区整体的人口与经济重心都向东北方向移动,且经济重心的移动幅度大于人口重心,2个重心偏离距离不断加大,此外各城市的人口重心与经济重心也出现不同程度的分离。最后,提出了促进京津冀地区人口与经济协调发展的政策建议。
|
| [8] |
DBSCAN空间聚类算法及其在城市规划中的应用 [J].https://doi.org/10.3771/j.issn.1009-2307.2005.03.014 URL 摘要
空间聚类是空间数据挖掘和知识发现的主要方法之一.DBSCAN算法可以从带有'噪声'的空间数据库中发现任意形状的聚类,是一种较好的聚类算法.本文介绍了DBSCAN算法的基本概念和原理,并应用GIS二次开发组件MapObjects予以了实现.然后,本文将该算法应用于城市规划中,对某城市中小学和商业网点等公共设施的分布进行了聚类分析,并根据聚类结果对城市规划设计规范中的某些条款进行了讨论.
DBSCAN spatial clustering algorithm and its application in urban planning [J].https://doi.org/10.3771/j.issn.1009-2307.2005.03.014 URL 摘要
空间聚类是空间数据挖掘和知识发现的主要方法之一.DBSCAN算法可以从带有'噪声'的空间数据库中发现任意形状的聚类,是一种较好的聚类算法.本文介绍了DBSCAN算法的基本概念和原理,并应用GIS二次开发组件MapObjects予以了实现.然后,本文将该算法应用于城市规划中,对某城市中小学和商业网点等公共设施的分布进行了聚类分析,并根据聚类结果对城市规划设计规范中的某些条款进行了讨论.
|
| [9] |
中国经济地理学研究进展与展望 [J].https://doi.org/10.11820/dlkxjz.2011.12.003 URL Magsci [本文引用: 1] 摘要
经济地理学是地理学最重要的分支学科之一,在社会实践中发挥着重要作用.长期以来,中国经济地理学的发展可以用“以任务带学科”来概括,形成了具有中国特色的“实践派”经济地理学.近年来,中国经济地理学发展的突出特点表现为:规划导向、综合导向、“区域主义”、基于GIS的空间分析和可视化表达愈来愈普遍、国际化趋势明显.在研究方向上,除了传统优势领域得到强化外,出现了若干新的研究方向,包括功能区划分、能源与碳排放、全球化与外资外贸、生产性服务业、信息技术与互联网,以及农区地理与农户区位研究等.在人地系统与区域可持续发展,区域发展新因素与新格局,产业集群与产业集聚,全球化、跨国公司及外资,交通运输地理与空间组织,资源型城市及老工业城市转型,应对气候变化与低碳经济,海洋经济地理,地域空间规划方法等领域取得了较为显著的进展.在国家重大地域空间规划中发挥了重要的技术支撑作用,包括主体功能区划、东北振兴规划、西部大开发战略实施、中部崛起规划、资源枯竭型城市规划、生态区域建设规划,以及长江三角洲地区、京津冀地区、成渝地区等重点区域规划.未来经济地理学的发展既拥有机遇、也面临着挑战.在满足国家重大需求的同时,需要更加重视理论总结和人才培养.
Progress in economic geography (2006-2011) [J].https://doi.org/10.11820/dlkxjz.2011.12.003 URL Magsci [本文引用: 1] 摘要
经济地理学是地理学最重要的分支学科之一,在社会实践中发挥着重要作用.长期以来,中国经济地理学的发展可以用“以任务带学科”来概括,形成了具有中国特色的“实践派”经济地理学.近年来,中国经济地理学发展的突出特点表现为:规划导向、综合导向、“区域主义”、基于GIS的空间分析和可视化表达愈来愈普遍、国际化趋势明显.在研究方向上,除了传统优势领域得到强化外,出现了若干新的研究方向,包括功能区划分、能源与碳排放、全球化与外资外贸、生产性服务业、信息技术与互联网,以及农区地理与农户区位研究等.在人地系统与区域可持续发展,区域发展新因素与新格局,产业集群与产业集聚,全球化、跨国公司及外资,交通运输地理与空间组织,资源型城市及老工业城市转型,应对气候变化与低碳经济,海洋经济地理,地域空间规划方法等领域取得了较为显著的进展.在国家重大地域空间规划中发挥了重要的技术支撑作用,包括主体功能区划、东北振兴规划、西部大开发战略实施、中部崛起规划、资源枯竭型城市规划、生态区域建设规划,以及长江三角洲地区、京津冀地区、成渝地区等重点区域规划.未来经济地理学的发展既拥有机遇、也面临着挑战.在满足国家重大需求的同时,需要更加重视理论总结和人才培养.
|
| [10] |
基于聚类分析法的县域均衡发展指数构建与测度应用研究: 以天津12个涉农区县为例 [J].https://doi.org/10.3969/j.issn.1006-1096.2010.02.014 URL [本文引用: 2] 摘要
县域发展是全面建设小康社会、统筹解决"三农"问题、推进新农村 建设的重要载体.笔者以科学发展观为指导思想构建了县域均衡发展指数,并以天津地区的12个涉农区县为例通过聚类分析法对县域的经济、社会、环境发展情况 进行了全面、科学地多层次、多角度测度,结果显示:不通类型的区县具有各自的发展特点、优势和弱点.发达区县在充分发挥示范效应、传播积极经验的同时更需 注重总体均衡发展,特别是环境和区县政府的政策方面,继续加大工业对农业反哺的力度;而落后区县则应大幅度提高工业化水平,加快农村剩余劳动力转移,在继 续加大农业投入的基础上充分利用自身资源优势和特色提高农业劳动生产率,通过乡村推力、城镇拉力有步骤地稳步提高城市化水平和城乡一体化进程.
A research into the construction and measurement of county balanced development indexes and its application based on cluster analysis method [J].https://doi.org/10.3969/j.issn.1006-1096.2010.02.014 URL [本文引用: 2] 摘要
县域发展是全面建设小康社会、统筹解决"三农"问题、推进新农村 建设的重要载体.笔者以科学发展观为指导思想构建了县域均衡发展指数,并以天津地区的12个涉农区县为例通过聚类分析法对县域的经济、社会、环境发展情况 进行了全面、科学地多层次、多角度测度,结果显示:不通类型的区县具有各自的发展特点、优势和弱点.发达区县在充分发挥示范效应、传播积极经验的同时更需 注重总体均衡发展,特别是环境和区县政府的政策方面,继续加大工业对农业反哺的力度;而落后区县则应大幅度提高工业化水平,加快农村剩余劳动力转移,在继 续加大农业投入的基础上充分利用自身资源优势和特色提高农业劳动生产率,通过乡村推力、城镇拉力有步骤地稳步提高城市化水平和城乡一体化进程.
|
| [11] |
城市群多层次空间结构分析算法及其应用:以京津冀城市群为例 [J].https://doi.org/10.11821/dlyj201508004 URL [本文引用: 1] 摘要
Urban agglomeration plays a key role for China in attending the global divisions of labor, international competitions, as well as the integration of regional economy. Various scholars have dedicated to the study of urban agglomeration. However there is no consensus on the definition of urban agglomeration, which leads to the controversy. Relations between each city-pair in an urban agglomeration may form a complex network which brings a great challenge for researchers to use traditional method to synthetically analyze the spatial structure, due to the exponential calculation time increased by a great number of nodes. Based on the summary of different definitions, a novel method is developed to analyze the multi-level spatial structure of an urban agglomeration. We first find the core cities by calculating the urban centrality of each city in an urban agglomeration using several selected indices. To be specific, the spatial scope of the urban agglomeration can be defined as the 2-hour commute range of each core city. Then interaction intensities between each pair of cities are calculated based on the traffic accessibility and cities' scale. We develop an algorithm to analyze the spatial structure based on the so-called Multi-level Spatial Structure Tree (MSS-Tree), which can be used to analyze the urban agglomeration structure in detail. Finally, we carry out the sample study of Beijing-Tianjin-Hebei urban agglomeration to testify the model. The experimental results show that due to the centrality of Beijing downtown area, cities or towns around Beijing have much more interactions with Beijing than among themselves. It could be concluded that mature sub-center cities or towns around Beijing are needed to take the responsibility of service provision. In comparison, Tianjin downtown area and Tianjin coastal district have double cores in Tianjin. Hengshui city far away from Beijing downtown area has the potential to become a secondary central city in the near future. The case study also demonstrates that the algorithm based on the MSS-Tree data is an effective method for the spatial analysis of an urban agglomeration, and can play an important role in subsequent decision makings of urban agglomeration development.
A multi-level spatial structure analysis algorithm for urban agglomeration study in China [J].https://doi.org/10.11821/dlyj201508004 URL [本文引用: 1] 摘要
Urban agglomeration plays a key role for China in attending the global divisions of labor, international competitions, as well as the integration of regional economy. Various scholars have dedicated to the study of urban agglomeration. However there is no consensus on the definition of urban agglomeration, which leads to the controversy. Relations between each city-pair in an urban agglomeration may form a complex network which brings a great challenge for researchers to use traditional method to synthetically analyze the spatial structure, due to the exponential calculation time increased by a great number of nodes. Based on the summary of different definitions, a novel method is developed to analyze the multi-level spatial structure of an urban agglomeration. We first find the core cities by calculating the urban centrality of each city in an urban agglomeration using several selected indices. To be specific, the spatial scope of the urban agglomeration can be defined as the 2-hour commute range of each core city. Then interaction intensities between each pair of cities are calculated based on the traffic accessibility and cities' scale. We develop an algorithm to analyze the spatial structure based on the so-called Multi-level Spatial Structure Tree (MSS-Tree), which can be used to analyze the urban agglomeration structure in detail. Finally, we carry out the sample study of Beijing-Tianjin-Hebei urban agglomeration to testify the model. The experimental results show that due to the centrality of Beijing downtown area, cities or towns around Beijing have much more interactions with Beijing than among themselves. It could be concluded that mature sub-center cities or towns around Beijing are needed to take the responsibility of service provision. In comparison, Tianjin downtown area and Tianjin coastal district have double cores in Tianjin. Hengshui city far away from Beijing downtown area has the potential to become a secondary central city in the near future. The case study also demonstrates that the algorithm based on the MSS-Tree data is an effective method for the spatial analysis of an urban agglomeration, and can play an important role in subsequent decision makings of urban agglomeration development.
|
| [12] |
网络社区交流中距离的作用: 以新浪微博为例 [J].The role of distance in online social networks: A case study of Sina micro-blog [J]. |
| [13] |
机器学习的主要策略综述 [J].https://doi.org/10.3969/j.issn.1001-3695.2004.07.002 URL [本文引用: 1] 摘要
当前人工智能研究的主要障碍和发展方向之一就是机器学习.机器学习与计算机科学、心理学、认知科学等各种学科都有着密切的联系,牵涉的面比较广,许多理论及技术上的问题尚处于研究之中.对机器学习的一些主要策略的基本思想进行了较全面的介绍,同时介绍了一些最新的进展和研究热点.
A survey on machine learning and its main strategy [J].https://doi.org/10.3969/j.issn.1001-3695.2004.07.002 URL [本文引用: 1] 摘要
当前人工智能研究的主要障碍和发展方向之一就是机器学习.机器学习与计算机科学、心理学、认知科学等各种学科都有着密切的联系,牵涉的面比较广,许多理论及技术上的问题尚处于研究之中.对机器学习的一些主要策略的基本思想进行了较全面的介绍,同时介绍了一些最新的进展和研究热点.
|
| [14] |
金融空间联系及K-means聚类中心等级识别研究: 以长三角为例 [J].
<p>以2001年、2006年、2011年长三角城市金融机构人民币存款、贷款额数为样本,构建金融空间联系模型,定量分析长三角城市金融空间联系分异特征.在此基础上构建K-means 金融中心等级识别模型,识别长三角城市金融中心等级.研究表明:① 2001~2011 年长三角城市金融“质量”空间趋势较为稳定,总体呈现东部高于西部,中部高于南、北部的倒U形分布.② 金融空间联系最大引力线联结格局较为稳定.③ 金融空间联系网络结构格局变化显著,主要从简单的“折线型”空间结构逐渐发展成简单的、复杂的“网络型”空间结构.④ 长三角金融城市中心等级空间分布格局稳定,以上海市金融中心最为突出.</p>
Spatial combination of finance and center level identify based on K-means clustering: A case study of the Changjiang river delta [J].
<p>以2001年、2006年、2011年长三角城市金融机构人民币存款、贷款额数为样本,构建金融空间联系模型,定量分析长三角城市金融空间联系分异特征.在此基础上构建K-means 金融中心等级识别模型,识别长三角城市金融中心等级.研究表明:① 2001~2011 年长三角城市金融“质量”空间趋势较为稳定,总体呈现东部高于西部,中部高于南、北部的倒U形分布.② 金融空间联系最大引力线联结格局较为稳定.③ 金融空间联系网络结构格局变化显著,主要从简单的“折线型”空间结构逐渐发展成简单的、复杂的“网络型”空间结构.④ 长三角金融城市中心等级空间分布格局稳定,以上海市金融中心最为突出.</p>
|
| [15] |
河北省县域贫困度多维评估 [J].https://doi.org/10.11820/dlkxjz.2014.01.014 URL Magsci 摘要
在京津冀加快区域经济一体化的背景下,河北省出现环绕京津地区的贫困带引起了学界与公众的普遍关注。目前国内贫困县的设定往往以经济指标为唯一度量标准,本文在经济维度基础上增加社会维度(代表人类贫困)和自然维度(代表自然贫困)两方面评价指标,构建县域贫困度多维评价指标体系,对河北省136 个县的贫困状况分别进行经济单维度与经济—社会—自然三维评估,并基于SOFM网络将全省县域贫困度划分为五级,与河北省现有各类贫困县分布进行对比。结果表明,基于经济单维度与经济—社会—自然多维度评估的聚类分析得到的高贫困度县域均与现有贫困县有很好的对应,与河北省贫困县分布现状基本吻合;由于经济—社会—自然的多维度贫困度评估综合考虑了贫困现状及其潜在可能性,评估更加全面和深入。基于自然维度的潜在贫困度对多维贫困度的影响分析表明:环京津地区的贫困现状比较严重、且潜在贫困程度高,应积极依托京津,承接产业转移。而在冀中南地区,尽管贫困现状较为严重,但潜在贫困程度较低,因其较易脱贫而容易被忽视;同时,还存在大量非贫困县转化为贫困县的可能性;应进一步加强对该地区贫困问题的关注,分类扶贫、防治结合、区域联动,促进京津冀区域一体化、社会财富同步增长。
Multidimensional evaluation of county poverty degree in Hebei Province [J].https://doi.org/10.11820/dlkxjz.2014.01.014 URL Magsci 摘要
在京津冀加快区域经济一体化的背景下,河北省出现环绕京津地区的贫困带引起了学界与公众的普遍关注。目前国内贫困县的设定往往以经济指标为唯一度量标准,本文在经济维度基础上增加社会维度(代表人类贫困)和自然维度(代表自然贫困)两方面评价指标,构建县域贫困度多维评价指标体系,对河北省136 个县的贫困状况分别进行经济单维度与经济—社会—自然三维评估,并基于SOFM网络将全省县域贫困度划分为五级,与河北省现有各类贫困县分布进行对比。结果表明,基于经济单维度与经济—社会—自然多维度评估的聚类分析得到的高贫困度县域均与现有贫困县有很好的对应,与河北省贫困县分布现状基本吻合;由于经济—社会—自然的多维度贫困度评估综合考虑了贫困现状及其潜在可能性,评估更加全面和深入。基于自然维度的潜在贫困度对多维贫困度的影响分析表明:环京津地区的贫困现状比较严重、且潜在贫困程度高,应积极依托京津,承接产业转移。而在冀中南地区,尽管贫困现状较为严重,但潜在贫困程度较低,因其较易脱贫而容易被忽视;同时,还存在大量非贫困县转化为贫困县的可能性;应进一步加强对该地区贫困问题的关注,分类扶贫、防治结合、区域联动,促进京津冀区域一体化、社会财富同步增长。
|
| [16] |
京津冀都市圈生产性服务业空间集聚特征 [J].https://doi.org/10.11820/dlkxjz.2012.06.010 URL Magsci [本文引用: 1] 摘要
促进京津冀都市圈生产性服务业集聚的协调发展成为推动制造业进步、加速产业结构升级和提高区域综合竞争力的重要途径。主要以2003-2008 年就业人数为基础数据,运用全局主成分分析、区位商、空间基尼系数、克鲁格曼专业化指数等多种方法和指标,测度了京津冀都市圈生产性服务业集聚的整体状况、行业特征及各市专门化率。分析结果表明:空间上整体呈现出一种典型非均衡的单中心、大梯度等级化集聚发展态势;商务服务、信息服务和科技服务等知识、技术和资本密集型行业在全国的专业化优势也最明显;各城市生产性服务业内部行业的结构差异都较大,专业化分工也较明显;北京的高端行业具有绝对的竞争优势和行业优势,其他9 市也各有一定的比较优势。
The spatial characteristics of producer service agglomeration in Beijing-Tianjin-Hebei metropolitan region [J].https://doi.org/10.11820/dlkxjz.2012.06.010 URL Magsci [本文引用: 1] 摘要
促进京津冀都市圈生产性服务业集聚的协调发展成为推动制造业进步、加速产业结构升级和提高区域综合竞争力的重要途径。主要以2003-2008 年就业人数为基础数据,运用全局主成分分析、区位商、空间基尼系数、克鲁格曼专业化指数等多种方法和指标,测度了京津冀都市圈生产性服务业集聚的整体状况、行业特征及各市专门化率。分析结果表明:空间上整体呈现出一种典型非均衡的单中心、大梯度等级化集聚发展态势;商务服务、信息服务和科技服务等知识、技术和资本密集型行业在全国的专业化优势也最明显;各城市生产性服务业内部行业的结构差异都较大,专业化分工也较明显;北京的高端行业具有绝对的竞争优势和行业优势,其他9 市也各有一定的比较优势。
|
| [17] |
城市中心性与我国城市中心性的等级体系 [J].https://doi.org/10.3969/j.issn.1003-2363.2001.04.001 URL [本文引用: 1] 摘要
城市中心性是指一个城市为它以外地方服务的相对重要性 ,是用以衡量城市中心地位高低的重要指标。长期以来 ,国内学术界对“中心性”的理解和应用存在偏差 ,有必要对中心性的概念和方法进行专门研究。文章在明确中心性概念 ,回顾国内外中心性相关研究的基础上 ,根据城市统计资料 ,利用最小需要量和主成分分析法 ,对 1997年全国 2 2 3个地级以上城市的中心性等级体系进行了实证研究。最后根据城市中心性指数的高低 ,把我国城市划分为五级体系。
Study of China's urban centrality hierarchy [J].https://doi.org/10.3969/j.issn.1003-2363.2001.04.001 URL [本文引用: 1] 摘要
城市中心性是指一个城市为它以外地方服务的相对重要性 ,是用以衡量城市中心地位高低的重要指标。长期以来 ,国内学术界对“中心性”的理解和应用存在偏差 ,有必要对中心性的概念和方法进行专门研究。文章在明确中心性概念 ,回顾国内外中心性相关研究的基础上 ,根据城市统计资料 ,利用最小需要量和主成分分析法 ,对 1997年全国 2 2 3个地级以上城市的中心性等级体系进行了实证研究。最后根据城市中心性指数的高低 ,把我国城市划分为五级体系。
|
| [18] |
Self-organizing maps as substitutes for K-means clustering [ |
| [19] |
A DBSCAN based approach for jointly segment and classify brain MR images [ |
| [20] |
Clusterg of services in central places [J].https://doi.org/10.1111/j.1467-8306.1974.tb00972.x URL [本文引用: 2] 摘要
Within a tertiary system entrepreneurs frequently must choose between places that command the largest local tributary population and places that possess the most desirable collection of complementary service activities. When command of tributary population is chosen over functional complementarity, the central place system increasingly assumes the clustering of activities in centers of a Losch-like system and diverges from those to be expected in a Christaller-like system. From 1960 to 1970 some activities in central Iowa were becoming more closely associated with other activities, but others were becoming more independent. Overall, there were more departures from Christaller's conditional order of entry principle at the end of this ten-year period than at the beginning. Seven functions in southern Minnesota from 1930 through 1970 showed departures from an order of entry scale that could be explained in terms of tributary areas which were larger than average for activities in places which lacked complementary activities, and smaller than average for activities absent from places which had a full complement of supporting activities.
|
| [21] |
Pattern classification [M]. |
| [22] |
Clustering algorithm selection by meta-learning systems: A new distance-based problem characterization and ranking combination methods [J].https://doi.org/10.1016/j.ins.2014.12.044 URL [本文引用: 1] |
| [23] |
ARMA-GRNN for passenger demand forecasting [ |
| [24] |
A Divide-and-Link algorithm for hierarchical clustering in networks [J].https://doi.org/10.1016/j.ins.2015.04.011 URL [本文引用: 3] 摘要
This paper introduces a hierarchical clustering algorithm in networks based upon a first divisive stage to break the graph and a second linking stage which is used to join nodes. As a particular case, this algorithm is applied to the specific problem of community detection in social networks, where a betweenness measure is considered for the divisive criterion and a similarity measure associated to data is used for the linking criterion. We show that this algorithm is very flexible as well as quite competitive (from both a performance and a computational complexity point of view) in relation with a set of state-of-the-art algorithms. Furthermore, the output given by the proposed algorithm allows to show in a dynamic and interpretable way the evolution of how the groups are split in the network.
|
| [25] |
Spatial clustering overview and comparison: Accuracy, sensitivity, and computational expense [J].https://doi.org/10.1080/00045608.2014.958389 URL [本文引用: 1] 摘要
Cluster analysis continues to be an important exploratory technique in scientific inquiry. It is used widely in geography, public health, criminology, ecology, and many other fields. Spatial cluster detection is driven by geographic information corresponding to the location of activities, requiring appropriate and meaningful treatment of space and spatial relationships combined with observed attributes of location and events. To date, this has meant utilizing dedicated measures and techniques to structure and account for distance, neighbors, contiguity, irregular geographic morphology, and so on. Unfortunately, all spatial clustering approaches, regardless of their theoretical underpinning, statistical foundation, or mathematical specification, have limitations in accuracy, sensitivity, and the computational effort required for identifying clusters. As a result, a major challenge in practice is determining which technique(s) will provide the most meaningful insights for a particular substantive issue or planning context. The purpose of this article is to provide an overview and evaluation of spatial clustering techniques, identifying the strengths and weaknesses of the most widely applied approaches. Results suggest that performance varies significantly in terms of accuracy, sensitivity, and computational expense. This is noteworthy because the misidentification of clusters, whether false positives or false negatives, has the potential to bias not only hypothesis formulation but also pragmatic facets of policy, process, and planning efforts within a region.
|
| [26] |
New spectral methods for ratio cut partitioning and clustering [J].https://doi.org/10.1109/43.159993 URL [本文引用: 1] 摘要
ABSTRACT Partitioning of circuit netlists in VLSI design is considered. It is shown that the second smallest eigenvalue of a matrix derived from the netlist gives a provably good approximation of the optimal ratio cut partition cost. It is also demonstrated that fast Lanczos-type methods for the sparse symmetric eigenvalue problem are a robust basis for computing heuristic ratio cuts based on the eigenvector of this second eigenvalue. Effective clustering methods are an immediate by-product of the second eigenvector computation and are very successful on the difficult input classes proposed in the CAD literature. The intersection graph representation of the circuit netlist is considered, as a basis for partitioning, a heuristic based on spectral ratio cut partitioning of the netlist intersection graph is proposed. The partitioning heuristics were tested on industry benchmark suites, and the results were good in terms of both solution quality and runtime. Several types of algorithmic speedups and directions for future work are discussed
|
| [27] |
The self-organizing map [J]. |
| [28] |
A SOM-based approach to estimating design hyetographs of ungauged sites [J].https://doi.org/10.1016/j.jhydrol.2007.03.016 URL [本文引用: 1] 摘要
Based on the self-organizing map (SOM), an approach is proposed to estimate design hyetographs at ungauged rainfall stations. The proposed approach contains two parts: a SOM-based clustering method and an assigning method. Firstly, the SOM-based clustering method is based to group the design hyetographs at gauged sites. Using the SOM-based clustering method, the relative topological relationships of the design hyetographs at the gauged sites can be established, and the number of clusters can be objectively decided by visual inspection. Furthermore, the assigning method is developed to assign an ungauged site to a specific cluster according to both the spatial information and the clustering results of gauged sites. After the ungauged site is assigned to the appropriate cluster, this cluster average design hyetograph is adopted as the estimated design hyetograph for the ungauged site. The proposed approach is applied to estimate the design hyetographs of ungauged sites in northern Taiwan. The results show that the approach performs better than methods based on conventional clustering techniques.
|
| [29] |
|
| [30] |
Two centrality models [J].https://doi.org/10.1353/pcg.1970.0006 URL [本文引用: 1] |
| [31] |
Cluster analysis for drilling-quality based on the modified algorithm of InDBSCAN [J].https://doi.org/10.4028/www.scientific.net/KEM.480-481.877 URL [本文引用: 1] 摘要
To detect the quality of batch drilling quickly070402a new approach based on Acoustic Emission signals is presented. The signals090005 statistical characteristics are extracted from acoustic emission signals in Time-domain, and then the signals090005 eigenvectors are constructed to reflect each drilling process. A modified incremental clustering algorithm InDBSCAN is used to cluster these eigenvectors070402and the batch drilling-quality can be analysed indirectly. Calculation and analysis results show that: the conclusion of incremental cluster analysis is more reasonable by the modified incremental clustering method of InDBSCAN. The detection accuracy of the batch drilling-quality is up to 84.3% according to the manual quality inspection.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}