董南 , 杨小唤, 蔡红艳
, 杨小唤, 蔡红艳
DONG Nan, YANG Xiaohuan, CAI Hongyan
通讯作者:
版权声明: 2016 地理科学进展 《地理科学进展》杂志 版权所有
基金资助:
作者简介:
作者简介:董南(1984-),男,河北唐山人,博士研究生,主要从事人口地理、遥感与GIS应用研究,E-mail:dongnan67@126.com。
展开
摘要
精细尺度的人口分布是当前人口地理学研究的热点和难点,在灾害评估、资源配置、智慧城市建设等方面应用广泛。居住建筑物尺度作为精细尺度的重要内容,其人口数据空间化日益引起学术界的关注。本文以居住建筑斑块面积、斑块内建筑面积比重、建筑物层数、公摊率等居住空间属性为人口分布数量的指示因子,以居住建筑的轮廓斑块为人口分布位置的指示因子,利用街道界线和街道常住人口数据为控制单元,建立线性模型,获得了2015年宣城市宣州区6个街道的居住建筑物尺度的人口分布矢量数据,刻画了城市市区人口空间分布的细节信息。结果表明:①以居住空间属性作为人口空间分布的指示因子,获取的人口空间数据精度高,结果可信。29个社区(村)估算人数的相对误差绝对值的平均值低于7%,其中25个社区(村)的相对误差绝对值低于10%。在1102个居住建筑斑块中,估算人数在合理区内的斑块个数占比高于74%,轻微低估区(-10%, 0)和轻微高估区(0, 10%)的斑块总数占比高于9%;②由斑块面积和建筑物层数共同表征的建筑物体积,是建筑物尺度上影响人口空间分布的关键因素;斑块内建筑面积比重属性能进一步提高模型精度;公摊率属性具有“降高升低”作用,但将估算人数调节到合理区的“能力”较弱。
关键词:
Abstract
Fine spatial scale population distribution has increasingly become a research hotspot yet a difficult question in the field of population geography. It has practical values in application and scientific significance for relevant research, such as disaster risk and impact assessment, resource allocation, and construction of smart cities. Residential building scale is considered an important part of fine spatial scales for population distribution. Research on the spatialization of population data at this scale has increasingly attracted academic attention. In this study, a population distribution vector data set at the residential building scale was established for six residential committees in Xuanzhou District, Anhui Province in 2015 based on residential space attribute data. Data used in the study include residential building patch area, percentage of housing area within residential building patches, building floor number, and public area rate. The method takes residential space attributes as variables for spatializing population data and treats residential building patches as population distribution location in geographical space with town boundary and town-level demographic data as controls. The spatialization method used in this study reveals detailed information about population distribution in urban areas. The results show that: (1) The population distribution data, obtained by using residential space attributes, are proved to be of high accuracy and reliability. The mean absolute relative error for 29 communities (villages) is less than 7%. The absolute relative error of 25 out of 29 communities (villages) is less than 10%. The proportion of patches whose estimated number of people is in reasonable range is higher than 74% in a total of 1102 residential building patches. The proportion of patches whose relative error is in slightly underestimated area (-10%, 0) and overestimated area (0, 10%) is higher than 9%. (2) Building volume , defined by residential building patch area and building floor number, is a key factor to estimate accurately the number of people within a residential building. The percentage of housing area can further improve model accuracy. Public area rate plays an important role to increase estimated number of people in underestimated area and decrease that in overestimated area, but is too weak to adjust the estimated number of people to reasonable range. In conclusion, spatialization based on residential space attributes can be an important method for population spatialization research at the residential building scale.
Keywords:
人口的空间分布是指一定的时间点,人口在地域上的分布状况,是人口过程在空间上的表现形式,是人口地理学研究的核心问题(胡焕庸, 1983)。人口数据空间化是获取人口空间分布数据的有效途径,在精确刻画人口分布、多源数据融合研究等方面具有重要科学意义(符海月等, 2006; 林丽洁等, 2010; 柏中强等, 2013)。精细尺度的人口空间数据在灾害评估、资源配置、智慧城市建设等方面应用广泛。建筑物尺度是精细尺度的重要方面,该尺度上人口空间数据的获取,正引起学术界的重视(卓莉等, 2014; Jia et al, 2016)。目前,建筑物尺度上人口数据空间化研究较少,成果精度有待提高,因此值得进行深入研究。
经过近30年的发展,人口数据空间化研究水平逐渐成熟。常用的空间化方法包括分区密度方法(Mennis, 2003; Gallego, 2010; Dmowska et al, 2014)、多元回归方法(卓莉等, 2005; 杨小唤等, 2006; 王磊等, 2011; 柏中强等, 2015)、多因素融合方法(廖顺宝等, 2003; Bhaduri et al, 2007; Zhang et al, 2015)、随机森林方法(Stevens et al, 2015; Gaughan et al, 2016)等。但是,其人口空间化数据成果大多以栅格呈现,格网大小多为20~1000 m,这种方式不可避免地会面临尺度效应带来的格网尺度适宜性问题(杜国明, 张树文, 张有全, 2007; 叶靖等, 2010; 王培震等, 2012; 李月娇等, 2014)。本文以矢量形式呈现人口空间数据,可以有效避免格网尺度适宜性研究问题。
以摄影测量与遥感为代表的现代测绘技术,为获取高分影像、大比例尺正射影像、地表三维立体提供技术支持,进而获取的大比例尺房屋矢量数据(谷国梁等, 2016)包括建筑物类型、轮廓、体积、层高(Lwin et al, 2009; Ural et al, 2011; Lung et al, 2013)等精细地理数据,其应用能将人口空间数据的分辨率提高到10 m级或建筑物尺度。因此,本文选取居住建筑斑块面积、斑块内建筑面积比重、建筑物层数、公摊率等居住空间属性作为人口分布数量的指示因子,以居住建筑斑块作为人口分布位置的指示因子,以街道界线、街道常住人口作为控制单元,建立线性回归模型。以安徽省宣城市宣州区6个街道为研究区,提出基于居住空间属性的人口数据空间化方案,探讨不同居住空间属性组合对模型精度的影响,获得了研究区2015年居住建筑尺度上人口分布矢量数据,以期丰富精细尺度人口空间化方法及数据成果。
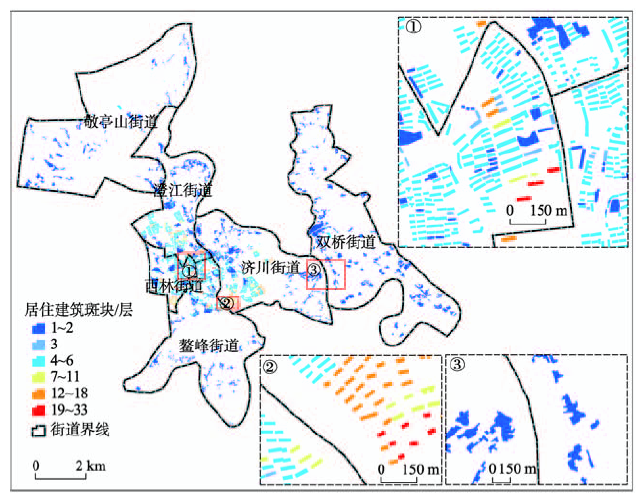
研究区宣城市宣州区位于安徽省东南部,包括双桥、鳌峰、西林、澄江、济川、敬亭山6个街道,含29个社区(村),总面积约90 km2,东西跨度约10 km,南北跨度约16 km(图1)。截至2015年,研究区常住人口超过23万人,是宣州区乃至宣城市的人口集中区域。研究区内居住建筑以多层楼房(4~6层)为主,多分布在市区中部;其次以平房居多,多分布在敬亭山街道、双桥街道、澄江街道北部、济川街道东部、鳌峰街道南部(图2)。
图2 居住建筑斑块空间分布图
Fig.2 Spatial distribution of residential building patches in Xuanzhou District, Anhui Province
通过对各街道办事处进行实地调研,获取各街道、社区(村)2015年的常住人口数据;从宣州区民政局获取各街道、社区(村)的行政界线图片资料,并以Quick Bird遥感影像为底图,进行矢量化生成行政界线矢量数据。
居住建筑是供人们生活起居用的建筑物,包括普通住宅、公寓、别墅、宿舍等。居住建筑斑块,是指对遥感影像进行目视解译,通过矢量化方法提取居住建筑物的轮廓多边形。本文选用Quick Bird遥感影像(拍摄时间为2015年7月),根据居住建筑在遥感影像上反映的颜色、形状、相关布局、地域分布等,并参考其他学者关于不同类型住宅用地的解译标志(杜国明, 张树文, 2007; 陈振拓等, 2012),建立居住建筑斑块解译标志(表1)。在此解译标志基础上,借助百度街景地图、搜狗建筑物三维景观图等辅助数据,对遥感影像进行目视解译,去除公共建筑、工业建筑及农业建筑,提取居住建筑的外轮廓图斑。此种做法可最大限度地消除非居住建筑用地对人口空间分布的影响。
表1 居住建筑斑块解译标志
Tab.1 Interpretation keys for residential building patches
| 类型 | 解译标志描述 | |||
|---|---|---|---|---|
| 颜色 | 形状 | 相关布局 | 地域分布 | |
| 1~2层居住建筑 | 屋顶以暗红、灰色为主;阴影不明显 | 房屋朝向不一致;房屋大小不一,几何形状规则 | 房屋排列无序,房屋间距不等,周围为绿色植被、耕地等 | 城乡结合处,城中村 |
| 3层及以上居住建筑 | 屋顶以暗红、暗灰、灰白色为主;阴影显著,并随楼房的变高而变长 | 方向特征显著,并且一致;几何形状规则且明显 | 房屋排列有序,与其他居住建筑呈近似等间距关系,周围绿化带及道路明显 | 城市市区 |
2.3.1 提取规则
(1) 1~2层居住建筑,以住宅用地斑块为最小提取单元。在该斑块内,以居住建筑物为主要部分,同时含有满足生活需求的附属设施用地,如建筑物之间的植被、绿化带、空地、道路等区域(如果相邻建筑物间的最大间距大于15 m,则分别生成不同斑块,旨在降低斑块内附属设施用地比重过大引起的影响)。
该类居住建筑多位于城中村、乡村地区,乡村的居住建筑遵循“一户一宅”的原则,即便是盖的2层小楼,依旧是一户人家;同时,乡村的居住建筑具有排列无序、大小不一及人口密度低等特点,因此,将居住建筑与附属设施用地作为整体,来提取住宅用地斑块,用该斑块而非单个的居住建筑斑块作为提取单元是适宜的。
(2) 3层及以上居住建筑,以单个居住建筑物(单栋居民楼)为最小提取单元。楼房是研究区内居住建筑的主体,更是人口集中区的载体。在人口集中区,以单个居住建筑物作为最小提取单元,能有效地避免居住建筑之外的用地对人口分布的影响。
2.3.2 斑块提取及居住空间属性信息获取
依据以上原则,共提取2862个居住建筑斑块(图2),其中4~6层居住建筑斑块比重最大,为58.0%;1~2层居住建筑斑块比重次之,为30.1%。
斑块的居住空间属性包括:
(1) 斑块面积(Area)
斑块面积(Area)是衡量居住空间大小的关键因素之一,依据GIS的Calculate Geometry工具自动计算Krasovsky 1940 Albers投影坐标系统下的各居住建筑斑块面积。
(2) 斑块内建筑面积比重(PHA)
斑块内建筑面积比重(PHA)即斑块内居住建筑物投影面积之和与该斑块总面积的比例。对1~2层居住建筑斑块,设置此空间属性,能够避免生活附属设施用地面积对人口分布数量的影响。PHA的确定:1~2层斑块,该属性值等于斑块内居住建筑的面积量测值/斑块总面积,计算结果精确到0.05;3层及以上层数斑块,该属性值都为1。
(3) 斑块内建筑物层数(BFN)
城市建设为了集约利用土地资源以及解决大量人口的居住问题,多层及高层居住建筑的比重很大,因此层数属性必不可少。BFN的确定:1~2层斑块,依据居住建筑在遥感影像上的地物特征,能够准确获取层数;3层及以上层数斑块,依据“宣城房产网”提供的楼房层数信息、百度街景地图及搜狗的建筑物三维景观图,获取层数属性。
(4) 公摊率(k)
公摊率(k)为公摊面积与建筑面积的比值。对于楼房建筑来说,公摊率也是影响居住空间的因素。目前,国家对公摊率没有明确规定数值范围,依据房地产行业关于公摊率或公摊系数的参考值范围(有哈相伴, 2009; 王立新, 2014; 胡长菊, 2015),以相对平均水平标准确定方案k1;通常情况下,高层住宅因有电梯、消防、设备管线等公共设施,公摊面积相对较大,而多层住宅因无电梯等公共设施,公摊面积相对较小(王立新, 2014; 胡长菊, 2015),因此将7层以上住宅的公摊率在平均水平的基础上上浮,将6层以下住宅的公摊率在平均水平的基础上下浮,确定方案k2(表2)。
表2 居住建筑物公摊率方案
Tab.2 Public area rate for residential buildings
| 公摊率(k) | 层数 | |||
|---|---|---|---|---|
| 1~3 | 4~6 | 7~18 | 19~ | |
| 方案k1 | 0.0 | 0.10 | 0.15 | 0.20 |
| 方案k2 | 0.0 | 0.08 | 0.18 | 0.22 |
(5) 居住建筑房屋套数、建筑面积属性
套数、建筑面积数据主要用于模型结果精度的验证。数据来源于“宣城房产网”提供的楼房房屋套数、建筑面积等信息;此外,利用搜狗的建筑物三维景观图对套数信息进行补充。
本文以午夜时刻为时间节点,研究常住人口在住宅用地上的静态空间分布,侧重揭示人口在住宅用地内部的分布差异。
本文以居住建筑斑块面积(Area)、斑块内建筑面积比重(PHA)、斑块内建筑物层数(BFN)、公摊率(k)来描述居住空间,建立常住人口与居住建筑的空间属性的关系,实现建筑物尺度上人口数据空间化。
依据基于土地利用数据的人口数据空间化模型(江东等, 2002; 杨小唤等, 2002)可知,人口数量与各土地利用类型面积存在线性关系。其中住宅用地是指用于人们生活居住的房基地及其附属设施的土地,是土地利用类型中最直接反映人口分布的因子(刘焕金, 2012)。其他土地利用类型,如耕地、园地、林地、草地等,虽会存在一定的人口,但主要是少量的、临时性的人口,在规模和存在时间上都无法与住宅用地相比。因此,鉴于住宅用地的突出及独特地位,在进行人口数据空间化时,侧重研究人口在住宅用地内部的分布差异,认为其他土地利用类型均无人口分布,即将人口展布在居住建筑上。
首先,构建人口数量与居住建筑斑块面积的线性回归模型,数学表达式见表3中的类型1。其次,对于1~2层居住建筑斑块,斑块内建筑面积比重(PHA)会直接影响该斑块内人口数量,引入PHA消除斑块内生活附属设施用地面积对人口数量的影响。另外,居住空间是一个三维问题,引入斑块内建筑物层数(BFN)能更好地体现居住空间的大小。同时,为探讨PHA和BFN对人口空间分布的综合影响,引入这2个属性信息建立模型。数学表达式见表3中的类型2、类型3和类型4。对于楼房建筑来说,公摊率也是居住空间的固有属性。研究区内,层数大于4层的楼房,其建筑面积占总研究区建筑面积的72.6%,故引入公摊率(k),探讨其对人口空间分布的影响。数学表达式见表3中的类型5和类型6。
表3 基于居住空间属性的人口数据空间化模型
Tab.3 Models for demographic data spatialization based on residential space attributes
| 模型名称 | 回归模型 |
|---|---|
| 类型1 | |
| 类型2 | |
| 类型3 | |
| 类型4 | |
| 类型5 | |
| 类型6 |
分别汇总每个社区(村)的所有斑块的6个参数值:
通过比较发现(表4),类型1和类型2的决定系数较低,估计值误差的标准差较高,表明采用Area、PHA不能准确推算人数。引入BFN属性的类型3,决定系数达到0.914,与类型2相比,提高幅度很大,估计值误差标准差下降很多,表明由Area和BFN共同表征的建筑物体积是准确估算人数的关键因素,这与建筑物体积是精细尺度人口分布模拟的最优因子的结论(Dong et al, 2010; Silván-Cárdenas et al, 2010; 卓莉等, 2014)一致。与类型3相比,类型4的决定系数虽然只提高了0.06,但是估计值误差标准差下降了40.5%,同时类型4各项拟合度参数也是6个类型中的最优值,表明在Area、BFN属性的基础上,引入PHA能更好地估算斑块人数。与类型4相比,类型5和类型6的决定系数有所降低,估计值误差标准差有所升高,但幅度不大。结合实际情况,公摊率也可能具有一定的使用价值,选取类型4、类型5和类型6进行下一步讨论。
表4 回归模型拟合度参数对比
Tab.4 Comparison of fitting parameters of regression models
| 模型名称 | 相关系数 | 决定系数 | 校正决定系数 | 估计值误差标准差 |
|---|---|---|---|---|
| 类型1 | 0.173 | 0.030 | -0.006 | 8097.17 |
| 类型2 | 0.438 | 0.192 | 0.162 | 7388.19 |
| 类型3 | 0.956 | 0.914 | 0.911 | 2405.26 |
| 类型4 | 0.985 | 0.970 | 0.969 | 1430.66 |
| 类型5 | 0.982 | 0.965 | 0.963 | 1548.80 |
| 类型6 | 0.983 | 0.965 | 0.964 | 1530.76 |
在3.2小节中,人口数量与居住空间属性之间的关系仅被假设为线性关系,这种假设是否恰当,能否确保所使用的回归模型具有统计学意义,必须通过对模型的假设检验来说明。依据方差分析显示的假设检验结果可知(表5),显著性水平均小于0.05,说明类型4、类型5和类型6均具有统计学意义,能用于表达人口数量与相关居住空间属性变量之间的线性关系。
表5 类型4、类型5与类型6的显著性检验分析表
Tab.5 Significance test of type 4, type 5, and type 6 models
| 模型名称 | 变差来源 | 平方和 | 自由度 | 均方 | F统计量 | 显著性水平(Sig.) |
|---|---|---|---|---|---|---|
| 类型4 | 回归 | 1.769E+09 | 1 | 1.769E+09 | 864.431 | 0.000 |
| 残差 | 55263490 | 27 | 2046795.9 | — | — | |
| 总离差 | 1.825E+09 | 28 | — | |||
| 类型5 | 回归 | 1.760E+09 | 1 | 1.760E+09 | 733.626 | 0.000 |
| 残差 | 64767166 | 27 | 2398783.9 | — | — | |
| 总离差 | 1.825E+09 | 28 | — | |||
| 类型6 | 回归 | 1.761E+09 | 1 | 1.761E+09 | 751.662 | 0.000 |
| 残差 | 63266949 | 27 | 2343220.3 | — | — | |
| 总离差 | 1.825E+09 | 28 | — |
分乡镇控制是获取精细尺度人口空间数据的前提条件之一。胡焕庸先生(1936)在“句容县之人口分布”中阐述:“制作精密之人口地图,必须备有各县分乡人口统计,及分乡区划地图。”可见乡镇(街道)级别的人口统计数据和行政区划图是绘制高精度人口密度图的2个必要条件。
本文以街道为建模控制单元,旨在减少模型空间尺度转换的跨度,保证精细尺度人口数据空间化的精度。同一街道内,人均居住空间相似,即街道内各个居住建筑斑块的人均居住空间系数a相同,同时根据“无土地则无人口”的原则,即无居住建筑则无人口,常数项b=0。从而确定类型4、类型5、类型6的公式:
类型4:
类型5:
类型6:
式中:
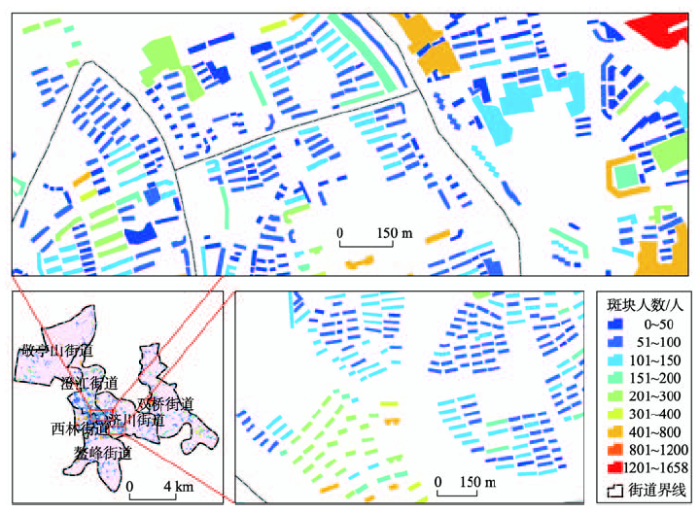
图3为依据类型4获取的宣州区6个街道的人口空间分布矢量数据。该数据展示了居住建筑物尺度上的人口数量,刻画了城市市区人口空间分布的细节信息。即人口主要集中分布在市区中部,敬亭山街道、双桥街道北部及鳌峰街道南部的人口分布较少。
图3 2015年宣州区6街道居住建筑尺度人口空间分布图
Fig.3 Population distribution at the residential building scale for six residential committees in Xuanzhou District in 2015
精度验证拟从2个方面进行:一是社区(村)尺度验证。以街道尺度进行人口数据空间化,对其结果进行精度验证,最具有说服力的方法就是用低一级行政区套合人口空间数据,同对应行政区的人口统计数据进行比较,本文用相对误差及误差范围内社区(村)个数指标进行精度评价;二是居住建筑尺度验证。用居住建筑斑块的估算人数,同该斑块内人数参考真值进行比较,该方案更能从精细尺度上体现人口数据空间化模型的精度。人数参考真值等于每套房屋的平均人数乘以斑块内房屋套数。
(1) 社区(村)尺度验证
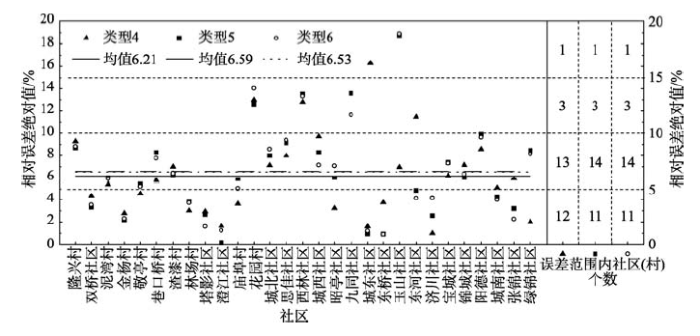
对人口空间化结果进行基于29个社区的相对误差统计分析(图4)。结果显示:类型4、类型5和类型6的相对误差绝对值的平均值低于7%,25个社区(村)的相对误差绝对值低于10%。表明类型4、类型5和类型6的精度较高,类型4具有微弱的精度优势。
图4 社区(村)尺度的估算人数相对误差统计图
Fig.4 Relative error statistics of estimated number of people at the communities (villages) scale
(2) 居住建筑尺度验证
从2862个居住建筑斑块中,随机选取分布在29个社区的1102个居住建筑斑块,对估算人数进行验证。本文以每套房屋平均居住2~3人,确定每个斑块应该居住的人数,作为人数参考真值。人数低估区,以每套房屋2人乘以套数作为人数下限参考真值;人数高估区,以每套房屋3人乘以套数作为人数上限参考真值。依据式(2)对类型4、类型5和类型6估算的人数与参考真值进行对比分析。
式中:
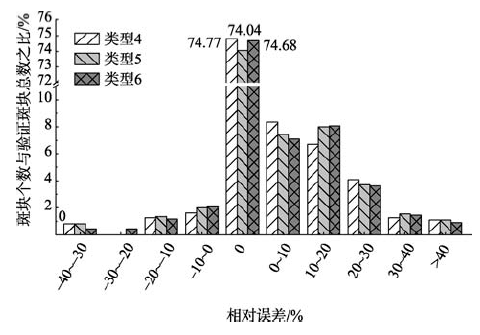
从图5可以看出:类型4、类型5和类型6的居住建筑斑块估算人数在合理区内的斑块个数分别为824、816、823,所占比例分别高达74.77%、74.04%、74.68%;轻微低估区(-10%, 0)和轻微高估区(0, 10%)的斑块个数比例之和分别为9.98%、9.43%、9.16%;其他误差区间内的斑块个数占比很低,并呈现随着误差变大斑块个数减少的趋势。表明类型4、类型5和类型6的精度较高,类型4具有微弱的精度优势。
图5 居住建筑尺度的估算人数相对误差统计图
Fig.5 Relative error statistics of estimated number of people at the residential building scale
不考虑由模型产生的随机误差,分析造成人数估算误差的原因,发现估算误差主要来源于以下4个方面:一是由模型求得的人均居住面积偏大(偏小)引起的误差;二是居住建筑矢量化误差引起的误差;三是由斑块内建筑面积比重偏高(偏低)引起的误差;四是由以上3个因素两两或综合作用引起的误差。
4.2.1 总体分析
鉴于类型4、类型5和类型6的精度相似,以类型4结果为例进行误差分析。从高估区和低估区的278个斑块中,随机抽取100个居住建筑斑块,对其人均居住面积的参考真值(建筑面积/人数参考真值)与计算值、建筑面积的真实值与计算值进行对比分析(表6)。
表6 人均居住面积、建筑面积数值对比
Tab.6 Numerical comparison of per capita living space and building area
| 类别 | 计算值减真实值 | 斑块个数比重/% | 相对误差平均值/% | 描述 |
|---|---|---|---|---|
| 人均居住面积 | <0 | 25.9 | -5.8 | 人均居住面积计算值偏小 |
| >0 | 74.1 | 15.5 | 人均居住面积计算值偏大 | |
| 建筑面积 | <0 | 22.2 | -8.2 | 矢量化提取的建筑面积偏小 |
| >0 | 77.8 | 13.1 | 矢量化提取的建筑面积偏大 |
表6表明,人均居住面积计算值偏大、矢量化提取的建筑面积偏大的斑块个数占所有斑块的3/4左右,并且各自的相对误差平均值较高,这2类原因会导致人数高估;人数低估的斑块个数相对较少,占1/4左右。图5表明整个研究区内大部分斑块的人数估算偏高,只有少数斑块的人数估算偏低,这与表6的数据分析结果一致。
表8 合理区内斑块个数比重信息汇总
Tab.8 Summary of the proportion of patches in reasonable range
| 层数/层 | 合理区内斑块个数比重/% | ||
|---|---|---|---|
| 类型4 | 类型5 | 类型6 | |
| 1~3 | 18.9 | 16.9 | 16.9 |
| 4~6 | 49.5 | 49.3 | 49.4 |
| 7~18 | 6.3 | 6.8 | 7.3 |
| 19~33 | 0.2 | 1.1 | 1.2 |
4.2.2 分项原因说明
(1) 人均居住面积计算值引起的误差
以图6①中A栋楼为例。由式(1)可得其人均居住面积为32.4 m2/人,较参考真值(37.7 m2/人)偏小5.3 m2/人,导致人数高估19.7人。矢量化提取的居住建筑斑块,其建筑面积为4405.4 m2,较真实值(4522.2 m2)偏小116.8 m2,导致人数低估3.6人。综上,人均居住面积偏小和矢量化错误共同作用导致人数高估16人,人均居住面积偏小是主因。人均居住面积计算值偏大则会导致人数低估(图6⑤中E栋楼)。
图6 估算人数相对误差空间分布图①①
Fig.6 Spatial distribution of relative error of estimated number of people
(2) 居住建筑矢量化误差引起的误差
以图6②中B栋楼为例。矢量化提取的居住建筑斑块,其建筑面积为1716.1 m2,较真实值(1500.1 m2)大216 m2,导致人数高估5人。由式(1)可得其人均居住面积为41.7 m2/人,与参考真值(41.7 m2/人)相同,可知人均居住面积没有引起误差。即矢量化误差是主因,导致人数高估5人。矢量化提取的建筑面积偏小,则会导致人数低估(图6⑤中F栋楼)。
(3) 斑块内建筑面积比重偏高引起的误差
以图6③中C斑块为例。矢量化提取的居住建筑斑块,其斑块面积为8383.7 m2,因斑块内建筑面积比重赋值为0.55,所以斑块内居住建筑面积为4611 m2,较真实值(2978.5 m2)偏大1632.5 m2,导致人数高估。
(4) 人均居住面积计算值偏大与矢量化误差共同作用引起的误差
以图6④中D栋楼为例。由式(1)可得其人均居住面积为33.9 m2/人,较参考真值(31.2 m2/人)偏大2.7 m2/人,导致人数低估21.6人。矢量化提取的居住建筑斑块,其建筑面积为9685.0 m2,较真实值(8421.3 m2)增加1263.7 m2,导致人数高估37.2人。综上,人均居住面积偏大和矢量化误差共同作用导致人数高估16人。两者共同作用也会导致人数低估(图6⑥中G栋楼)。
4.2.3 类型对比分析
图4-5表明,类型4、类型5、类型6的精度均较高,类型4具有微弱的精度优势。与类型4相比,类型5、6引入了公摊率,该属性对估算人数具有“降高升低”的调节作用,但是调节到合理区的“能力”较弱。
表7展示了类型5、类型6与类型4估算人数差值信息。对于1~3层斑块,类型5、类型6的估算人数比类型4偏高的斑块个数比重分别为18.7%、18.1%,平均高出6.8、6.5人,表明公摊率属性具有“升低”作用,如图6③中C斑块所示;对于4~6层斑块,估算人数彼此差别不大,如图6②中B斑块所示;对于7~18层斑块,类型5、类型6的估算人数比类型4偏低的斑块个数比重分别为11.6%、11.6%,平均降低13.1、21.9人;对于19~33层,这一差距更大,表明公摊率属性具有“降高”作用,可以适当避免高层居住建筑估算人数过于偏高,如图6④中D斑块所示。
表7 类型5、类型6与类型4估算人数差值信息汇总
Tab.7 Summary of the differences of estimated number of people between type 5, type 6, and type 4 models
| 层数/层 | 类型5与类型4 | 类型6与类型4 | ||||
|---|---|---|---|---|---|---|
| 估算人数之差 | 人数之差平均值 | 斑块个数比重/% | 估算人数之差 | 人数之差平均值 | 斑块个数比重/% | |
| 1~3 | >0 | 6.8 | 18.7 | >0 | 6.5 | 18.1 |
| =0 | 0.0 | 6.4 | =0 | 0.0 | 7.2 | |
| <0 | -1.0 | 0.1 | <0 | — | 0.0 | |
| 4~6 | >0 | 1.1 | 8.2 | >0 | 1.8 | 40.9 |
| =0 | 0.0 | 32.3 | =0 | 0.0 | 20.5 | |
| <0 | -1.1 | 21.2 | <0 | -1.0 | 0.3 | |
| 7~18 | >0 | — | 0.0 | >0 | — | 0.0 |
| =0 | — | 0.0 | =0 | — | 0.0 | |
| <0 | -13.1 | 11.6 | <0 | -21.9 | 11.6 | |
| 19~33 | >0 | — | 0.0 | >0 | — | 0.0 |
| =0 | — | 0.0 | =0 | — | 0.0 | |
| <0 | -44.1 | 1.5 | <0 | -54.0 | 1.5 | |
表8汇总了各类型估算人数在合理区内的斑块个数比重。对于1~3层斑块,与类型4相比,类型5、类型6反而将估算人数“调出”合理区,合理区内斑块个数比重分别降低2.0%;对于7~18层斑块,与类型4相比,类型5、类型6将估算人数“调入”合理区的斑块个数比重分别为0.5%、1.0%;对于19~33层斑块,类型5、类型6将估算人数“调入”合理区的斑块个数比重分别为0.9%、1.0%。综合来看,公摊率属性的“降高升低”作用,并没有提高合理区内斑块个数比重,即调节到合理区的“能力”较弱,这也是公摊率属性不能提高模型整体估算精度的原因。然而作为居住空间属性之一的公摊率,在避免高层居住建筑估算人数过于偏高等方面具有应用潜力,值得深入探讨。
表8 合理区内斑块个数比重信息汇总
Tab.8 Summary of the proportion of patches in reasonable range
| 层数/层 | 合理区内斑块个数比重/% | ||
|---|---|---|---|
| 类型4 | 类型5 | 类型6 | |
| 1~3 | 18.9 | 16.9 | 16.9 |
| 4~6 | 49.5 | 49.3 | 49.4 |
| 7~18 | 6.3 | 6.8 | 7.3 |
| 19~33 | 0.2 | 1.1 | 1.2 |
本文选用Quick Bird遥感影像,依据解译标志,参照百度街景地图、搜狗三维地图,提取居住建筑的轮廓斑块。以街道为人口数据空间化转换尺度,基于居住空间属性,建立线性回归模型,将常住人口展布在居住建筑斑块上,获取了2015年宣州区居住建筑物尺度上的人口分布矢量数据。主要结论如下:
(1) 提出了一种以居住建筑斑块面积、斑块内建筑面积比重、建筑物层数、公摊率等居住空间属性来实现城区建筑物尺度人口空间化的方案。精度分析表明,利用该方案生成的人口空间数据精度较高,结果可信。29个社区(村)相对误差绝对值的平均值低于7%;在1102个居住建筑斑块中,估算人数在合理区内的斑块个数占比高于74%,轻微低估区(-10%, 0)和轻微高估区(0, 10%)的斑块总数占比高于9%。
(2) 由斑块面积和建筑物层数共同表征的建筑物体积,是建筑物尺度上影响人口空间分布的关键因素。在此基础上,引入斑块内建筑面积比重属性,能提高模型估算精度。作为居住空间属性之一的公摊率,具有“降高升低”的作用,但将估算人数调节到合理区的“能力”较弱,尽管如此,其应用潜力值得深入探讨。
本文的不足之处是,在建模时假定同一街道内各个居住建筑斑块的人均居住空间相同,导致模型求得的人均居住面积有偏差,进而影响模型精度。在后续的研究中,将重点细分同一街道内居住建筑类别,揭示不同类型建筑的人均居住面积的异同,以期进一步提高模型精度。精细尺度上,城市公共设施要素数据(何莲娜, 2011; 康停军等, 2012)、带有地理位置的tweets数据(Patel et al, 2016)等也是城市人口空间分布的指示因素,下一步将引入此类地理信息数据,以期提高城区建筑物尺度人口数据空间化精度。
The authors have declared that no competing interests exist.
| [1] |
基于多源信息的人口分布格网化方法研究 [J].https://doi.org/10.3724/SP.J.1047.2015.00653 Magsci [本文引用: 1] 摘要
<p>格网化人口分布数据比行政单元人口密度数据更易直观表达人口的真实分布状况。本文面向人口格网化管理的区域发展需求, 以延安市为研究对象, 基于增强居民地空间分布及其内部结构信息的理念, 利用乡镇界线和乡镇级人口统计数据为输入控制单元, 以土地利用数据、居民点信息、DEM、夜晚灯光数据等多源信息为指示因子, 采用多元回归建模方法获得了延安市2010年100 m格网人口分布数据。结果表明, 本文采用的人口格网化建模方法最终模型选用变量数少, 决定系数(<em>R</em><sup>2</sup>)达到0.872。最终模型在用于验证的24个乡镇中, 有18个乡镇的估计人口数与统计值误差绝对值小于10%。分析认为, 该建模策略结果可信, 多源的人口分布指示信息在人口格网化方法上明显优于单独的土地利用数据方法。本文获得的100 m格网延安市人口数据格网化结果, 显著增强了人口空间分布的细节信息, 对于县市一级的人口数据格网化具有借鉴意义。</p>
The gridding approach to redistribute population based on multi-source data [J].https://doi.org/10.3724/SP.J.1047.2015.00653 Magsci [本文引用: 1] 摘要
<p>格网化人口分布数据比行政单元人口密度数据更易直观表达人口的真实分布状况。本文面向人口格网化管理的区域发展需求, 以延安市为研究对象, 基于增强居民地空间分布及其内部结构信息的理念, 利用乡镇界线和乡镇级人口统计数据为输入控制单元, 以土地利用数据、居民点信息、DEM、夜晚灯光数据等多源信息为指示因子, 采用多元回归建模方法获得了延安市2010年100 m格网人口分布数据。结果表明, 本文采用的人口格网化建模方法最终模型选用变量数少, 决定系数(<em>R</em><sup>2</sup>)达到0.872。最终模型在用于验证的24个乡镇中, 有18个乡镇的估计人口数与统计值误差绝对值小于10%。分析认为, 该建模策略结果可信, 多源的人口分布指示信息在人口格网化方法上明显优于单独的土地利用数据方法。本文获得的100 m格网延安市人口数据格网化结果, 显著增强了人口空间分布的细节信息, 对于县市一级的人口数据格网化具有借鉴意义。</p>
|
| [2] |
人口数据空间化研究综述 [J].https://doi.org/10.11820/dlkxjz.2013.11.012 URL Magsci [本文引用: 1] 摘要
人口数据空间化研究旨在发掘和展现人口统计数据中隐含的空间信息,并以地理格网或其他区域划分的形式再现客观世界的人口分布,具有重要的科学意义。人口空间分布数据有助于从不同地理尺度和地理维度对人口统计数据形成有益补充,其应用广泛,相关研究方兴未艾。主要从以下3 个方面对人口数据空间化研究进行综述:① 主要空间化方法的原理及其适用性;② 空间化中用到的建模参考因素,并结合具体应用案例分析其作用机理;③ 典型人口空间化数据集。在此基础上,分析了现阶段人口数据空间化所运用的输入数据的质量和详细程度、尺度效应及时空分辨率、长时间序列数据集和精度检验等方面存在的问题;并探讨了人口数据空间化未来的研究方向。
Research progress in spatialization of population data [J].https://doi.org/10.11820/dlkxjz.2013.11.012 URL Magsci [本文引用: 1] 摘要
人口数据空间化研究旨在发掘和展现人口统计数据中隐含的空间信息,并以地理格网或其他区域划分的形式再现客观世界的人口分布,具有重要的科学意义。人口空间分布数据有助于从不同地理尺度和地理维度对人口统计数据形成有益补充,其应用广泛,相关研究方兴未艾。主要从以下3 个方面对人口数据空间化研究进行综述:① 主要空间化方法的原理及其适用性;② 空间化中用到的建模参考因素,并结合具体应用案例分析其作用机理;③ 典型人口空间化数据集。在此基础上,分析了现阶段人口数据空间化所运用的输入数据的质量和详细程度、尺度效应及时空分辨率、长时间序列数据集和精度检验等方面存在的问题;并探讨了人口数据空间化未来的研究方向。
|
| [3] |
面向防震减灾的人口数据空间化研究: 以2007年宁洱地震灾区为例 [J].Study of spatial population distribution in earthquake disaster reduction: A case study of 2007 Ning'er earthquake [J]. |
| [4] |
面向防洪救灾的人口统计数据空间化研究: 以扶余县为例 [J].https://doi.org/10.3969/j.issn.1004-8227.2007.02.027 URL Magsci 摘要
<p>人口是重要的受灾体,准确的人口空间分布信息是防洪救灾工作的重要依据。将人口统计数据与遥感数据相结合,借助GIS手段来空间化人口统计数据,模拟人口空间分布。着力分析两个问题:①居民点类型、面积、位置的精确获取;②居民点类型、面积与人口数量间的关系。研究中,首先根据地理意义和数学意义,对经典的城市人口—面积异速生长模型进行扩展,推导出城乡人口—面积统一模型。进而以扶余县为例,以15万地形图为辅助数据,建立居民点分类体系,利用ETM影像提取居民点信息,在以上模型的基础上建立人口分布的反演模型,得到基于居民点的人口分布矢量数据。</p>
Spatial distribution in population statistics in relation to flood prevention and rescue: A case study in Fuyu County [J].https://doi.org/10.3969/j.issn.1004-8227.2007.02.027 URL Magsci 摘要
<p>人口是重要的受灾体,准确的人口空间分布信息是防洪救灾工作的重要依据。将人口统计数据与遥感数据相结合,借助GIS手段来空间化人口统计数据,模拟人口空间分布。着力分析两个问题:①居民点类型、面积、位置的精确获取;②居民点类型、面积与人口数量间的关系。研究中,首先根据地理意义和数学意义,对经典的城市人口—面积异速生长模型进行扩展,推导出城乡人口—面积统一模型。进而以扶余县为例,以15万地形图为辅助数据,建立居民点分类体系,利用ETM影像提取居民点信息,在以上模型的基础上建立人口分布的反演模型,得到基于居民点的人口分布矢量数据。</p>
|
| [5] |
城市人口密度的尺度效应分析: 以沈阳市为例 [J].https://doi.org/10.3969/j.issn.1002-1175.2007.02.008 URL [本文引用: 2] 摘要
以沈阳市为例,在对人口统计数据进行空间化处理的基础上,从统计 特征、空间自相关性和空间格局3个方面分析人口密度在10种粒度下的异同,充分证明了人口密度尺度效应的存在,并基于景观指数确定了沈阳市人口分布研究的 适宜尺度.本研究认为在使用人口密度这一指标来研究城市人口分布格局时,学者们必须面对尺度效应、选择适宜尺度,并充分考虑数据来源的尺度、分析的尺度、 结果表达的尺度以及它们之间的关系和转换.
Analyzing scale effects of population density with Shenyang City as a case [J].https://doi.org/10.3969/j.issn.1002-1175.2007.02.008 URL [本文引用: 2] 摘要
以沈阳市为例,在对人口统计数据进行空间化处理的基础上,从统计 特征、空间自相关性和空间格局3个方面分析人口密度在10种粒度下的异同,充分证明了人口密度尺度效应的存在,并基于景观指数确定了沈阳市人口分布研究的 适宜尺度.本研究认为在使用人口密度这一指标来研究城市人口分布格局时,学者们必须面对尺度效应、选择适宜尺度,并充分考虑数据来源的尺度、分析的尺度、 结果表达的尺度以及它们之间的关系和转换.
|
| [6] |
人口数据格网化模型研究进展综述 [J].https://doi.org/10.3969/j.issn.1003-2398.2006.03.025 URL [本文引用: 1] 摘要
人口数据格网化是目前人口空间分布研究的热点。本文对国内外人口数据格网化模型研究进行总结,重点剖析几种主要的人口数据格网化模型。研究表明:人口数据格网化模型从单纯的、静态的格网化方法,逐步向自然、经济社会因素综合影响下的空间模型过渡,朝着动态模型方向发展;随着格网化数据应用领域的不断拓展,以不同级别格网为基本统计单元的人口数据生产将是人口数据获取的一个重要发展趋势。
Summary of grid transformation models of population data [J].https://doi.org/10.3969/j.issn.1003-2398.2006.03.025 URL [本文引用: 1] 摘要
人口数据格网化是目前人口空间分布研究的热点。本文对国内外人口数据格网化模型研究进行总结,重点剖析几种主要的人口数据格网化模型。研究表明:人口数据格网化模型从单纯的、静态的格网化方法,逐步向自然、经济社会因素综合影响下的空间模型过渡,朝着动态模型方向发展;随着格网化数据应用领域的不断拓展,以不同级别格网为基本统计单元的人口数据生产将是人口数据获取的一个重要发展趋势。
|
| [7] |
天津市面向震害快速评估的房屋和人口空间化研究 [J].
以天津市的大比例尺房屋空间数 据和第六次人口普查数据为基础,利用GIS空间分析功能,模拟了天津市房屋和人口空间分布,产出1km格网的房屋数据和分时段人口公里格网数据。经检验, 模拟的房屋和人口数据达到了较高精度,能够较准确地表达行政单元内部的房屋和人口空间分布。将模拟结果应用到设定地震震害评估中,与基于平均密度法的评估 结果对比,表明基于公里格网评估的结果更为合理,减少了由于房屋和人口分布不均匀造成的误差,能够为地震应急工作提供可靠的数据支撑。
Spatialization of population and housing data in Tianjin oriented to rapid earthquake loss assessment [J].
以天津市的大比例尺房屋空间数 据和第六次人口普查数据为基础,利用GIS空间分析功能,模拟了天津市房屋和人口空间分布,产出1km格网的房屋数据和分时段人口公里格网数据。经检验, 模拟的房屋和人口数据达到了较高精度,能够较准确地表达行政单元内部的房屋和人口空间分布。将模拟结果应用到设定地震震害评估中,与基于平均密度法的评估 结果对比,表明基于公里格网评估的结果更为合理,减少了由于房屋和人口分布不均匀造成的误差,能够为地震应急工作提供可靠的数据支撑。
|
| [8] |
基于城市布局要素的人口数据空间化研究 [J].
人口信息只有通过基础地理空间信息这座桥梁实现空间分布化以后,才能与其他社会经济信息融合贯通,更准确地反演客观现实的过去、模拟现在和预测未来。本文通过建立包括建筑条件、交通条件、公共服务设施条件、就业条件、环境条件、限制条件等内容的城市空间布局要素因子库,并对各因子与人均住宅建筑面积的相关性进行分析,以其归一化相关系数作为定量分析的权重系数,最终实现北京市现状人口以居住用地为单元的空间分布,是研究人口空间单元分布规律和实现现状人口空间化分布的一种尝试。
A discussion of population spatial distribution based on urban layout parameter [J].
人口信息只有通过基础地理空间信息这座桥梁实现空间分布化以后,才能与其他社会经济信息融合贯通,更准确地反演客观现实的过去、模拟现在和预测未来。本文通过建立包括建筑条件、交通条件、公共服务设施条件、就业条件、环境条件、限制条件等内容的城市空间布局要素因子库,并对各因子与人均住宅建筑面积的相关性进行分析,以其归一化相关系数作为定量分析的权重系数,最终实现北京市现状人口以居住用地为单元的空间分布,是研究人口空间单元分布规律和实现现状人口空间化分布的一种尝试。
|
| [9] |
国家建设部规定高层住宅楼公摊系数是多少 [EB/OL].Guojia jianshebu guiding gaoceng zhuzhailou gongtan xishu shi duoshao [EB/OL]. |
| [10] |
句容县之人口分布 [J].https://doi.org/10.11821/xb193603008 URL 摘要
正新地理之趋势,颇注重人地关系之研究,人地关系之方面甚多,就中最基本而重要者,当莫过於人口之分布;一地人口之有无多寡,除极少数之例外,均视各该地自然生产力之强弱而定;一地自然生产力之强弱,固亦视人力经营之方式而有所不同,然此亦为人地之间彼此相互影响之结果;自然对於人生具有消极限制之条件,人生对於自然,亦有积极改造之功能,彼此相互作用,以构成
The distribution of population in Chuyung District [J].https://doi.org/10.11821/xb193603008 URL 摘要
正新地理之趋势,颇注重人地关系之研究,人地关系之方面甚多,就中最基本而重要者,当莫过於人口之分布;一地人口之有无多寡,除极少数之例外,均视各该地自然生产力之强弱而定;一地自然生产力之强弱,固亦视人力经营之方式而有所不同,然此亦为人地之间彼此相互影响之结果;自然对於人生具有消极限制之条件,人生对於自然,亦有积极改造之功能,彼此相互作用,以构成
|
| [11] |
|
| [12] |
基于RS、GIS的人口空间分布研究 [J].https://doi.org/10.3321/j.issn:1001-8166.2002.05.016 URL Magsci [本文引用: 1] 摘要
<p>人口的空间分布问题涉及人口学、经济学、地理学等多个学科,统计型人口数据的空间化是"数字地球"的重要研究内容。阐述了人口地域分布的基本理论,回顾了人口空间分布的研究进展,结合研究实践,提出了在遥感、GIS技术支持下,统计型人口数据空间化的研究思路和技术流程,并对该方法的特点和应用前景做了展望。</p>
Study on spatial distribution of population based on remote sensing and GIS [J].https://doi.org/10.3321/j.issn:1001-8166.2002.05.016 URL Magsci [本文引用: 1] 摘要
<p>人口的空间分布问题涉及人口学、经济学、地理学等多个学科,统计型人口数据的空间化是"数字地球"的重要研究内容。阐述了人口地域分布的基本理论,回顾了人口空间分布的研究进展,结合研究实践,提出了在遥感、GIS技术支持下,统计型人口数据空间化的研究思路和技术流程,并对该方法的特点和应用前景做了展望。</p>
|
| [13] |
基于多智能体的城市人口分布模型 [J].
人口是城市发展中最为活跃的因素,快速增长的人口给城市安全、经济和生态环境带来了深远的影响,获取不同尺度的高精度人口空间分布信息对于城市安全管理、提高资源环境的综合管理能力具有非常重要的意义。针对常用的城市人口空间分布模拟方法存在的不足,构建了基于多智能体的城市人口分布模型,模型由影响要素、智能体、决策规则等组成。在两个不同尺度区域进行了模型应用实验,并以重力模型进行了对比分析。实验结果表明,与重力模型相比,此模型所模拟的结果具有更高的精度,且接近于实际的人口空间分布,为城市人口分布模拟提供了新的思路。
Agent-based urban population distribution model [J].
人口是城市发展中最为活跃的因素,快速增长的人口给城市安全、经济和生态环境带来了深远的影响,获取不同尺度的高精度人口空间分布信息对于城市安全管理、提高资源环境的综合管理能力具有非常重要的意义。针对常用的城市人口空间分布模拟方法存在的不足,构建了基于多智能体的城市人口分布模型,模型由影响要素、智能体、决策规则等组成。在两个不同尺度区域进行了模型应用实验,并以重力模型进行了对比分析。实验结果表明,与重力模型相比,此模型所模拟的结果具有更高的精度,且接近于实际的人口空间分布,为城市人口分布模拟提供了新的思路。
|
| [14] |
基于景观生态学的人口空间数据适宜格网尺度研究: 以山东省为例 [J].https://doi.org/10.7702/dlydlxxkx20140120 URL [本文引用: 1] 摘要
以山东省为研究区,在100m、200m、300m、400m、500m、600m、700m、800m、900m、1km 10个格网尺度人口格网数据的基础上,引入景观生态学的相关指数和方法,探索不同格网尺度表达人口空间分布的适宜性。结果表明:在用传统的基于土地利用/覆被的人口数据空间化方法进行人口空间化的过程中,并不是尺度越精细所能表达的信息越细致、完整,400m是一个人口尺度变化上的特征点,所反映的人口分布信息最细致且完整性好。由此可得,在进行山东省人口空间化的过程中,400m是一个比较适宜的尺度。
Grid size suitability of population spatial distribution in Shandong Province based on landscape ecology [J].https://doi.org/10.7702/dlydlxxkx20140120 URL [本文引用: 1] 摘要
以山东省为研究区,在100m、200m、300m、400m、500m、600m、700m、800m、900m、1km 10个格网尺度人口格网数据的基础上,引入景观生态学的相关指数和方法,探索不同格网尺度表达人口空间分布的适宜性。结果表明:在用传统的基于土地利用/覆被的人口数据空间化方法进行人口空间化的过程中,并不是尺度越精细所能表达的信息越细致、完整,400m是一个人口尺度变化上的特征点,所反映的人口分布信息最细致且完整性好。由此可得,在进行山东省人口空间化的过程中,400m是一个比较适宜的尺度。
|
| [15] |
基于GIS的青藏高原人口统计数据空间化 [J].https://doi.org/10.3321/j.issn:0375-5444.2003.01.004 URL Magsci [本文引用: 1] 摘要
<p>根据2000年第5次全国人口普查数据分析,西藏、青海2省区各市县平均人口密度与海拔高度、土地利用、主要道路有较强的相关关系,河流水系对居民点分布的影响较为明显,而居民点是人口分布的重要指示因子。以GIS软件为工具,通过较为客观的方式赋予各影响因子人口分布影响权重,运用多源数据融合技术进行了人口统计数据的空间化。结果显示,通过数据融合产生的人口密度与各市县实际人口密度的相关系数大于0.80,与试验区各乡镇的实际人口密度的相关系数大于0.75。最终生成的栅格人口密度数据既与各市县统计型人口数据保持一致,又反映了各市县内部人口分布的空间变化。</p>
GIS based spatialization of population census data in Qinghai-Tibet Plateau [J].https://doi.org/10.3321/j.issn:0375-5444.2003.01.004 URL Magsci [本文引用: 1] 摘要
<p>根据2000年第5次全国人口普查数据分析,西藏、青海2省区各市县平均人口密度与海拔高度、土地利用、主要道路有较强的相关关系,河流水系对居民点分布的影响较为明显,而居民点是人口分布的重要指示因子。以GIS软件为工具,通过较为客观的方式赋予各影响因子人口分布影响权重,运用多源数据融合技术进行了人口统计数据的空间化。结果显示,通过数据融合产生的人口密度与各市县实际人口密度的相关系数大于0.80,与试验区各乡镇的实际人口密度的相关系数大于0.75。最终生成的栅格人口密度数据既与各市县统计型人口数据保持一致,又反映了各市县内部人口分布的空间变化。</p>
|
| [16] |
人口统计数据空间化模型综述 [J].https://doi.org/10.3969/j.issn.1673-7105.2010.04.002 URL [本文引用: 1] 摘要
人口统计数据空间化是人口信息与其他资源环境、社会经济等信息进行空间集成的基础.本研究对国内外人口统计数据空间化研究进行总结,归纳了水热条件、地形地貌、土地利用、交通廊道、夜间灯光等不同建模参考因素对人口空间分布的影响,并分析比较了10个主要的人口统计数据空间化模型,进而对当前人口统计数据空间化研究中存在的问题做了总结,并讨论未来的研究方向.综述认为人口统计数据空间化的研究将向数据获取多源化、建模因素综合化、模拟格网精细化、模型应用实用化等方向发展;目前需要改进的问题包括:1)统一的人口数据统计标准;2)人口结构特性相关的空间化,特别是流动人口的空间分布特征识别;3)城市街区尺度的空间化方法研究;4)多源数据与人口动态信息综合中的时相匹配;5)统一的空间化指标量化方法;6)模型参数优化与精度验证方法完善.
Spatialization models of census data: A review [J].https://doi.org/10.3969/j.issn.1673-7105.2010.04.002 URL [本文引用: 1] 摘要
人口统计数据空间化是人口信息与其他资源环境、社会经济等信息进行空间集成的基础.本研究对国内外人口统计数据空间化研究进行总结,归纳了水热条件、地形地貌、土地利用、交通廊道、夜间灯光等不同建模参考因素对人口空间分布的影响,并分析比较了10个主要的人口统计数据空间化模型,进而对当前人口统计数据空间化研究中存在的问题做了总结,并讨论未来的研究方向.综述认为人口统计数据空间化的研究将向数据获取多源化、建模因素综合化、模拟格网精细化、模型应用实用化等方向发展;目前需要改进的问题包括:1)统一的人口数据统计标准;2)人口结构特性相关的空间化,特别是流动人口的空间分布特征识别;3)城市街区尺度的空间化方法研究;4)多源数据与人口动态信息综合中的时相匹配;5)统一的空间化指标量化方法;6)模型参数优化与精度验证方法完善.
|
| [17] |
基于多源数据的太湖流域人口空间化研究[D] .Research on the population specialization basic on mutil-source data in Lake-Tai Basin [D]. |
| [18] |
人口密度的空间降尺度分析与模拟: 以贵州猫跳河流域为例 [J].https://doi.org/10.11820/dlkxjz.2011.05.017 URL Magsci [本文引用: 1] 摘要
人口调查统计以行政区划为基本单元,数据精度不能满足较高分辨率的空间结构分析,也难以在地理综合研究中与自然地理要素数据相匹配。因此,人口密度空间化成为地理学的重要研究方向之一。本文基于贵州省猫跳河流域的乡镇人口数据,采用GIS空间分析技术与统计学方法,分析了人口密度与空间因子的关系;并采用多元回归的方法建立了人口密度数据空间化模型,在GIS平台中实现了人口密度的降尺度空间化模拟。建立的多元回归模型拟合精度达到0.577,且模拟结果与实际人口数据比较线性拟合斜率接近1,效果比较理想。研究结果表明:影响该地区人口密度的主导空间因子为建设用地指数、耕地指数与到道路的平均距离。
Spatial down-scaling analysis and simulation of population density in Maotiaohe Basin, Guizhou Province [J].https://doi.org/10.11820/dlkxjz.2011.05.017 URL Magsci [本文引用: 1] 摘要
人口调查统计以行政区划为基本单元,数据精度不能满足较高分辨率的空间结构分析,也难以在地理综合研究中与自然地理要素数据相匹配。因此,人口密度空间化成为地理学的重要研究方向之一。本文基于贵州省猫跳河流域的乡镇人口数据,采用GIS空间分析技术与统计学方法,分析了人口密度与空间因子的关系;并采用多元回归的方法建立了人口密度数据空间化模型,在GIS平台中实现了人口密度的降尺度空间化模拟。建立的多元回归模型拟合精度达到0.577,且模拟结果与实际人口数据比较线性拟合斜率接近1,效果比较理想。研究结果表明:影响该地区人口密度的主导空间因子为建设用地指数、耕地指数与到道路的平均距离。
|
| [19] |
专家给出银川住宅楼公摊率参考 [N/OL].Zhuanjia geichu Yinchuan zhuzhailou gongtanlv cankao [N/OL]. |
| [20] |
基于空间自相关特征的人口密度格网尺度效应与空间化研究: 以石羊河流域为例 [J].https://doi.org/10.11867/j.issn.1001-8166.2012.12.1363 URL Magsci [本文引用: 1] 摘要
<p>以石羊河流域为例,运用GCAWI法、空间自相关指数以及考虑空间自相关性的多(单)中心指数模型等实现了乡镇单元向格网单元图层的转化、适宜格网大小的确定以及人口密度的空间模拟。结果表明:①石羊河流域人口密度的空间分布差异较大而又相对集中,具有“3点4线3区”的“点—线—区”状空间结构;②不同单元大小的格网图层提高了流域整体的空间自相关性,Moran’s I指数表现出较大的差异性和偶然性;③石羊河流域人口密度空间分布存在明显的正空间自相关,8 000~10 000 m是表现流域人口密度空间分布特征的最优选择范围;④空间自相关性影响下的人口密度空间化多(单)中心模型大大提高传统指数模型的精度,却改变了距离衰减系数的性质和大小,多中心和单中心模型模拟系数的差异主要是由金昌人口密度中心引起的。</p>
Grid scale effect and spatialization of population density based on the characteristic of spatial autocorrelation in Shiyang River Basin [J].https://doi.org/10.11867/j.issn.1001-8166.2012.12.1363 URL Magsci [本文引用: 1] 摘要
<p>以石羊河流域为例,运用GCAWI法、空间自相关指数以及考虑空间自相关性的多(单)中心指数模型等实现了乡镇单元向格网单元图层的转化、适宜格网大小的确定以及人口密度的空间模拟。结果表明:①石羊河流域人口密度的空间分布差异较大而又相对集中,具有“3点4线3区”的“点—线—区”状空间结构;②不同单元大小的格网图层提高了流域整体的空间自相关性,Moran’s I指数表现出较大的差异性和偶然性;③石羊河流域人口密度空间分布存在明显的正空间自相关,8 000~10 000 m是表现流域人口密度空间分布特征的最优选择范围;④空间自相关性影响下的人口密度空间化多(单)中心模型大大提高传统指数模型的精度,却改变了距离衰减系数的性质和大小,多中心和单中心模型模拟系数的差异主要是由金昌人口密度中心引起的。</p>
|
| [21] |
人口数据空间化的处理方法 [J].Method of pixelizing population data [J]. |
| [22] |
一种改进人口数据空间化的方法: 农村居住地重分类 [J].https://doi.org/10.3969/j.issn.1007-6301.2006.03.008 URL Magsci [本文引用: 1] 摘要
<p>人口( 统计) 数据空间化是解决统计数据与自然要素数据融合分析的有效途径。本文在论 述已有人口空间化方法的基础上, 认为遥感影像得到的居民地数据是表达人口分布的最好指标。 为了使居民地数据更好地应用于人口空间化的研究, 论文在分析各种与人口居住密度相关指标 的基础上, 确定了用农村居民地面积所占百分比对农村居民地进行重新分级, 然后应用于人口空 间化的计算。结果检验表明, 人口空间分布数据的误差从分级前的17.4%降到分级后的12%, 尤 其是误差高于30%的乡镇个数从8 个减少到1 个, 该方法有效地提高了人口空间数据的精度。</p>
An enhanced method for spatial distributing census data: Reclassifying of rural residential [J].https://doi.org/10.3969/j.issn.1007-6301.2006.03.008 URL Magsci [本文引用: 1] 摘要
<p>人口( 统计) 数据空间化是解决统计数据与自然要素数据融合分析的有效途径。本文在论 述已有人口空间化方法的基础上, 认为遥感影像得到的居民地数据是表达人口分布的最好指标。 为了使居民地数据更好地应用于人口空间化的研究, 论文在分析各种与人口居住密度相关指标 的基础上, 确定了用农村居民地面积所占百分比对农村居民地进行重新分级, 然后应用于人口空 间化的计算。结果检验表明, 人口空间分布数据的误差从分级前的17.4%降到分级后的12%, 尤 其是误差高于30%的乡镇个数从8 个减少到1 个, 该方法有效地提高了人口空间数据的精度。</p>
|
| [23] |
乡镇级人口统计数据空间化的格网尺度效应分析: 以义乌市为例 [J].
格网尺度效应是统计型人口数据空间化研究的基础性问题之一。针对资源环境研究领域和全球变化区域模型对各种尺度的空间型人口数据的需求,人们对人口数据空间化进行了大量研究。综观现有研究成果,缺乏针对具体应用需求的数据源选择方法和对数据产品适宜性的分析。因此,数据在实际应用中,特别是县市、二、三级流域等尺度上的应用中,存在较多的不确定性。本文重点研究人口数据空间化的格网尺度效应分析方法。以浙江省义乌市为例,利用CBERS、IRS-P5卫星影像,提取了研究区土地利用信息;在地理信息系统技术支持下,对乡镇统计人口进行空间化建模,生成20m至1km系列的格网人口数据;通过比较不同格网人口与乡镇统计人口的误差,分析人口数据空间化的格网尺度效应。分析结果表明,采用CBERS数据源进行人口数据空间化,其数据产品即格网人口的适宜尺度是200m,抽样精度为76%;采用P5数据源进行人口数据空间化,其格网人口的适宜尺度是100m,抽样精度为84%。
The grid scale effect analysis on town leveled population statistical data spatialization [J].
格网尺度效应是统计型人口数据空间化研究的基础性问题之一。针对资源环境研究领域和全球变化区域模型对各种尺度的空间型人口数据的需求,人们对人口数据空间化进行了大量研究。综观现有研究成果,缺乏针对具体应用需求的数据源选择方法和对数据产品适宜性的分析。因此,数据在实际应用中,特别是县市、二、三级流域等尺度上的应用中,存在较多的不确定性。本文重点研究人口数据空间化的格网尺度效应分析方法。以浙江省义乌市为例,利用CBERS、IRS-P5卫星影像,提取了研究区土地利用信息;在地理信息系统技术支持下,对乡镇统计人口进行空间化建模,生成20m至1km系列的格网人口数据;通过比较不同格网人口与乡镇统计人口的误差,分析人口数据空间化的格网尺度效应。分析结果表明,采用CBERS数据源进行人口数据空间化,其数据产品即格网人口的适宜尺度是200m,抽样精度为76%;采用P5数据源进行人口数据空间化,其格网人口的适宜尺度是100m,抽样精度为84%。
|
| [24] |
套内面积售房对买房的影响 [EB/OL].Taonei mianji shoufang dui maifang de yingxiang [EB/OL]. |
| [25] |
基于夜间灯光数据的中国人口密度模拟 [J].https://doi.org/10.3321/j.issn:0375-5444.2005.02.010 URL Magsci [本文引用: 1] 摘要
<p>人口密度网格化比人口密度行政单元化更接近人口的实际分布,而且是实现人口数据与其他社会经济统计数据、资源数据、环境数据复合,提高人口、资源、环境综合管理能力的重要途径之一。选用专门针对亚洲地区开发的DMSP/OLS非辐射定标夜间灯光平均强度遥感数据模拟了中国的人口密度:基于灯光强度信息模拟了灯光区内部的人口密度,基于人口—距离衰减规律和电场叠加理论模拟了灯光区外部的人口密度,是应用DMSP/OLS夜间灯光数据模拟人口密度研究的拓展和深入,研究结果与其他研究基本一致,但所需数据量较少,更适合于大尺度人口密度的快速估算,为决策提供参考依据。结果表明,DMSP/OLS夜间灯光强度数据具有实现人口以及其他社会经济数据空间网格化的巨大潜力。</p>
Modeling population density of China in 1998 based on DMSP/OLS nighttime light image [J].https://doi.org/10.3321/j.issn:0375-5444.2005.02.010 URL Magsci [本文引用: 1] 摘要
<p>人口密度网格化比人口密度行政单元化更接近人口的实际分布,而且是实现人口数据与其他社会经济统计数据、资源数据、环境数据复合,提高人口、资源、环境综合管理能力的重要途径之一。选用专门针对亚洲地区开发的DMSP/OLS非辐射定标夜间灯光平均强度遥感数据模拟了中国的人口密度:基于灯光强度信息模拟了灯光区内部的人口密度,基于人口—距离衰减规律和电场叠加理论模拟了灯光区外部的人口密度,是应用DMSP/OLS夜间灯光数据模拟人口密度研究的拓展和深入,研究结果与其他研究基本一致,但所需数据量较少,更适合于大尺度人口密度的快速估算,为决策提供参考依据。结果表明,DMSP/OLS夜间灯光强度数据具有实现人口以及其他社会经济数据空间网格化的巨大潜力。</p>
|
| [26] |
基于多智能体模型与建筑物信息的高空间分辨率人口分布模拟 [J].https://doi.org/10.11821/dlyj201403011 URL Magsci [本文引用: 2] 摘要
自上而下的人口分布模拟模型自动化程度较低,难以分析人口分布成因,且因精细尺度的人口样本较难获取而不太适用于高空间分辨率人口分布模拟。提出了一种基于多智能体模型和建筑物信息的高空间分辨率人口分布模拟模型。首先利用建筑物三维分布数据提取住宅建筑,构建智能体人口分布模拟模型的环境;然后基于统计、调研数据定义智能体属性,确定智能体居住选择行为规则;最后以泰日社区为例进行了居住人口分布仿真模拟。研究结果表明,基于建筑物信息的人口分布多智能体模型,可以获取每栋建筑物上的人口,改进了当前高分辨率人口模拟主要只模拟小区或者居委会人口的不足;多智能体模型具有较高的自动化程度,不仅能获得较好的模拟结果,而且可在一定程度上从微观机理解释宏观居住分布模式,是对传统统计模型的有益补充。
High spatial resolution population distribution simulation based on building information and multi-agent [J].https://doi.org/10.11821/dlyj201403011 URL Magsci [本文引用: 2] 摘要
自上而下的人口分布模拟模型自动化程度较低,难以分析人口分布成因,且因精细尺度的人口样本较难获取而不太适用于高空间分辨率人口分布模拟。提出了一种基于多智能体模型和建筑物信息的高空间分辨率人口分布模拟模型。首先利用建筑物三维分布数据提取住宅建筑,构建智能体人口分布模拟模型的环境;然后基于统计、调研数据定义智能体属性,确定智能体居住选择行为规则;最后以泰日社区为例进行了居住人口分布仿真模拟。研究结果表明,基于建筑物信息的人口分布多智能体模型,可以获取每栋建筑物上的人口,改进了当前高分辨率人口模拟主要只模拟小区或者居委会人口的不足;多智能体模型具有较高的自动化程度,不仅能获得较好的模拟结果,而且可在一定程度上从微观机理解释宏观居住分布模式,是对传统统计模型的有益补充。
|
| [27] |
LandScan USA: A high-resolution geospatial and temporal modeling approach for population distribution and dynamics [J].https://doi.org/10.1007/s10708-007-9105-9 URL [本文引用: 1] 摘要
High-resolution population distribution data are critical for successfully addressing important issues ranging from socio-environmental research to public health to homeland security, since scientific analyses, operational activities, and policy decisions are significantly influenced by the number of impacted people. Dasymetric modeling has been a well-recognized approach for spatial decomposition of census data to increase the spatial resolution of population distribution. However, enhancing the temporal resolution of population distribution poses a greater challenge. In this paper, we discuss the development of LandScan USA, a multi-dimensional dasymetric modeling approach, which has allowed the creation of a very high-resolution population distribution data both over space and time. At a spatial resolution of 3聽arc seconds (鈭90聽m), the initial LandScan USA database contains both a nighttime residential as well as a baseline daytime population distribution that incorporates movement of workers and students. Challenging research issues of disparate and misaligned spatial data and modeling to develop a database at a national scale, as well as model verification and validation approaches are illustrated and discussed. Initial analyses indicate a high degree of locational accuracy for LandScan USA distribution model and data. High-resolution population data such as LandScan USA, which describes both distribution and dynamics of human population, clearly has the potential to profoundly impact multiple domain applications of national and global priority.
|
| [28] |
High resolution dasymetric model of U.S demographics with application to spatial distribution of racial diversity [J].https://doi.org/10.1016/j.apgeog.2014.07.003 URL Magsci [本文引用: 1] 摘要
Population and demographic data at high spatial resolution is a valuable resource for supporting planning and management decisions as well as an important input to socio-economic academic studies. Dasymetric modeling has been a standard technique to disaggregate census-aggregated units into raster-based data of higher spatial resolution. Although utility of dasymetric mapping has been demonstrated on local and regional scales, few high resolution large-scale models exist due to their high computational cost. In particular, no publicly available high resolution dasymetric model of population distribution over the entire United States is presently available. In this paper we introduce a 3 '' (similar to 90 m) resolution dasymetric model of demographics over the entire conterminous United States. The major innovation is to disaggregate already existing 30 '' (similar to 1 km) and 7.5 '' (similar to 250 m) SEDAC (Socioeconomic Data and Applications Center) Census 2000 grids instead of the original census block-level data. National Land Cover Dataset (NLCD) 2001 is used as ancillary information. This allows for rapid development of a U.S.-wide model for distribution of population and sixteen other demographic variables. The new model is demonstrated to markedly improve spatial accuracy of SEDAC model. To underscore importance of high spatial resolution demographic information other than total population count we demonstrate how maps of several population characteristics can be fused into a "product" map that illustrates complex social issues. Specifically, we introduce a "diversity" categorical map that informs (at nominal 3 '' resolution) about spatial distribution of racial diversity, dominant race, and population density simultaneously. Diversity map is compared to a similar map based on census tracts. High resolution raster map allows study of race-diversity phenomenon on smaller scale, and, outside of major metropolitan areas, revels existence of patterns that cannot be deduced from a tract-based map. The new high resolution population and diversity maps can be explored online using our GeoWeb application DataEye available at http://siLuc.edui. Both datasets can be also downloaded from the same website. (C) 2014 Elsevier Ltd. All rights reserved.
|
| [29] |
Evaluation of small-area population estimation using LiDAR, Landsat TM and parcel data [J]. |
| [30] |
A population density grid of the European Union [J].https://doi.org/10.1007/s11111-010-0108-y URL Magsci [本文引用: 1] 摘要
This paper describes four methods used to produce dasymetric population density grids combining population data per commune with CORINE Land Cover, a map available for all countries of the European Union. An accuracy assessment has been carried out for five countries for which a very reliable 1-km population density grid exists; the improvement, compared with the choropleth map per commune, ranges between 20% for the weakest result in Finland and 62% for the best result in the Netherlands. The best results are obtained with a method using logit regression to integrate information from the point survey LUCAS (Land Use/Cover Area frame Survey); however, performance differences between methods are moderate. The dasymetric grid is distributed free of charge by the European Environment Agency, for non-commercial use.
|
| [31] |
Spatiotemporal patterns of population in mainland China, 1990 to 2010 [J].URL PMID: 26881418 [本文引用: 1] 摘要
According to UN forecasts, global population will increase to over 8 billion by 2025, with much of this anticipated population growth expected in urban areas. In China, the scale of urbanization has, and continues to be, unprecedented in terms of magnitude and rate of change. Since the late 1970s, the percentage of Chinese living in urban areas increased from ~18% to over 50%. To quantify these patterns spatially we use time-invariant or temporally-explicit data, including census data for 1990, 2000, and 2010 in an ensemble prediction model. Resulting multi-temporal, gridded population datasets are unique in terms of granularity and extent, providing fine-scale (~100?m) patterns of population distribution for mainland China. For consistency purposes, the Tibet Autonomous Region, Taiwan, and the islands in the South China Sea were excluded. The statistical model and considerations for temporally comparable maps are described, along with the resulting datasets. Final, mainland China population maps for 1990, 2000, and 2010 are freely available as products from the WorldPop Project website and the WorldPop Dataverse Repository.
|
| [32] |
Dasymetric modeling: A hybrid approach using land cover and tax parcel data for mapping population in Alachua County, Florida [J]. |
| [33] |
Human population distribution modelling at regional level using very high resolution satellite imagery [J].https://doi.org/10.1016/j.apgeog.2013.03.002 URL Magsci [本文引用: 1] 摘要
Modelling the distribution of human population based on satellite-derived information has become an important field of research, providing valuable input e.g. for human impact assessments related to the management of threatened ecosystems. However, few regional-scale studies have been conducted in developing countries, where detailed land cover data is usually absent, and the potential of very high resolution (VHR) satellite imagery in this context has not been explored yet. This study uses results obtained through object-based image analysis (OBIA) of QuickBird imagery for a subset of a highly populated rural area in western Kenya. Functions are established that approximate frequency distributions of QuickBird-derived locations of houses in relation to five factors. These factors are known to impact settlement patterns and data is available for the entire study area. Based on an overall probability coefficient (weight) calculated from the single functions, human population is redistributed at the smallest administrative level available (version A). In addition, the problem of artefacts remaining at administrative boundaries is addressed by combining the approach with the pycnophylactic smoothing algorithm (Tobler, 1979) (version B). The results show distinct patterns of population distribution, with particular influence of rivers/streams and slope, while version B in addition is free of boundary artefacts. Despite some limitations compared to models based on detailed land cover data (e.g. the ability of capturing abrupt changes in population density), a visual and numerical evaluation of the results shows that using houses as classified from VHR imagery for a study area subset works well for redistributing human population at the regional level. This approach might be suitable to be applied also in other regions of e.g. sub-Saharan Africa. (C) 2013 Elsevier Ltd. All rights reserved.
|
| [34] |
A GIS approach to estimation of building population for micro-spatial analysis [J].https://doi.org/10.1111/j.1467-9671.2009.01171.x URL [本文引用: 1] 摘要
Population data used in GIS analyses is generally assumed to be homogeneous and planar (i.e. census tracts, townships or prefectures) due to the public unavailability of building population data. However, information on building population is required for micro-spatial analysis for improved disaster management and emergency preparedness, public facility management for urban planning, consumer and retail market analysis, environment and public health programs and other demographic studies. This article discusses a GIS approach using the Areametric and Volumetric methods for estimating building population based on census tracts and building footprint datasets. The estimated results were evaluated using actual building population data by visual, statistical and spatial means, and validated for use in micro-spatial analysis. We have also implemented a standalone GIS tool (known as ‘PopShape GIS’) for generating new building footprint with population attribute information based on user-defined criteria.
|
| [35] |
Generating surface models of population using dasymetric mapping [J].https://doi.org/10.1111/0033-0124.10042 URL [本文引用: 1] 摘要
Aggregated demographic datasets are associated with analytical and cartographic problems due to the arbitrary nature of areal unit partitioning. This article describes a methodology for generating a surface-based representation of population that mitigates these problems. This methodology uses dasymetric mapping and incorporates areal weighting and empirical sampling techniques to assess the relationship between categorical ancillary data and population distribution. As a demonstration, a 100-meter-resolution population surface is generated from U.S. Census block group data for the southeast Pennsylvania region. Remote-sensing-derived urban land-cover data serve as ancillary data in the dasymetric mapping.
|
| [36] |
Improving large area population mapping using geotweet densities [J].
Many different methods are used to disaggregate census data and predict population densities to construct finer scale, gridded population data sets. These methods often involve a range of high resolution geospatial covariate datasets on aspects such as urban areas, infrastructure, land cover and topography; such covariates, however, are not directly indicative of the presence of people. Here we tested the potential of geo-located tweets from the social media application, Twitter, as a covariate in the production of population maps. The density of geo-located tweets in 1x1 km grid cells over a 2-month period across Indonesia, a country with one of the highest Twitter usage rates in the world, was input as a covariate into a previously published random forests-based census disaggregation method. Comparison of internal measures of accuracy and external assessments between models built with and without the geotweets showed that increases in population mapping accuracy could be obtained using the geotweet densities as a covariate layer. The work highlights the potential for such social media-derived data in improving our understanding of population distributions and offers promise for more dynamic mapping with such data being continually produced and freely available
|
| [37] |
Assessing fine-spatial-resolution remote sensing for small-area population estimation [J].https://doi.org/10.1080/01431161.2010.496800 URL [本文引用: 1] 摘要
Not Available
|
| [38] |
Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data [J].URL PMID: 25689585 [本文引用: 1] 摘要
High resolution, contemporary data on human population distributions are vital for measuring impacts of population growth, monitoring human-environment interactions and for planning and policy development. Many methods are used to disaggregate census data and predict population densities for finer scale, gridded population data sets. We present a new semi-automated dasymetric modeling approach that incorporates detailed census and ancillary data in a flexible, "Random Forest" estimation technique. We outline the combination of widely available, remotely-sensed and geospatial data that contribute to the modeled dasymetric weights and then use the Random Forest model to generate a gridded prediction of population density at ~100 m spatial resolution. This prediction layer is then used as the weighting surface to perform dasymetric redistribution of the census counts at a country level. As a case study we compare the new algorithm and its products for three countries (Vietnam, Cambodia, and Kenya) with other common gridded population data production methodologies. We discuss the advantages of the new method and increases over the accuracy and flexibility of those previous approaches. Finally, we outline how this algorithm will be extended to provide freely-available gridded population data sets for Africa, Asia and Latin America.
|
| [39] |
Building population mapping with aerial imagery and GIS data [J].https://doi.org/10.1016/j.jag.2011.06.004 URL Magsci [本文引用: 1] 摘要
Geospatial distribution of population at a scale of individual buildings is needed for analysis of people's interaction with their local socio-economic and physical environments. High resolution aerial images are capable of capturing urban complexities and considered as a potential source for mapping urban features at this fine scale. This paper studies population mapping for individual buildings by using aerial imagery and other geographic data. Building footprints and heights are first determined from aerial images, digital terrain and surface models. City zoning maps allow the classification of the buildings as residential and non-residential. The use of additional ancillary geographic data further filters residential utility buildings out of the residential area and identifies houses and apartments. In the final step, census block population, which is publicly available from the U.S. Census, is disaggregated and mapped to individual residential buildings. This paper proposes a modified building population mapping model that takes into account the effects of different types of residential buildings. Detailed steps are described that lead to the identification of residential buildings from imagery and other GIS data layers. Estimated building populations are evaluated per census block with reference to the known census records. This paper presents and evaluates the results of building population mapping in areas of West Lafayette, Lafayette, and Wea Township, all in the state of Indiana, USA. (C) 2011 Published by Elsevier B.V.
|
| [40] |
Gridded population distribution map for the Hebei Province of China [J].
Mapping the distribution of populations has become an important issue in geographical and relative researchers. Combining population and spatial data allows for socio-graphic information to be visualized, in order to evaluate the total numbers of people at risk of environmental health hazards, who have died in natural disasters etc. Therefore, spatial distribution of population data is an effective way to integrate statistical and spatial data. This paper presents a multi-factor data fusion modeling method for population estimation, which is based on spatial relationships that determine the factors affecting population distribution. The factors that have a strong correlation with population distribution in the Hebei Province were extracted using Geographic Information Systems (GIS). Their standardized weight coefficients were factored as weight coefficients of population distribution in a given spatial unit. The unit (1 km x 1 km) population database was established, allowing for the computation of the relevant population data error. The accuracy of the map was then assessed by comparing predicted population data with that collected from the local government. The results show that the population correlated with geographical factors. The population of the Hebei Province was distributed heterogeneously, increasing from the northwest to southeast. There was relatively low population density in the Taihang Mountains in the west and in the Yanshan Mountains in the northeast, with less than 100 people per square kilometer. The population density in the central Hebei Province was higher, with about 2,000 people per square kilometer, which was higher and denser than that in Handan, Shijiazhuang, Langfang, and Tangshan. These findings may be important for data mining (DM), Decision-making Support Systems (DSS), and regional sustainable development.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}